 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital twins to alleviate the need for real field data in vision-based vehicle speed detection systems
Jul 11, 2024



Accurate vision-based speed estimation is much more cost-effective than traditional methods based on radar or LiDAR. However, it is also challenging due to the limitations of perspective projection on a discrete sensor, as well as the high sensitivity to calibration, lighting and weather conditions. Interestingly, deep learning approaches (which dominate the field of computer vision) are very limited in this context due to the lack of available data. Indeed, obtaining video sequences of real road traffic with accurate speed values associated with each vehicle is very complex and costly, and the number of available datasets is very limited. Recently, some approaches are focusing on the use of synthetic data. However, it is still unclear how models trained on synthetic data can be effectively applied to real world conditions. In this work, we propose the use of digital-twins using CARLA simulator to generate a large dataset representative of a specific real-world camera. The synthetic dataset contains a large variability of vehicle types, colours, speeds, lighting and weather conditions. A 3D CNN model is trained on the digital twin and tested on the real sequences. Unlike previous approaches that generate multi-camera sequences, we found that the gap between the the real and the virtual conditions is a key factor in obtaining low speed estimation errors. Even with a preliminary approach, the mean absolute error obtained remains below 3km/h.
Behavioural gap assessment of human-vehicle interaction in real and virtual reality-based scenarios in autonomous driving
Jul 04, 2024In the field of autonomous driving research, the use of immersive virtual reality (VR) techniques is widespread to enable a variety of studies under safe and controlled conditions. However, this methodology is only valid and consistent if the conduct of participants in the simulated setting mirrors their actions in an actual environment. In this paper, we present a first and innovative approach to evaluating what we term the behavioural gap, a concept that captures the disparity in a participant's conduct when engaging in a VR experiment compared to an equivalent real-world situation. To this end, we developed a digital twin of a pre-existed crosswalk and carried out a field experiment (N=18) to investigate pedestrian-autonomous vehicle interaction in both real and simulated driving conditions. In the experiment, the pedestrian attempts to cross the road in the presence of different driving styles and an external Human-Machine Interface (eHMI). By combining survey-based and behavioural analysis methodologies, we develop a quantitative approach to empirically assess the behavioural gap, as a mechanism to validate data obtained from real subjects interacting in a simulated VR-based environment. Results show that participants are more cautious and curious in VR, affecting their speed and decisions, and that VR interfaces significantly influence their actions.
Realistic pedestrian behaviour in the CARLA simulator using VR and mocap
Sep 08, 2023Simulations are gaining increasingly significance in the field of autonomous driving due to the demand for rapid prototyping and extensive testing. Employing physics-based simulation brings several benefits at an affordable cost, while mitigating potential risks to prototypes, drivers, and vulnerable road users. However, there exit two primary limitations. Firstly, the reality gap which refers to the disparity between reality and simulation and prevents the simulated autonomous driving systems from having the same performance in the real world. Secondly, the lack of empirical understanding regarding the behavior of real agents, such as backup drivers or passengers, as well as other road users such as vehicles, pedestrians, or cyclists. Agent simulation is commonly implemented through deterministic or randomized probabilistic pre-programmed models, or generated from real-world data; but it fails to accurately represent the behaviors adopted by real agents while interacting within a specific simulated scenario. This paper extends the description of our proposed framework to enable real-time interaction between real agents and simulated environments, by means immersive virtual reality and human motion capture systems within the CARLA simulator for autonomous driving. We have designed a set of usability examples that allow the analysis of the interactions between real pedestrians and simulated autonomous vehicles and we provide a first measure of the user's sensation of presence in the virtual environment.
Digital twin in virtual reality for human-vehicle interactions in the context of autonomous driving
Mar 20, 2023The traditional simulation methods present some limitations, such as the reality gap between simulated experiences and real-world performance. In the field of autonomous driving research, we propose the handling of an immersive virtual reality system for pedestrians to include in simulations real behaviors of agents that interact with the simulated environment in real time, to improve the quality of the virtual-world data and reduce the gap. In this paper we employ a digital twin to replicate a study on communication interfaces between autonomous vehicles and pedestrians, generating an equivalent virtual scenario to compare the results and establish qualitative and quantitative measurements of the discrepancy. The goal is to evaluate the effectiveness and acceptability of implicit and explicit forms of communication in both scenarios and to verify that the behavior carried out by the pedestrian inside the simulator through a virtual reality interface is directly comparable with their role performed in a real traffic situation.
