 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWith a Little Help From My Friends: Collective Manipulation in Risk-Controlling Recommender Systems
Mar 30, 2026Recommendation systems have become central gatekeepers of online information, shaping user behaviour across a wide range of activities. In response, users increasingly organize and coordinate to steer algorithmic outcomes toward diverse goals, such as promoting relevant content or limiting harmful material, relying on platform affordances -- such as likes, reviews, or ratings. While these mechanisms can serve beneficial purposes, they can also be leveraged for adversarial manipulation, particularly in systems where such feedback directly informs safety guarantees. In this paper, we study this vulnerability in recently proposed risk-controlling recommender systems, which use binary user feedback (e.g., "Not Interested") to provably limit exposure to unwanted content via conformal risk control. We empirically demonstrate that their reliance on aggregate feedback signals makes them inherently susceptible to coordinated adversarial user behaviour. Using data from a large-scale online video-sharing platform, we show that a small coordinated group (comprising only 1% of the user population) can induce up to a 20% degradation in nDCG for non-adversarial users by exploiting the affordances provided by risk-controlling recommender systems. We evaluate simple, realistic attack strategies that require little to no knowledge of the underlying recommendation algorithm and find that, while coordinated users can significantly harm overall recommendation quality, they cannot selectively suppress specific content groups through reporting alone. Finally, we propose a mitigation strategy that shifts guarantees from the group level to the user level, showing empirically how it can reduce the impact of adversarial coordinated behaviour while ensuring personalized safety for individuals.
Can We Trust AI Benchmarks? An Interdisciplinary Review of Current Issues in AI Evaluation
Feb 10, 2025Quantitative Artificial Intelligence (AI) Benchmarks have emerged as fundamental tools for evaluating the performance, capability, and safety of AI models and systems. Currently, they shape the direction of AI development and are playing an increasingly prominent role in regulatory frameworks. As their influence grows, however, so too does concerns about how and with what effects they evaluate highly sensitive topics such as capabilities, including high-impact capabilities, safety and systemic risks. This paper presents an interdisciplinary meta-review of about 100 studies that discuss shortcomings in quantitative benchmarking practices, published in the last 10 years. It brings together many fine-grained issues in the design and application of benchmarks (such as biases in dataset creation, inadequate documentation, data contamination, and failures to distinguish signal from noise) with broader sociotechnical issues (such as an over-focus on evaluating text-based AI models according to one-time testing logic that fails to account for how AI models are increasingly multimodal and interact with humans and other technical systems). Our review also highlights a series of systemic flaws in current benchmarking practices, such as misaligned incentives, construct validity issues, unknown unknowns, and problems with the gaming of benchmark results. Furthermore, it underscores how benchmark practices are fundamentally shaped by cultural, commercial and competitive dynamics that often prioritise state-of-the-art performance at the expense of broader societal concerns. By providing an overview of risks associated with existing benchmarking procedures, we problematise disproportionate trust placed in benchmarks and contribute to ongoing efforts to improve the accountability and relevance of quantitative AI benchmarks within the complexities of real-world scenarios.
Supervision policies can shape long-term risk management in general-purpose AI models
Jan 10, 2025



The rapid proliferation and deployment of General-Purpose AI (GPAI) models, including large language models (LLMs), present unprecedented challenges for AI supervisory entities. We hypothesize that these entities will need to navigate an emergent ecosystem of risk and incident reporting, likely to exceed their supervision capacity. To investigate this, we develop a simulation framework parameterized by features extracted from the diverse landscape of risk, incident, or hazard reporting ecosystems, including community-driven platforms, crowdsourcing initiatives, and expert assessments. We evaluate four supervision policies: non-prioritized (first-come, first-served), random selection, priority-based (addressing the highest-priority risks first), and diversity-prioritized (balancing high-priority risks with comprehensive coverage across risk types). Our results indicate that while priority-based and diversity-prioritized policies are more effective at mitigating high-impact risks, particularly those identified by experts, they may inadvertently neglect systemic issues reported by the broader community. This oversight can create feedback loops that amplify certain types of reporting while discouraging others, leading to a skewed perception of the overall risk landscape. We validate our simulation results with several real-world datasets, including one with over a million ChatGPT interactions, of which more than 150,000 conversations were identified as risky. This validation underscores the complex trade-offs inherent in AI risk supervision and highlights how the choice of risk management policies can shape the future landscape of AI risks across diverse GPAI models used in society.
