 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards view-invariant vehicle speed detection from driving simulator images
Paper and Code
Jun 01, 2022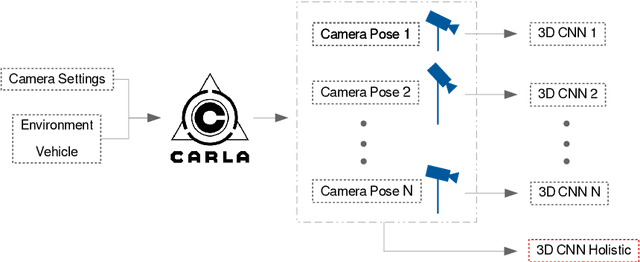
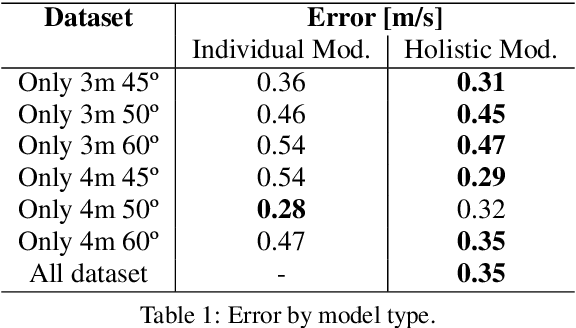
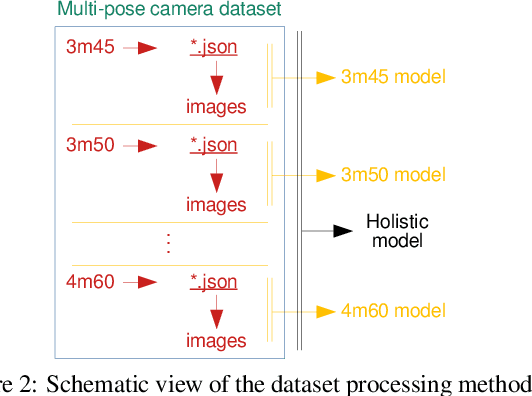

The use of cameras for vehicle speed measurement is much more cost effective compared to other technologies such as inductive loops, radar or laser. However, accurate speed measurement remains a challenge due to the inherent limitations of cameras to provide accurate range estimates. In addition, classical vision-based methods are very sensitive to extrinsic calibration between the camera and the road. In this context, the use of data-driven approaches appears as an interesting alternative. However, data collection requires a complex and costly setup to record videos under real traffic conditions from the camera synchronized with a high-precision speed sensor to generate the ground truth speed values. It has recently been demonstrated that the use of driving simulators (e.g., CARLA) can serve as a robust alternative for generating large synthetic datasets to enable the application of deep learning techniques for vehicle speed estimation for a single camera. In this paper, we study the same problem using multiple cameras in different virtual locations and with different extrinsic parameters. We address the question of whether complex 3D-CNN architectures are capable of implicitly learning view-invariant speeds using a single model, or whether view-specific models are more appropriate. The results are very promising as they show that a single model with data from multiple views reports even better accuracy than camera-specific models, paving the way towards a view-invariant vehicle speed measurement system.