 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervision policies can shape long-term risk management in general-purpose AI models
Jan 10, 2025



The rapid proliferation and deployment of General-Purpose AI (GPAI) models, including large language models (LLMs), present unprecedented challenges for AI supervisory entities. We hypothesize that these entities will need to navigate an emergent ecosystem of risk and incident reporting, likely to exceed their supervision capacity. To investigate this, we develop a simulation framework parameterized by features extracted from the diverse landscape of risk, incident, or hazard reporting ecosystems, including community-driven platforms, crowdsourcing initiatives, and expert assessments. We evaluate four supervision policies: non-prioritized (first-come, first-served), random selection, priority-based (addressing the highest-priority risks first), and diversity-prioritized (balancing high-priority risks with comprehensive coverage across risk types). Our results indicate that while priority-based and diversity-prioritized policies are more effective at mitigating high-impact risks, particularly those identified by experts, they may inadvertently neglect systemic issues reported by the broader community. This oversight can create feedback loops that amplify certain types of reporting while discouraging others, leading to a skewed perception of the overall risk landscape. We validate our simulation results with several real-world datasets, including one with over a million ChatGPT interactions, of which more than 150,000 conversations were identified as risky. This validation underscores the complex trade-offs inherent in AI risk supervision and highlights how the choice of risk management policies can shape the future landscape of AI risks across diverse GPAI models used in society.
Towards view-invariant vehicle speed detection from driving simulator images
Jun 01, 2022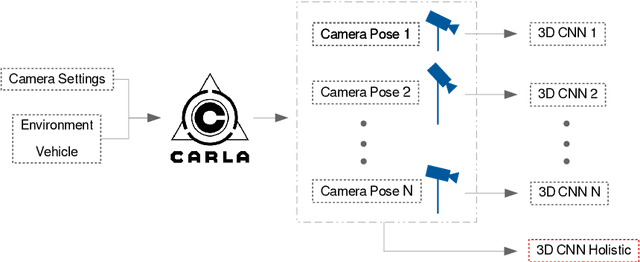
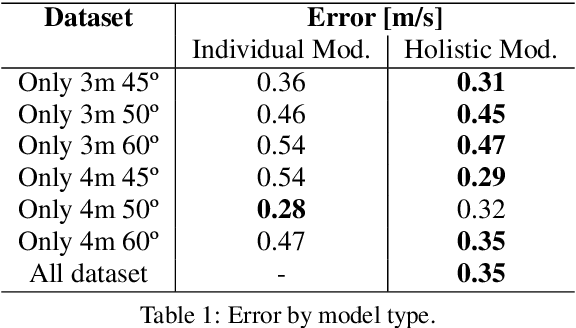
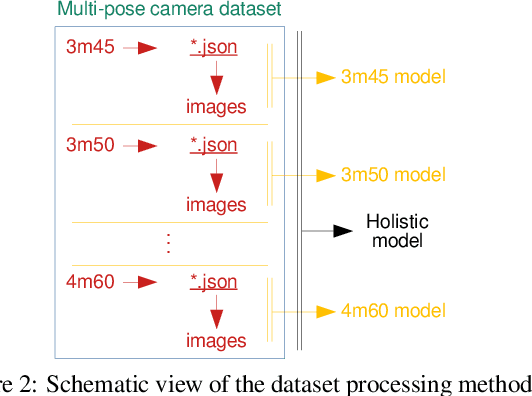

The use of cameras for vehicle speed measurement is much more cost effective compared to other technologies such as inductive loops, radar or laser. However, accurate speed measurement remains a challenge due to the inherent limitations of cameras to provide accurate range estimates. In addition, classical vision-based methods are very sensitive to extrinsic calibration between the camera and the road. In this context, the use of data-driven approaches appears as an interesting alternative. However, data collection requires a complex and costly setup to record videos under real traffic conditions from the camera synchronized with a high-precision speed sensor to generate the ground truth speed values. It has recently been demonstrated that the use of driving simulators (e.g., CARLA) can serve as a robust alternative for generating large synthetic datasets to enable the application of deep learning techniques for vehicle speed estimation for a single camera. In this paper, we study the same problem using multiple cameras in different virtual locations and with different extrinsic parameters. We address the question of whether complex 3D-CNN architectures are capable of implicitly learning view-invariant speeds using a single model, or whether view-specific models are more appropriate. The results are very promising as they show that a single model with data from multiple views reports even better accuracy than camera-specific models, paving the way towards a view-invariant vehicle speed measurement system.