Documenting use cases in the affective computing domain using Unified Modeling Language
Sep 19, 2022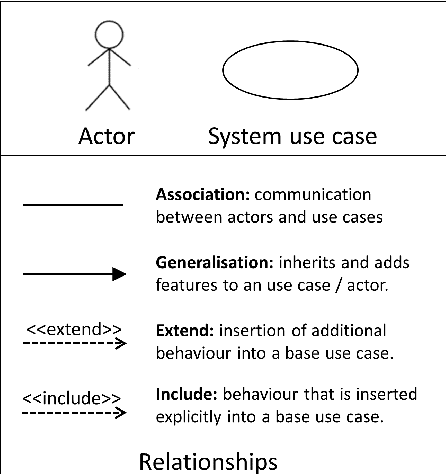
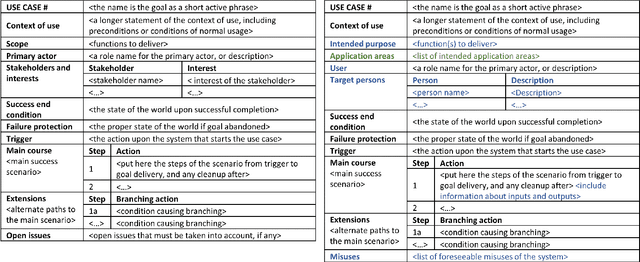
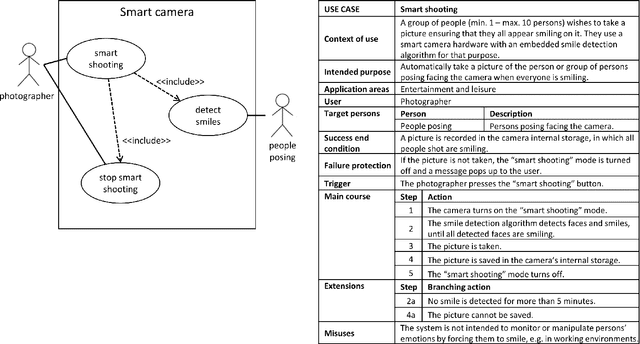
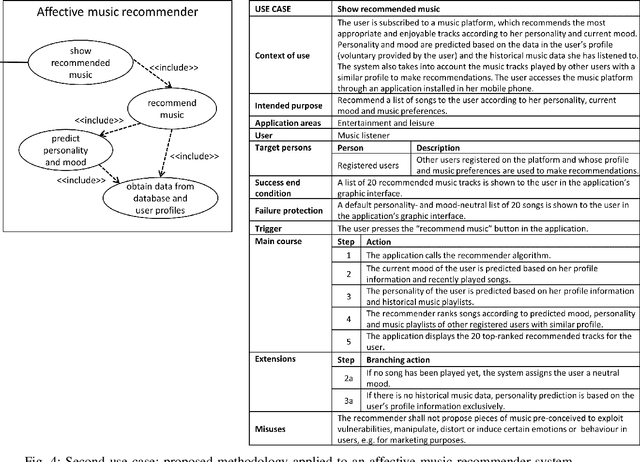
The study of the ethical impact of AI and the design of trustworthy systems needs the analysis of the scenarios where AI systems are used, which is related to the software engineering concept of "use case" and the "intended purpose" legal term. However, there is no standard methodology for use case documentation covering the context of use, scope, functional requirements and risks of an AI system. In this work, we propose a novel documentation methodology for AI use cases, with a special focus on the affective computing domain. Our approach builds upon an assessment of use case information needs documented in the research literature and the recently proposed European regulatory framework for AI. From this assessment, we adopt and adapt the Unified Modeling Language (UML), which has been used in the last two decades mostly by software engineers. Each use case is then represented by an UML diagram and a structured table, and we provide a set of examples illustrating its application to several affective computing scenarios.
