 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital twins to alleviate the need for real field data in vision-based vehicle speed detection systems
Jul 11, 2024



Accurate vision-based speed estimation is much more cost-effective than traditional methods based on radar or LiDAR. However, it is also challenging due to the limitations of perspective projection on a discrete sensor, as well as the high sensitivity to calibration, lighting and weather conditions. Interestingly, deep learning approaches (which dominate the field of computer vision) are very limited in this context due to the lack of available data. Indeed, obtaining video sequences of real road traffic with accurate speed values associated with each vehicle is very complex and costly, and the number of available datasets is very limited. Recently, some approaches are focusing on the use of synthetic data. However, it is still unclear how models trained on synthetic data can be effectively applied to real world conditions. In this work, we propose the use of digital-twins using CARLA simulator to generate a large dataset representative of a specific real-world camera. The synthetic dataset contains a large variability of vehicle types, colours, speeds, lighting and weather conditions. A 3D CNN model is trained on the digital twin and tested on the real sequences. Unlike previous approaches that generate multi-camera sequences, we found that the gap between the the real and the virtual conditions is a key factor in obtaining low speed estimation errors. Even with a preliminary approach, the mean absolute error obtained remains below 3km/h.
Pedestrian and Passenger Interaction with Autonomous Vehicles: Field Study in a Crosswalk Scenario
Dec 11, 2023This study presents the outcomes of empirical investigations pertaining to human-vehicle interactions involving an autonomous vehicle equipped with both internal and external Human Machine Interfaces (HMIs) within a crosswalk scenario. The internal and external HMIs were integrated with implicit communication techniques, incorporating a combination of gentle and aggressive braking maneuvers within the crosswalk. Data were collected through a combination of questionnaires and quantifiable metrics, including pedestrian decision to cross related to the vehicle distance and speed. The questionnaire responses reveal that pedestrians experience enhanced safety perceptions when the external HMI and gentle braking maneuvers are used in tandem. In contrast, the measured variables demonstrate that the external HMI proves effective when complemented by the gentle braking maneuver. Furthermore, the questionnaire results highlight that the internal HMI enhances passenger confidence only when paired with the aggressive braking maneuver.
Attribute Annotation and Bias Evaluation in Visual Datasets for Autonomous Driving
Dec 11, 2023This paper addresses the often overlooked issue of fairness in the autonomous driving domain, particularly in vision-based perception and prediction systems, which play a pivotal role in the overall functioning of Autonomous Vehicles (AVs). We focus our analysis on biases present in some of the most commonly used visual datasets for training person and vehicle detection systems. We introduce an annotation methodology and a specialised annotation tool, both designed to annotate protected attributes of agents in visual datasets. We validate our methodology through an inter-rater agreement analysis and provide the distribution of attributes across all datasets. These include annotations for the attributes age, sex, skin tone, group, and means of transport for more than 90K people, as well as vehicle type, colour, and car type for over 50K vehicles. Generally, diversity is very low for most attributes, with some groups, such as children, wheelchair users, or personal mobility vehicle users, being extremely underrepresented in the analysed datasets. The study contributes significantly to efforts to consider fairness in the evaluation of perception and prediction systems for AVs. This paper follows reproducibility principles. The annotation tool, scripts and the annotated attributes can be accessed publicly at https://github.com/ec-jrc/humaint_annotator.
Realistic pedestrian behaviour in the CARLA simulator using VR and mocap
Sep 08, 2023Simulations are gaining increasingly significance in the field of autonomous driving due to the demand for rapid prototyping and extensive testing. Employing physics-based simulation brings several benefits at an affordable cost, while mitigating potential risks to prototypes, drivers, and vulnerable road users. However, there exit two primary limitations. Firstly, the reality gap which refers to the disparity between reality and simulation and prevents the simulated autonomous driving systems from having the same performance in the real world. Secondly, the lack of empirical understanding regarding the behavior of real agents, such as backup drivers or passengers, as well as other road users such as vehicles, pedestrians, or cyclists. Agent simulation is commonly implemented through deterministic or randomized probabilistic pre-programmed models, or generated from real-world data; but it fails to accurately represent the behaviors adopted by real agents while interacting within a specific simulated scenario. This paper extends the description of our proposed framework to enable real-time interaction between real agents and simulated environments, by means immersive virtual reality and human motion capture systems within the CARLA simulator for autonomous driving. We have designed a set of usability examples that allow the analysis of the interactions between real pedestrians and simulated autonomous vehicles and we provide a first measure of the user's sensation of presence in the virtual environment.