RNN-based Pedestrian Crossing Prediction using Activity and Pose-related Features
Aug 26, 2020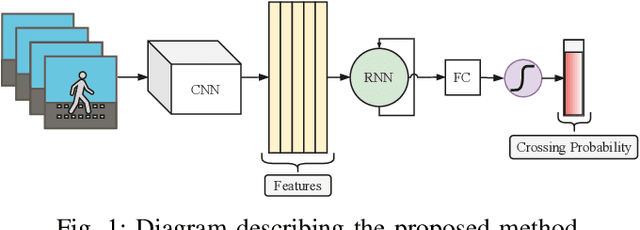
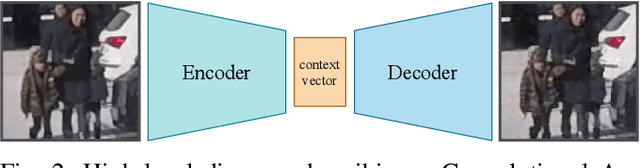

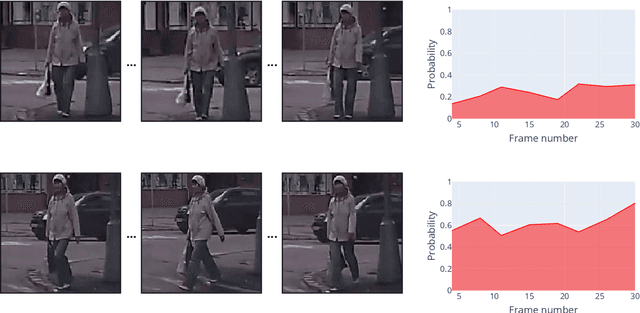
Pedestrian crossing prediction is a crucial task for autonomous driving. Numerous studies show that an early estimation of the pedestrian's intention can decrease or even avoid a high percentage of accidents. In this paper, different variations of a deep learning system are proposed to attempt to solve this problem. The proposed models are composed of two parts: a CNN-based feature extractor and an RNN module. All the models were trained and tested on the JAAD dataset. The results obtained indicate that the choice of the features extraction method, the inclusion of additional variables such as pedestrian gaze direction and discrete orientation, and the chosen RNN type have a significant impact on the final performance.
Pedestrian Path, Pose and Intention Prediction through Gaussian Process Dynamical Models and Pedestrian Activity Recognition
Apr 30, 2020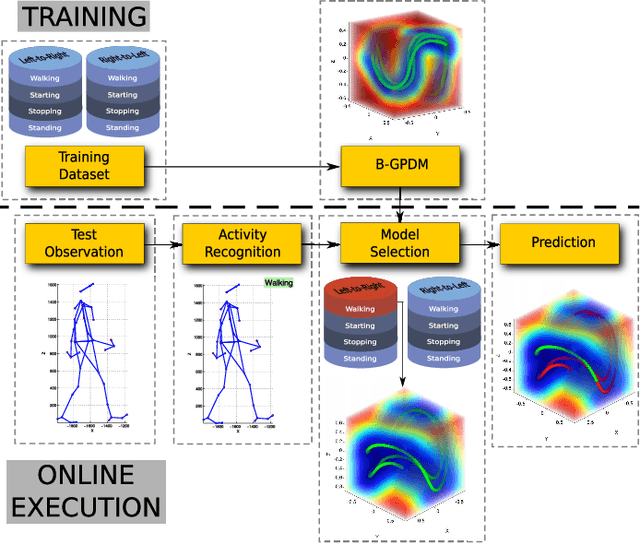
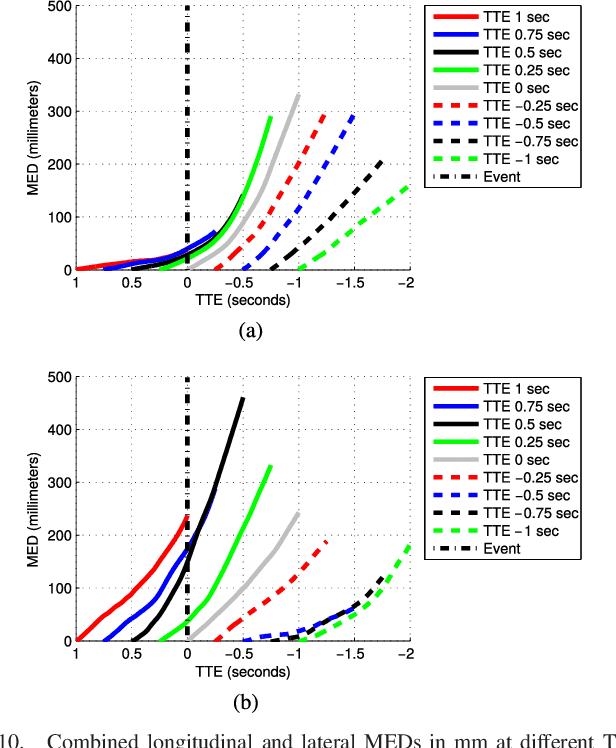
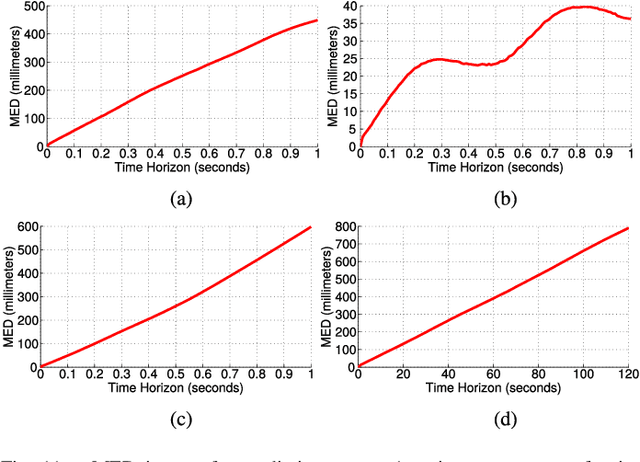
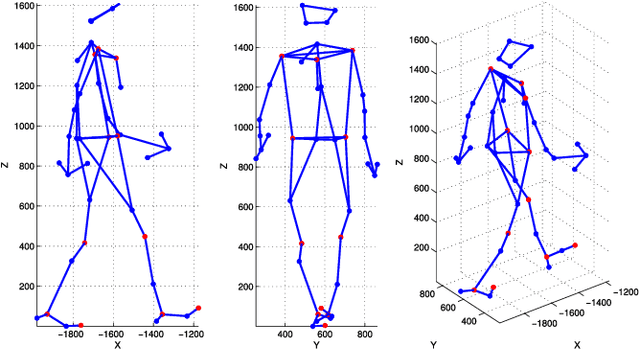
According to several reports published by worldwide organisations, thousands of pedestrians die in road accidents every year. Due to this fact, vehicular technologies have been evolving with the intent of reducing these fatalities. This evolution has not finished yet since, for instance, the predictions of pedestrian paths could improve the current Automatic Emergency Braking Systems (AEBS). For this reason, this paper proposes a method to predict future pedestrian paths, poses and intentions up to 1s in advance. This method is based on Balanced Gaussian Process Dynamical Models (B-GPDMs), which reduce the 3D time-related information extracted from keypoints or joints placed along pedestrian bodies into low-dimensional spaces. The B-GPDM is also capable of inferring future latent positions and reconstruct their associated observations. However, learning a generic model for all kind of pedestrian activities normally provides less ccurate predictions. For this reason, the proposed method obtains multiple models of four types of activity, i.e. walking, stopping, starting and standing, and selects the most similar model to estimate future pedestrian states. This method detects starting activities 125ms after the gait initiation with an accuracy of 80% and recognises stopping intentions 58.33ms before the event with an accuracy of 70%. Concerning the path prediction, the mean error for stopping activities at a Time-To-Event (TTE) of 1s is 238.01mm and, for starting actions, the mean error at a TTE of 0s is 331.93mm.