Vehicle Trajectory Prediction on Highways Using Bird Eye View Representations and Deep Learning
Jul 04, 2022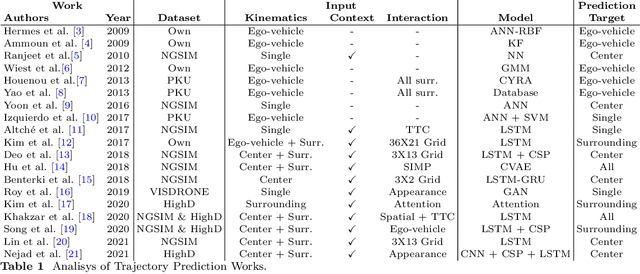
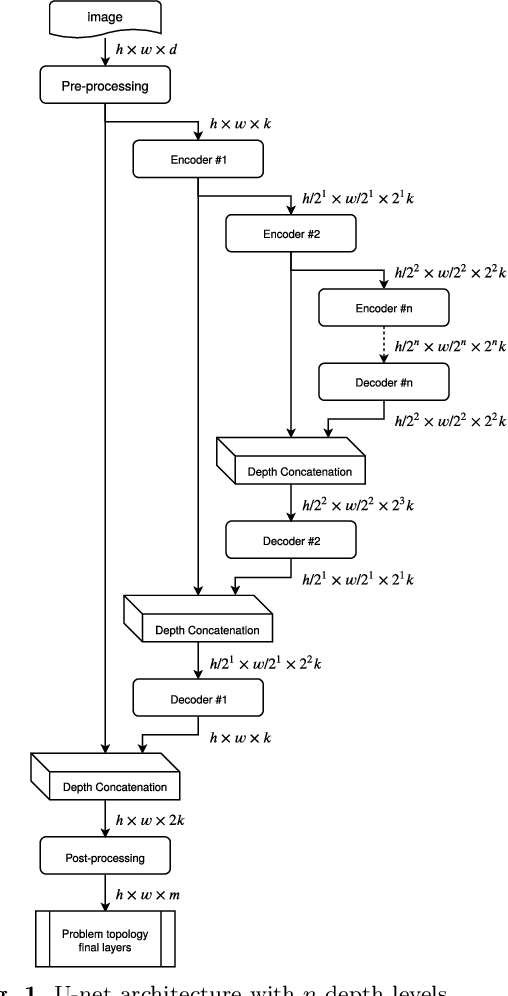


This work presents a novel method for predicting vehicle trajectories in highway scenarios using efficient bird's eye view representations and convolutional neural networks. Vehicle positions, motion histories, road configuration, and vehicle interactions are easily included in the prediction model using basic visual representations. The U-net model has been selected as the prediction kernel to generate future visual representations of the scene using an image-to-image regression approach. A method has been implemented to extract vehicle positions from the generated graphical representations to achieve subpixel resolution. The method has been trained and evaluated using the PREVENTION dataset, an on-board sensor dataset. Different network configurations and scene representations have been evaluated. This study found that U-net with 6 depth levels using a linear terminal layer and a Gaussian representation of the vehicles is the best performing configuration. The use of lane markings was found to produce no improvement in prediction performance. The average prediction error is 0.47 and 0.38 meters and the final prediction error is 0.76 and 0.53 meters for longitudinal and lateral coordinates, respectively, for a predicted trajectory length of 2.0 seconds. The prediction error is up to 50% lower compared to the baseline method.