Digital twin in virtual reality for human-vehicle interactions in the context of autonomous driving
Mar 20, 2023The traditional simulation methods present some limitations, such as the reality gap between simulated experiences and real-world performance. In the field of autonomous driving research, we propose the handling of an immersive virtual reality system for pedestrians to include in simulations real behaviors of agents that interact with the simulated environment in real time, to improve the quality of the virtual-world data and reduce the gap. In this paper we employ a digital twin to replicate a study on communication interfaces between autonomous vehicles and pedestrians, generating an equivalent virtual scenario to compare the results and establish qualitative and quantitative measurements of the discrepancy. The goal is to evaluate the effectiveness and acceptability of implicit and explicit forms of communication in both scenarios and to verify that the behavior carried out by the pedestrian inside the simulator through a virtual reality interface is directly comparable with their role performed in a real traffic situation.
Towards Explainable Motion Prediction using Heterogeneous Graph Representations
Dec 07, 2022Motion prediction systems aim to capture the future behavior of traffic scenarios enabling autonomous vehicles to perform safe and efficient planning. The evolution of these scenarios is highly uncertain and depends on the interactions of agents with static and dynamic objects in the scene. GNN-based approaches have recently gained attention as they are well suited to naturally model these interactions. However, one of the main challenges that remains unexplored is how to address the complexity and opacity of these models in order to deal with the transparency requirements for autonomous driving systems, which includes aspects such as interpretability and explainability. In this work, we aim to improve the explainability of motion prediction systems by using different approaches. First, we propose a new Explainable Heterogeneous Graph-based Policy (XHGP) model based on an heterograph representation of the traffic scene and lane-graph traversals, which learns interaction behaviors using object-level and type-level attention. This learned attention provides information about the most important agents and interactions in the scene. Second, we explore this same idea with the explanations provided by GNNExplainer. Third, we apply counterfactual reasoning to provide explanations of selected individual scenarios by exploring the sensitivity of the trained model to changes made to the input data, i.e., masking some elements of the scene, modifying trajectories, and adding or removing dynamic agents. The explainability analysis provided in this paper is a first step towards more transparent and reliable motion prediction systems, important from the perspective of the user, developers and regulatory agencies. The code to reproduce this work is publicly available at https://github.com/sancarlim/Explainable-MP/tree/v1.1.
Liability regimes in the age of AI: a use-case driven analysis of the burden of proof
Nov 03, 2022



New emerging technologies powered by Artificial Intelligence (AI) have the potential to disruptively transform our societies for the better. In particular, data-driven learning approaches (i.e., Machine Learning (ML)) have been a true revolution in the advancement of multiple technologies in various application domains. But at the same time there is growing concerns about certain intrinsic characteristics of these methodologies that carry potential risks to both safety and fundamental rights. Although there are mechanisms in the adoption process to minimize these risks (e.g., safety regulations), these do not exclude the possibility of harm occurring, and if this happens, victims should be able to seek compensation. Liability regimes will therefore play a key role in ensuring basic protection for victims using or interacting with these systems. However, the same characteristics that make AI systems inherently risky, such as lack of causality, opacity, unpredictability or their self and continuous learning capabilities, lead to considerable difficulties when it comes to proving causation. This paper presents three case studies, as well as the methodology to reach them, that illustrate these difficulties. Specifically, we address the cases of cleaning robots, delivery drones and robots in education. The outcome of the proposed analysis suggests the need to revise liability regimes to alleviate the burden of proof on victims in cases involving AI technologies.
