 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Human-Level AI Tales to AI Leveling Human Scales
Feb 21, 2026Comparing AI models to "human level" is often misleading when benchmark scores are incommensurate or human baselines are drawn from a narrow population. To address this, we propose a framework that calibrates items against the 'world population' and report performance on a common, human-anchored scale. Concretely, we build on a set of multi-level scales for different capabilities where each level should represent a probability of success of the whole world population on a logarithmic scale with a base $B$. We calibrate each scale for each capability (reasoning, comprehension, knowledge, volume, etc.) by compiling publicly released human test data spanning education and reasoning benchmarks (PISA, TIMSS, ICAR, UKBioBank, and ReliabilityBench). The base $B$ is estimated by extrapolating between samples with two demographic profiles using LLMs, with the hypothesis that they condense rich information about human populations. We evaluate the quality of different mappings using group slicing and post-stratification. The new techniques allow for the recalibration and standardization of scales relative to the whole-world population.
Rethinking the Illusion of Thinking
Jul 01, 2025Earlier this year, Apple ignited controversy by publishing "The Illusion of Thinking," prompting heated debate within the AI community. Critics seized upon the findings as conclusive evidence that Large Reasoning Models (LRMs) lack genuine reasoning capabilities, branding them as mere stochastic parrots. Meanwhile, defenders-spearheaded by Lawsen et al. (2025)-fired back, condemning the experimental setup as flawed and the conclusions overstated. We clarify this debate by replicating and refining two of the original study's most contentious benchmarks: Towers of Hanoi and River Crossing. By introducing incremental stepwise prompting and agentic collaborative dialogue, we show that previously reported failures solving the Towers of Hanoi were not purely result of output constraints, but also partly a result of cognition limitations: LRMs still stumble when complexity rises moderately (around 8 disks). Moreover, the River Crossing results initially heralded as catastrophic failures turn out to hinge upon testing unsolvable configurations. Once we limit tests strictly to solvable problems-LRMs effortlessly solve large instances involving over 100 agent pairs. Our findings ultimately defy simplistic narratives: today's LRMs are stochastic, RL-tuned searchers in a discrete state space we barely understand. Real progress in symbolic, long-horizon reasoning demands mapping that terrain through fine-grained ablations like those introduced here.
Sensorimotor features of self-awareness in multimodal large language models
May 25, 2025Self-awareness - the ability to distinguish oneself from the surrounding environment - underpins intelligent, autonomous behavior. Recent advances in AI achieve human-like performance in tasks integrating multimodal information, particularly in large language models, raising interest in the embodiment capabilities of AI agents on nonhuman platforms such as robots. Here, we explore whether multimodal LLMs can develop self-awareness solely through sensorimotor experiences. By integrating a multimodal LLM into an autonomous mobile robot, we test its ability to achieve this capacity. We find that the system exhibits robust environmental awareness, self-recognition and predictive awareness, allowing it to infer its robotic nature and motion characteristics. Structural equation modeling reveals how sensory integration influences distinct dimensions of self-awareness and its coordination with past-present memory, as well as the hierarchical internal associations that drive self-identification. Ablation tests of sensory inputs identify critical modalities for each dimension, demonstrate compensatory interactions among sensors and confirm the essential role of structured and episodic memory in coherent reasoning. These findings demonstrate that, given appropriate sensory information about the world and itself, multimodal LLMs exhibit emergent self-awareness, opening the door to artificial embodied cognitive systems.
General Scales Unlock AI Evaluation with Explanatory and Predictive Power
Mar 09, 2025Ensuring safe and effective use of AI requires understanding and anticipating its performance on novel tasks, from advanced scientific challenges to transformed workplace activities. So far, benchmarking has guided progress in AI, but it has offered limited explanatory and predictive power for general-purpose AI systems, given the low transferability across diverse tasks. In this paper, we introduce general scales for AI evaluation that can explain what common AI benchmarks really measure, extract ability profiles of AI systems, and predict their performance for new task instances, in- and out-of-distribution. Our fully-automated methodology builds on 18 newly-crafted rubrics that place instance demands on general scales that do not saturate. Illustrated for 15 large language models and 63 tasks, high explanatory power is unleashed from inspecting the demand and ability profiles, bringing insights on the sensitivity and specificity exhibited by different benchmarks, and how knowledge, metacognition and reasoning are affected by model size, chain-of-thought and distillation. Surprisingly, high predictive power at the instance level becomes possible using these demand levels, providing superior estimates over black-box baseline predictors based on embeddings or finetuning, especially in out-of-distribution settings (new tasks and new benchmarks). The scales, rubrics, battery, techniques and results presented here represent a major step for AI evaluation, underpinning the reliable deployment of AI in the years ahead.