Towards view-invariant vehicle speed detection from driving simulator images
Jun 01, 2022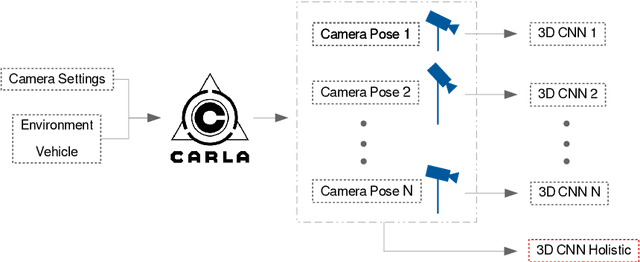
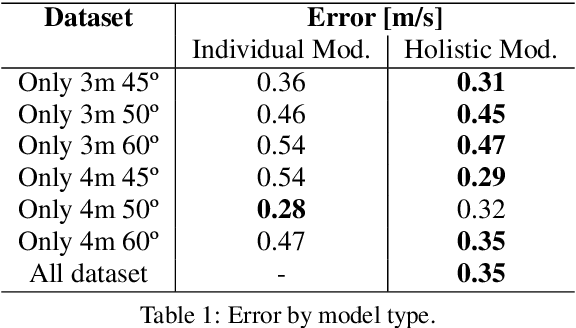
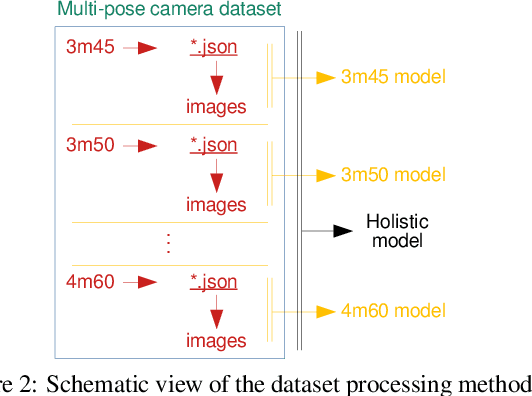

The use of cameras for vehicle speed measurement is much more cost effective compared to other technologies such as inductive loops, radar or laser. However, accurate speed measurement remains a challenge due to the inherent limitations of cameras to provide accurate range estimates. In addition, classical vision-based methods are very sensitive to extrinsic calibration between the camera and the road. In this context, the use of data-driven approaches appears as an interesting alternative. However, data collection requires a complex and costly setup to record videos under real traffic conditions from the camera synchronized with a high-precision speed sensor to generate the ground truth speed values. It has recently been demonstrated that the use of driving simulators (e.g., CARLA) can serve as a robust alternative for generating large synthetic datasets to enable the application of deep learning techniques for vehicle speed estimation for a single camera. In this paper, we study the same problem using multiple cameras in different virtual locations and with different extrinsic parameters. We address the question of whether complex 3D-CNN architectures are capable of implicitly learning view-invariant speeds using a single model, or whether view-specific models are more appropriate. The results are very promising as they show that a single model with data from multiple views reports even better accuracy than camera-specific models, paving the way towards a view-invariant vehicle speed measurement system.
Insertion of real agents behaviors in CARLA autonomous driving simulator
Jun 01, 2022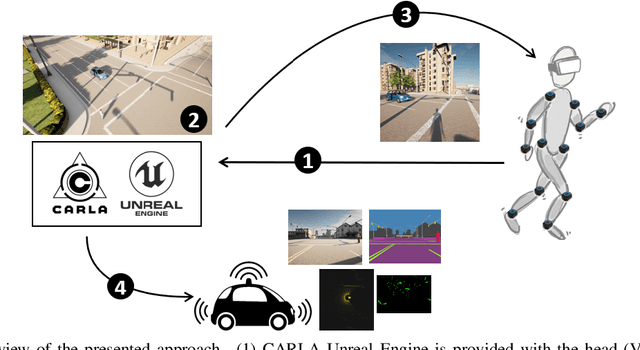
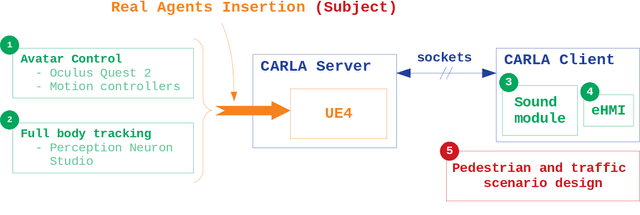

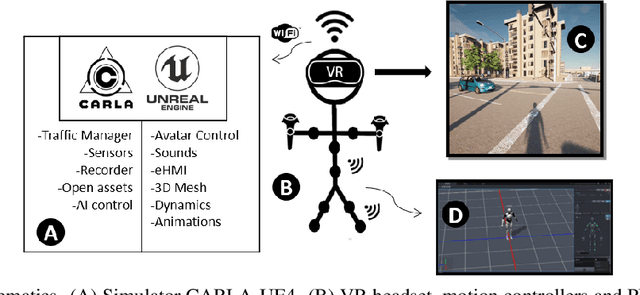
The role of simulation in autonomous driving is becoming increasingly important due to the need for rapid prototyping and extensive testing. The use of physics-based simulation involves multiple benefits and advantages at a reasonable cost while eliminating risks to prototypes, drivers and vulnerable road users. However, there are two main limitations. First, the well-known reality gap which refers to the discrepancy between reality and simulation that prevents simulated autonomous driving experience from enabling effective real-world performance. Second, the lack of empirical knowledge about the behavior of real agents, including backup