Monitoring Diversity of AI Conferences: Lessons Learnt and Future Challenges in the DivinAI Project
Mar 03, 2022

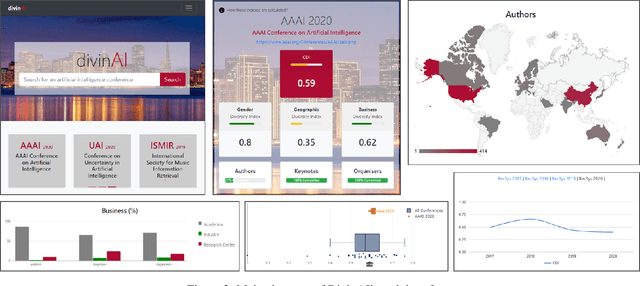
DivinAI is an open and collaborative initiative promoted by the European Commission's Joint Research Centre to measure and monitor diversity indicators related to AI conferences, with special focus on gender balance, geographical representation, and presence of academia vs companies. This paper summarizes the main achievements and lessons learnt during the first year of life of the DivinAI project, and proposes a set of recommendations for its further development and maintenance by the AI community.
Deep Learning Based Source Separation Applied To Choir Ensembles
Aug 17, 2020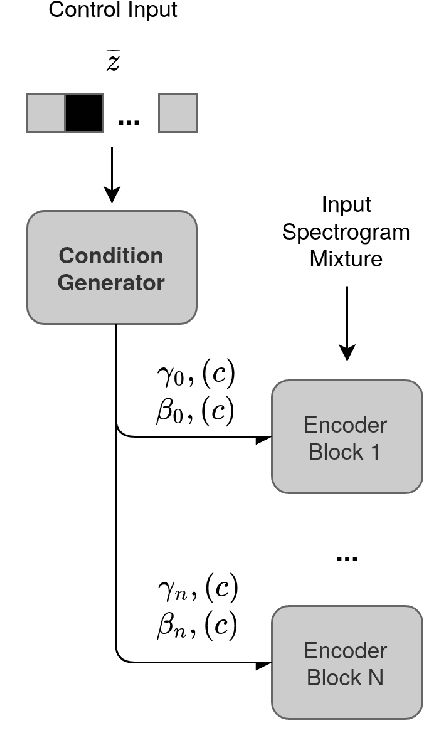
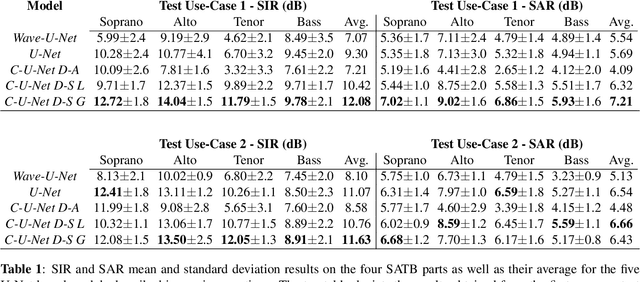
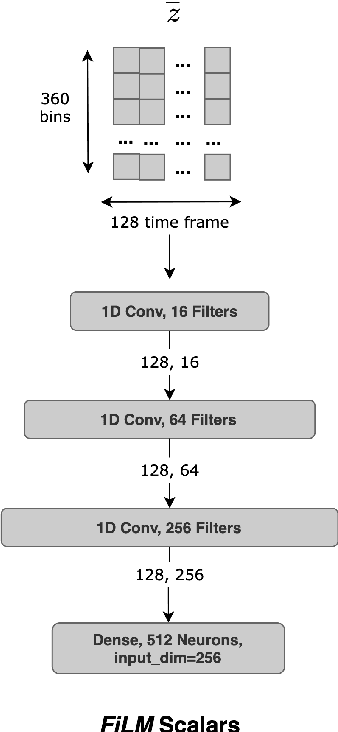
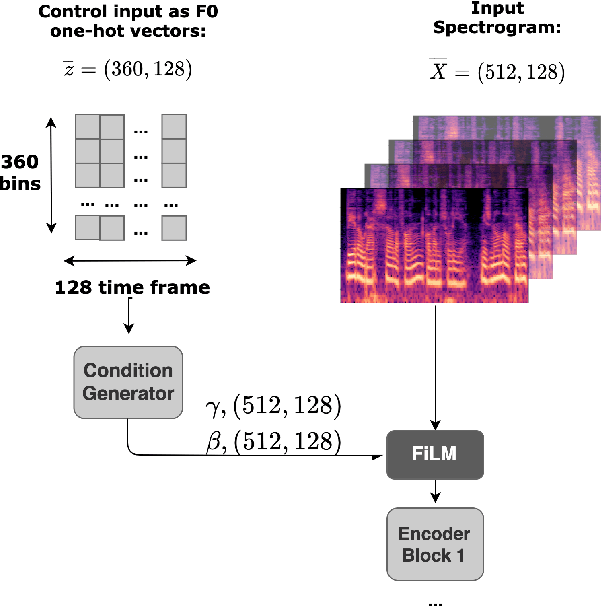
Choral singing is a widely practiced form of ensemble singing wherein a group of people sing simultaneously in polyphonic harmony. The most commonly practiced setting for choir ensembles consists of four parts; Soprano, Alto, Tenor and Bass (SATB), each with its own range of fundamental frequencies (F$0$s). The task of source separation for this choral setting entails separating the SATB mixture into the constituent parts. Source separation for musical mixtures is well studied and many deep learning based methodologies have been proposed for the same. However, most of the research has been focused on a typical case which consists in separating vocal, percussion and bass sources from a mixture, each of which has a distinct spectral structure. In contrast, the simultaneous and harmonic nature of ensemble singing leads to high structural similarity and overlap between the spectral components of the sources in a choral mixture, making source separation for choirs a harder task than the typical case. This, along with the lack of an appropriate consolidated dataset has led to a dearth of research in the field so far. In this paper we first assess how well some of the recently developed methodologies for musical source separation perform for the case of SATB choirs. We then propose a novel domain-specific adaptation for conditioning the recently proposed U-Net architecture for musical source separation using the fundamental frequency contour of each of the singing groups and demonstrate that our proposed approach surpasses results from domain-agnostic architectures.