Supervision policies can shape long-term risk management in general-purpose AI models
Jan 10, 2025



The rapid proliferation and deployment of General-Purpose AI (GPAI) models, including large language models (LLMs), present unprecedented challenges for AI supervisory entities. We hypothesize that these entities will need to navigate an emergent ecosystem of risk and incident reporting, likely to exceed their supervision capacity. To investigate this, we develop a simulation framework parameterized by features extracted from the diverse landscape of risk, incident, or hazard reporting ecosystems, including community-driven platforms, crowdsourcing initiatives, and expert assessments. We evaluate four supervision policies: non-prioritized (first-come, first-served), random selection, priority-based (addressing the highest-priority risks first), and diversity-prioritized (balancing high-priority risks with comprehensive coverage across risk types). Our results indicate that while priority-based and diversity-prioritized policies are more effective at mitigating high-impact risks, particularly those identified by experts, they may inadvertently neglect systemic issues reported by the broader community. This oversight can create feedback loops that amplify certain types of reporting while discouraging others, leading to a skewed perception of the overall risk landscape. We validate our simulation results with several real-world datasets, including one with over a million ChatGPT interactions, of which more than 150,000 conversations were identified as risky. This validation underscores the complex trade-offs inherent in AI risk supervision and highlights how the choice of risk management policies can shape the future landscape of AI risks across diverse GPAI models used in society.
Can adversarial attacks by large language models be attributed?
Nov 12, 2024

Attributing outputs from Large Language Models (LLMs) in adversarial settings-such as cyberattacks and disinformation-presents significant challenges that are likely to grow in importance. We investigate this attribution problem using formal language theory, specifically language identification in the limit as introduced by Gold and extended by Angluin. By modeling LLM outputs as formal languages, we analyze whether finite text samples can uniquely pinpoint the originating model. Our results show that due to the non-identifiability of certain language classes, under some mild assumptions about overlapping outputs from fine-tuned models it is theoretically impossible to attribute outputs to specific LLMs with certainty. This holds also when accounting for expressivity limitations of Transformer architectures. Even with direct model access or comprehensive monitoring, significant computational hurdles impede attribution efforts. These findings highlight an urgent need for proactive measures to mitigate risks posed by adversarial LLM use as their influence continues to expand.
Conversational Complexity for Assessing Risk in Large Language Models
Sep 02, 2024



Large Language Models (LLMs) present a dual-use dilemma: they enable beneficial applications while harboring potential for harm, particularly through conversational interactions. Despite various safeguards, advanced LLMs remain vulnerable. A watershed case was Kevin Roose's notable conversation with Bing, which elicited harmful outputs after extended interaction. This contrasts with simpler early jailbreaks that produced similar content more easily, raising the question: How much conversational effort is needed to elicit harmful information from LLMs? We propose two measures: Conversational Length (CL), which quantifies the conversation length used to obtain a specific response, and Conversational Complexity (CC), defined as the Kolmogorov complexity of the user's instruction sequence leading to the response. To address the incomputability of Kolmogorov complexity, we approximate CC using a reference LLM to estimate the compressibility of user instructions. Applying this approach to a large red-teaming dataset, we perform a quantitative analysis examining the statistical distribution of harmful and harmless conversational lengths and complexities. Our empirical findings suggest that this distributional analysis and the minimisation of CC serve as valuable tools for understanding AI safety, offering insights into the accessibility of harmful information. This work establishes a foundation for a new perspective on LLM safety, centered around the algorithmic complexity of pathways to harm.