drivers or passengers and other road users such as vehicles, pedestrians or cyclists. Agent simulation is usually pre-programmed deterministically, randomized probabilistically or generated based on real data, but it does not represent behaviors from real agents interacting with the specific simulated scenario. In this paper we present a preliminary framework to enable real-time interaction between real agents and the simulated environment (including autonomous vehicles) and generate synthetic sequences from simulated sensor data from multiple views that can be used for training predictive systems that rely on behavioral models. Our approach integrates immersive virtual reality and human motion capture systems with the CARLA simulator for autonomous driving. We describe the proposed hardware and software architecture, and discuss about the so-called behavioural gap or presence. We present preliminary, but promising, results that support the potential of this methodology and discuss about future steps.
Data-driven vehicle speed detection from synthetic driving simulator images
Apr 20, 2021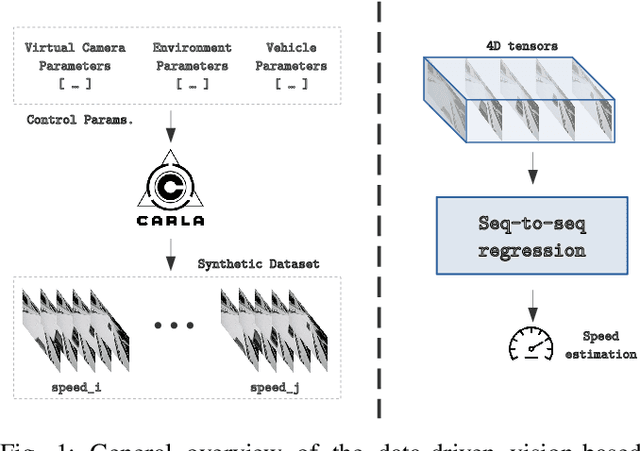
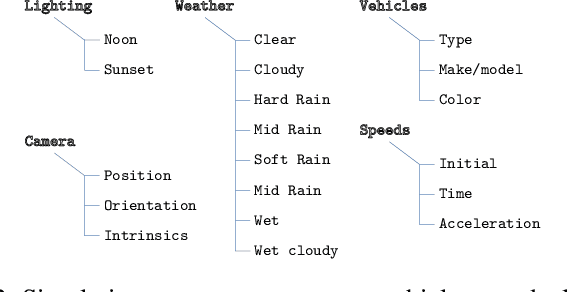
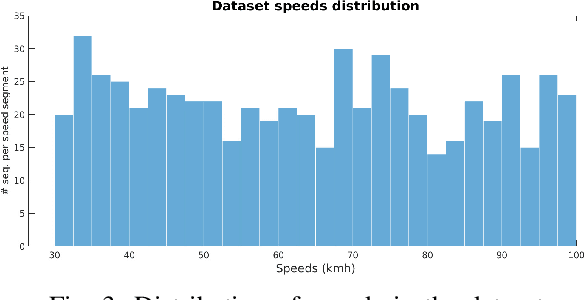

Despite all the challenges and limitations, vision-based vehicle speed detection is gaining research interest due to its great potential benefits such as cost reduction, and enhanced additional functions. As stated in a recent survey [1], the use of learning-based approaches to address this problem is still in its infancy. One of the main difficulties is the need for a large amount of data, which must contain the input sequences and, more importantly, the output values corresponding to the actual speed of the vehicles. Data collection in this context requires a complex and costly setup to capture the images from the camera synchronized with a high precision speed sensor to generate the ground truth speed values. In this paper we explore, for the first time, the use of synthetic images generated from a driving simulator (e.g., CARLA) to address vehicle speed detection using a learning-based approach. We simulate a virtual camera placed over a stretch of road, and generate thousands of images with variability corresponding to multiple speeds, different vehicle types and colors, and lighting and weather conditions. Two different approaches to map the sequence of images to an output speed (regression) are studied, including CNN-GRU and 3D-CNN. We present preliminary results that support the high potential of this approach to address vehicle speed detection.