Content Based Singing Voice Extraction From a Musical Mixture
Feb 17, 2020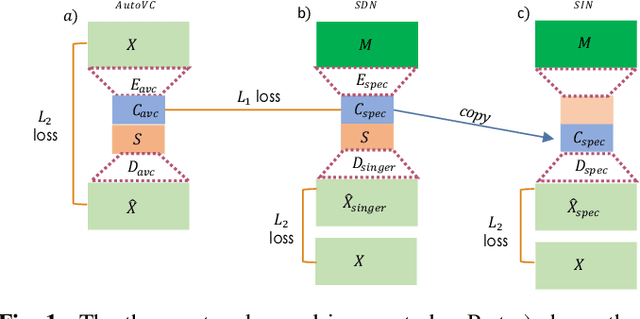
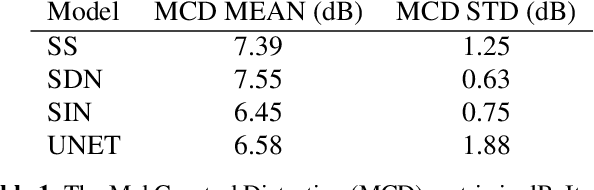
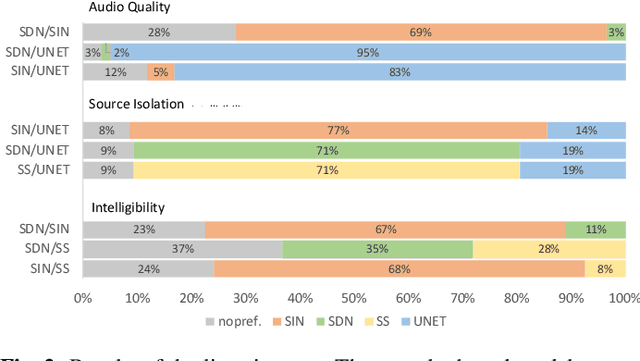
We present a deep learning based methodology for extracting the singing voice signal from a musical mixture based on the underlying linguistic content. Our model follows an encoder decoder architecture and takes as input the magnitude component of the spectrogram of a musical mixture with vocals. The encoder part of the model is trained via knowledge distillation using a teacher network to learn a content embedding, which is decoded to generate the corresponding vocoder features. Using this methodology, we are able to extract the unprocessed raw vocal signal from the mixture even for a processed mixture dataset with singers not seen during training. While the nature of our system makes it incongruous with traditional objective evaluation metrics, we use subjective evaluation via listening tests to compare the methodology to state-of-the-art deep learning based source separation algorithms. We also provide sound examples and source code for reproducibility.
* To be published in ICASSP 2020