SensitiveLoss: Improving Accuracy and Fairness of Face Representations with Discrimination-Aware Deep Learning
Apr 22, 2020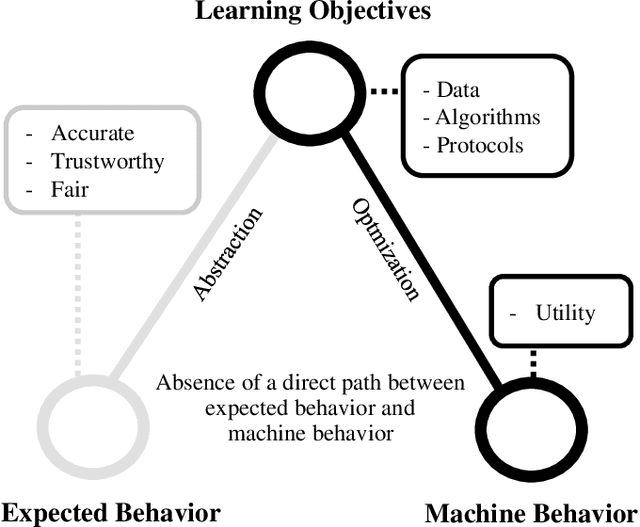
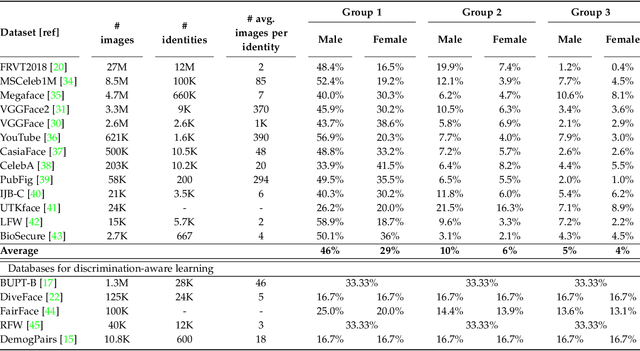
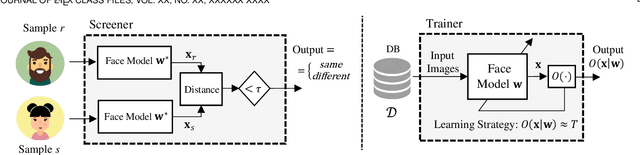
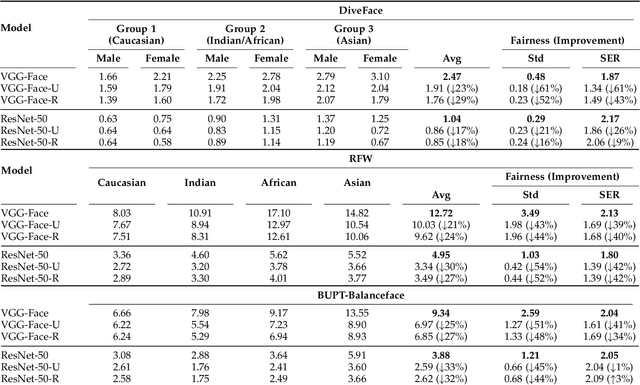
We propose a new discrimination-aware learning method to improve both accuracy and fairness of face recognition algorithms. The most popular face recognition benchmarks assume a distribution of subjects without paying much attention to their demographic attributes. In this work, we perform a comprehensive discrimination-aware experimentation of deep learning-based face recognition. We also propose a general formulation of algorithmic discrimination with application to face biometrics. The experiments include two popular face recognition models and three public databases composed of 64,000 identities from different demographic groups characterized by gender and ethnicity. We experimentally show that learning processes based on the most used face databases have led to popular pre-trained deep face models that present a strong algorithmic discrimination. We finally propose a discrimination-aware learning method, SensitiveLoss, based on the popular triplet loss function and a sensitive triplet generator. Our approach works as an add-on to pre-trained networks and is used to improve their performance in terms of average accuracy and fairness. The method shows results comparable to state-of-the-art de-biasing networks and represents a step forward to prevent discriminatory effects by automatic systems.