Fail-Aware LIDAR-Based Odometry for Autonomous Vehicles
Mar 05, 2021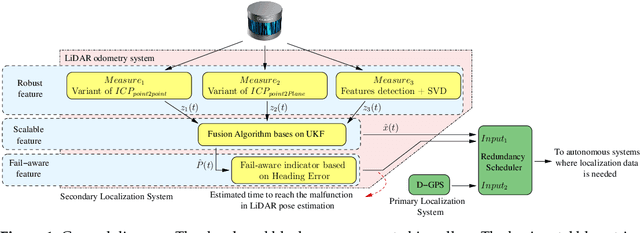
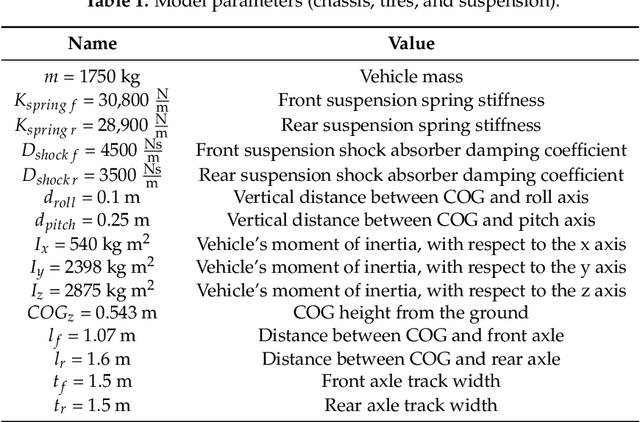
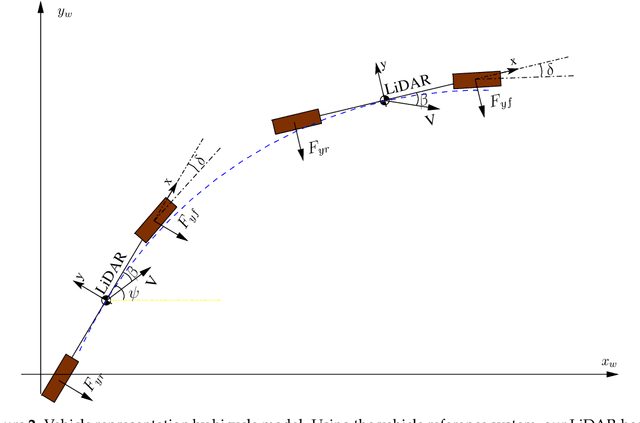
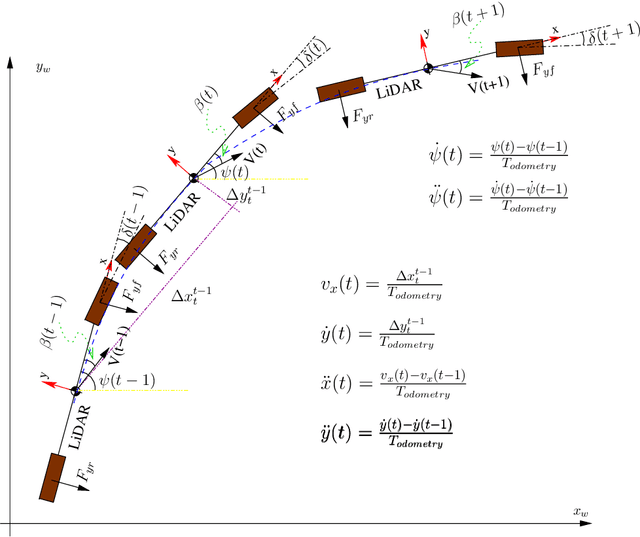
Autonomous driving systems are set to become a reality in transport systems and, so, maximum acceptance is being sought among users. Currently, the most advanced architectures require driver intervention when functional system failures or critical sensor operations take place, presenting problems related to driver state, distractions, fatigue, and other factors that prevent safe control. Therefore, this work presents a redundant, accurate, robust, and scalable LiDAR odometry system with fail-aware system features that can allow other systems to perform a safe stop manoeuvre without driver mediation. All odometry systems have drift error, making it difficult to use them for localisation tasks over extended periods. For this reason, the paper presents an accurate LiDAR odometry system with a fail-aware indicator. This indicator estimates a time window in which the system manages the localisation tasks appropriately. The odometry error is minimised by applying a dynamic 6-DoF model and fusing measures based on the Iterative Closest Points (ICP), environment feature extraction, and Singular Value Decomposition (SVD) methods. The obtained results are promising for two reasons: First, in the KITTI odometry data set, the ranking achieved by the proposed method is twelfth, considering only LiDAR-based methods, where its translation and rotation errors are 1.00% and 0.0041 deg/m, respectively. Second, the encouraging results of the fail-aware indicator demonstrate the safety of the proposed LiDAR odometry system. The