Artificial intelligence in medicine and healthcare: a review and classification of current and near-future applications and their ethical and social Impact
Feb 06, 2020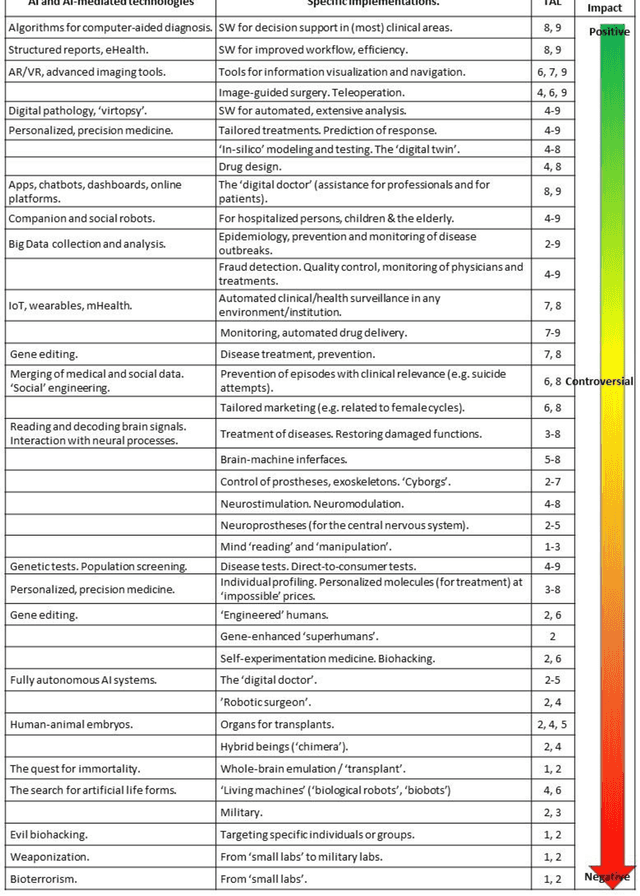
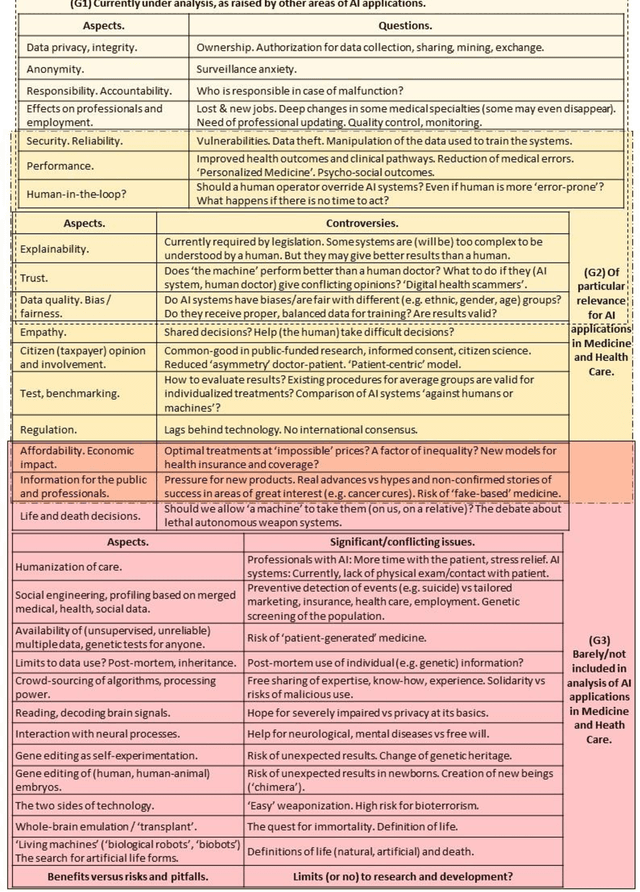
This paper provides an overview of the current and near-future applications of Artificial Intelligence (AI) in Medicine and Health Care and presents a classification according to their ethical and societal aspects, potential benefits and pitfalls, and issues that can be considered controversial and are not deeply discussed in the literature. This work is based on an analysis of the state of the art of research and technology, including existing software, personal monitoring devices, genetic tests and editing tools, personalized digital models, online platforms, augmented reality devices, and surgical and companion robotics. Motivated by our review, we present and describe the notion of 'extended personalized medicine', we then review existing applications of AI in medicine and healthcare and explore the public perception of medical AI systems, and how they show, simultaneously, extraordinary opportunities and drawbacks that even question fundamental medical concepts. Many of these