Towards Trustworthy Multi-Modal Motion Prediction: Evaluation and Interpretability
Oct 28, 2022



Predicting the motion of other road agents enables autonomous vehicles to perform safe and efficient path planning. This task is very complex, as the behaviour of road agents depends on many factors and the number of possible future trajectories can be considerable (multi-modal). Most approaches proposed to address multi-modal motion prediction are based on complex machine learning systems that have limited interpretability. Moreover, the metrics used in current benchmarks do not evaluate all aspects of the problem, such as the diversity and admissibility of the output. In this work, we aim to advance towards the design of trustworthy motion prediction systems, based on some of the requirements for the design of Trustworthy Artificial Intelligence. We focus on evaluation criteria, robustness, and interpretability of outputs. First, we comprehensively analyse the evaluation metrics, identify the main gaps of current benchmarks, and propose a new holistic evaluation framework. In addition, we formulate a method for the assessment of spatial and temporal robustness by simulating noise in the perception system. We propose an intent prediction layer that can be attached to multi-modal motion prediction models to enhance the interpretability of the outputs and generate more balanced results in the proposed evaluation framework. Finally, the interpretability of the outputs is assessed by means of a survey that explores different elements in the visualization of the multi-modal trajectories and intentions.
Vehicle Trajectory Prediction on Highways Using Bird Eye View Representations and Deep Learning
Jul 04, 2022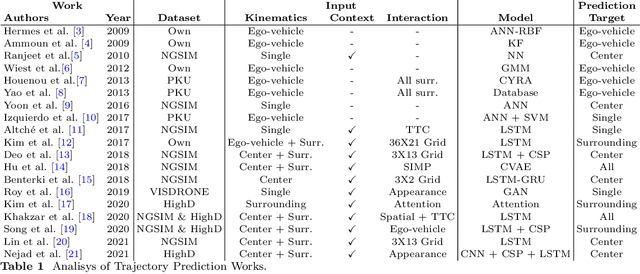
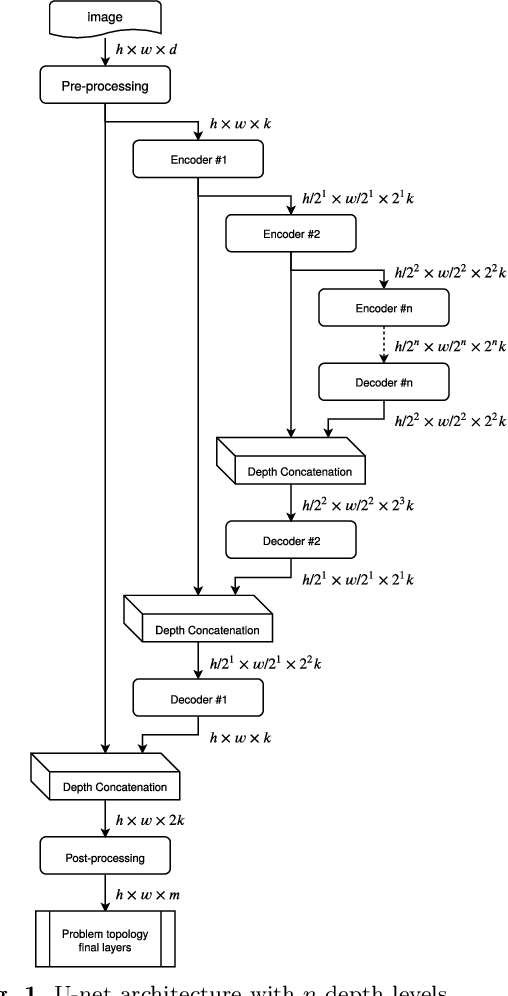


This work presents a novel method for predicting vehicle trajectories in highway scenarios using efficient bird's eye view representations and convolutional neural networks. Vehicle positions, motion histories, road configuration, and vehicle interactions are easily included in the prediction model using basic visual representations. The U-net model has been selected as the prediction kernel to generate future visual representations of the scene using an image-to-image regression approach. A method has been implemented to extract vehicle positions from the generated graphical representations to achieve subpixel resolution. The method has been trained and evaluated using the PREVENTION dataset, an on-board sensor dataset. Different network configurations and scene representations have been evaluated. This study found that U-net with 6 depth levels using a linear terminal layer and a Gaussian representation of the vehicles is the best performing configuration. The use of lane markings was found to produce no improvement in prediction performance. The average prediction error is 0.47 and 0.38 meters and the final prediction error is 0.76 and 0.53 meters for longitudinal and lateral coordinates, respectively, for a predicted trajectory length of 2.0 seconds. The prediction error is up to 50% lower compared to the baseline method.