results depict that, in order to achieve an accurate odometry system, complex models and measurement fusion techniques must be used to improve its behaviour. Furthermore, if an odometry system is to be used for redundant localisation features, it must integrate a fail-aware indicator for use in a safe manner.
Vision-based Vehicle Speed Estimation for ITS: A Survey
Jan 15, 2021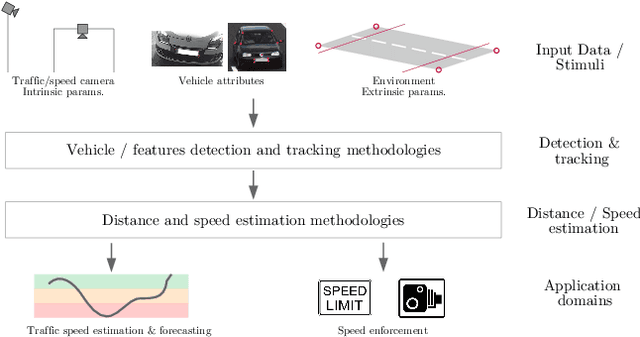


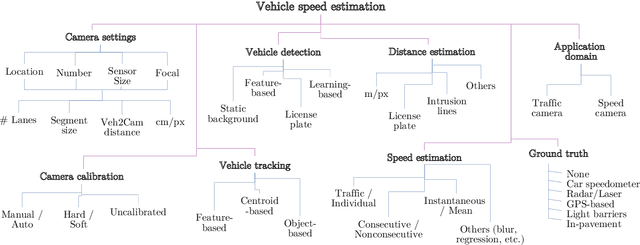
The need to accurately estimate the speed of road vehicles is becoming increasingly important for at least two main reasons. First, the number of speed cameras installed worldwide has been growing in recent years, as the introduction and enforcement of appropriate speed limits is considered one of the most effective means to increase the road safety. Second, traffic monitoring and forecasting in road networks plays a fundamental role to enhance traffic, emissions and energy consumption in smart cities, being the speed of the vehicles one of the most relevant parameters of the traffic state. Among the technologies available for the accurate detection of vehicle speed, the use of vision-based systems brings great challenges to be solved, but also great potential advantages, such as the drastic reduction of costs due to the absence of expensive range sensors, and the possibility of identifying vehicles accurately. This paper provides a review of vision-based vehicle speed estimation. We describe the terminology, the application domains, and propose a complete taxonomy of a large selection of works that categorizes all stages involved. An overview of performance evaluation metrics and available datasets is provided. Finally, we discuss current limitations and future directions.