topics coincide with urgent priorities recently defined by the World Health Organization for the coming decade. In addition, we study the transformations of the roles of doctors and patients in an age of ubiquitous information, identify the risk of a division of Medicine into 'fake-based', 'patient-generated', and 'scientifically tailored', and draw the attention of some aspects that need further thorough analysis and public debate.
End-to-End Sound Source Separation Conditioned On Instrument Labels
Nov 05, 2018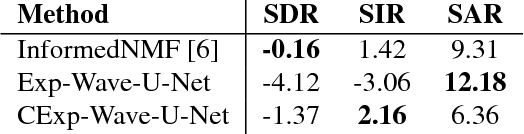
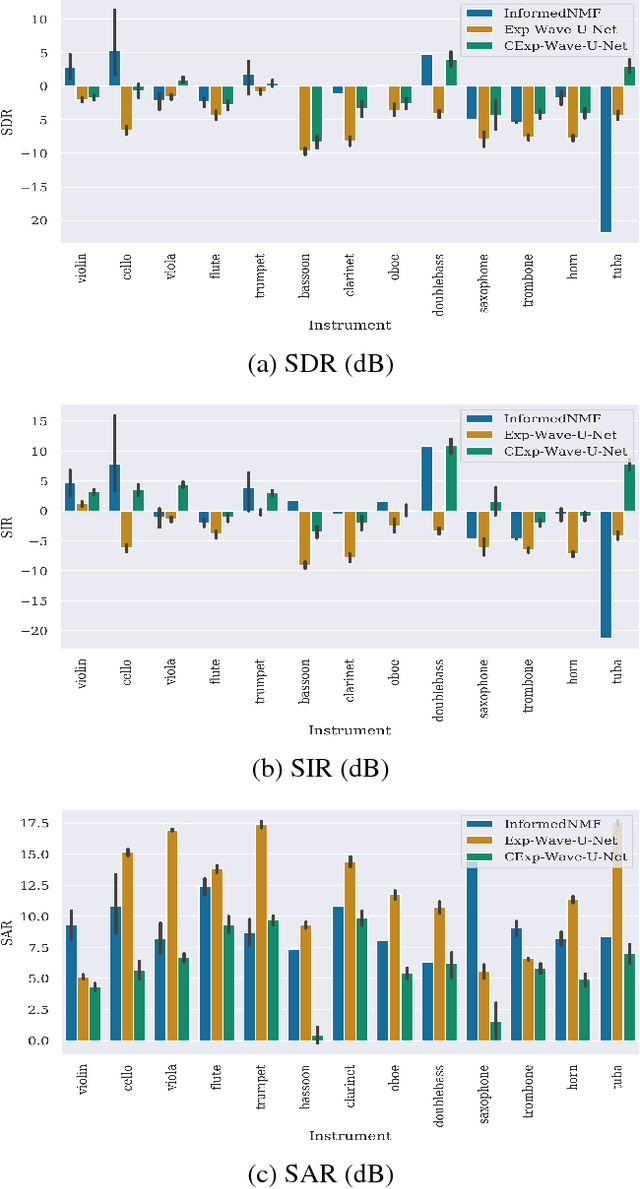
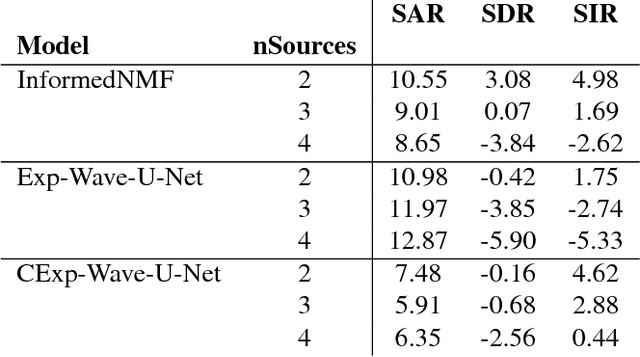
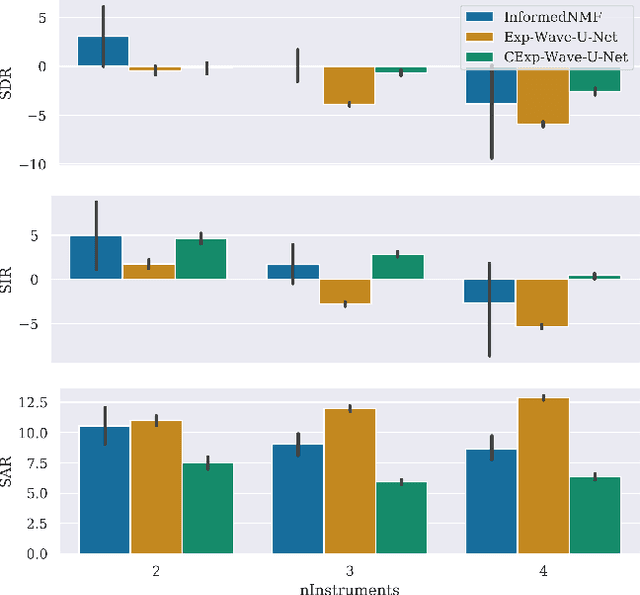
Can we perform an end-to-end sound source separation (SSS) with a variable number of sources using a deep learning model? This paper presents an extension of the Wave-U-Net model which allows end-to-end monaural source separation with a non-fixed number of sources. Furthermore, we propose multiplicative conditioning with instrument labels at the bottleneck of the Wave-U-Net and show its effect on the separation results. This approach can be further extended to other types of conditioning such as audio-visual SSS and score-informed SSS.