Insertion of real agents behaviors in CARLA autonomous driving simulator
Jun 01, 2022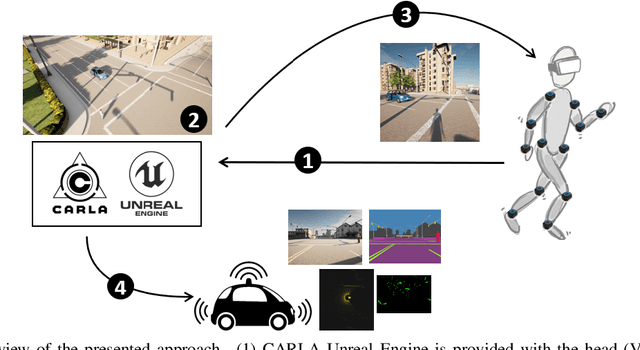
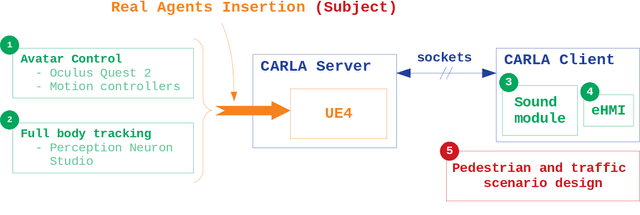

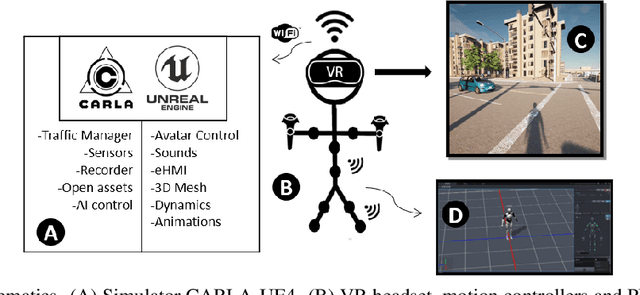
The role of simulation in autonomous driving is becoming increasingly important due to the need for rapid prototyping and extensive testing. The use of physics-based simulation involves multiple benefits and advantages at a reasonable cost while eliminating risks to prototypes, drivers and vulnerable road users. However, there are two main limitations. First, the well-known reality gap which refers to the discrepancy between reality and simulation that prevents simulated autonomous driving experience from enabling effective real-world performance. Second, the lack of empirical knowledge about the behavior of real agents, including backup drivers or passengers and other road users such as vehicles, pedestrians or cyclists. Agent simulation is usually pre-programmed deterministically, randomized probabilistically or generated based on real data, but it does not represent behaviors from real agents interacting with the specific simulated scenario. In this paper we present a preliminary framework to enable real-time interaction between real agents and the simulated environment (including autonomous vehicles) and generate synthetic sequences from simulated sensor data from multiple views that can be used for training predictive systems that rely on behavioral models. Our approach integrates immersive virtual reality and human motion capture systems with the CARLA simulator for autonomous driving. We describe the proposed hardware and software architecture, and discuss about the so-called behavioural gap or presence. We present preliminary, but promising, results that support the potential of this methodology and discuss about future steps.