Algorithmic Discrimination: Formulation and Exploration in Deep Learning-based Face Biometrics
Dec 04, 2019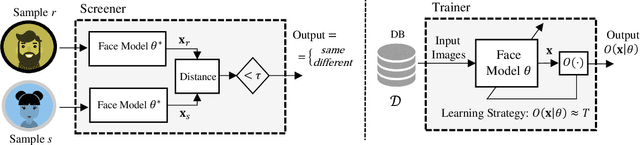

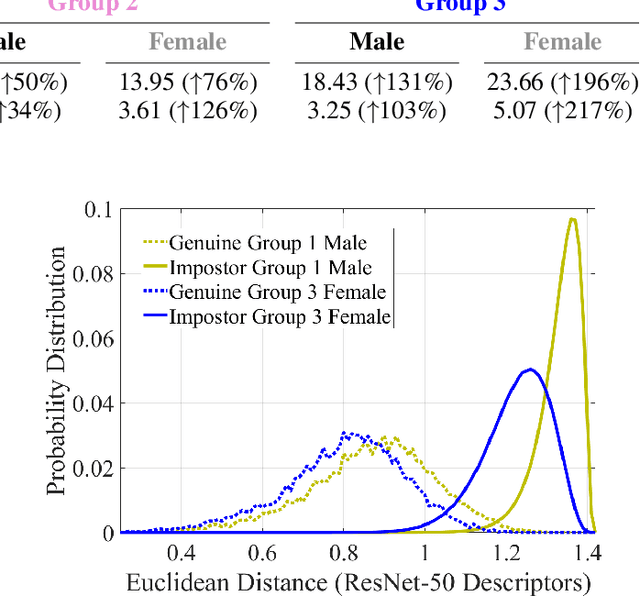
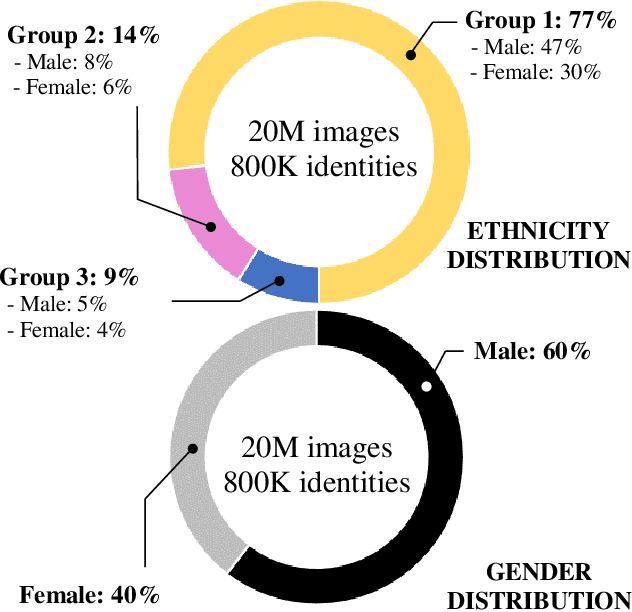
The most popular face recognition benchmarks assume a distribution of subjects without much attention to their demographic attributes. In this work, we perform a comprehensive discrimination-aware experimentation of deep learning-based face recognition. The main aim of this study is focused on a better understanding of the feature space generated by deep models, and the performance achieved over different demographic groups. We also propose a general formulation of algorithmic discrimination with application to face biometrics. The experiments are conducted over the new DiveFace database composed of 24K identities from six different demographic groups. Two popular face recognition models are considered in the experimental framework: ResNet-50 and VGG-Face. We experimentally show that demographic groups highly represented in popular face databases have led to popular pre-trained deep face models presenting strong algorithmic discrimination. That discrimination can be observed both qualitatively at the feature space of the deep models and quantitatively in large performance differences when applying those models in different demographic groups, e.g. for face biometrics.
Human detection of machine manipulated media
Jul 06, 2019
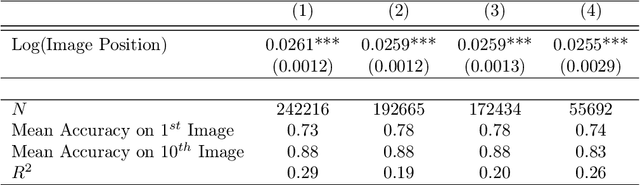
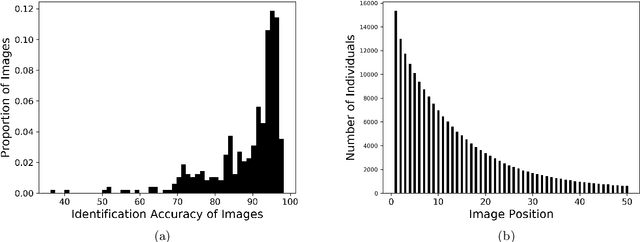
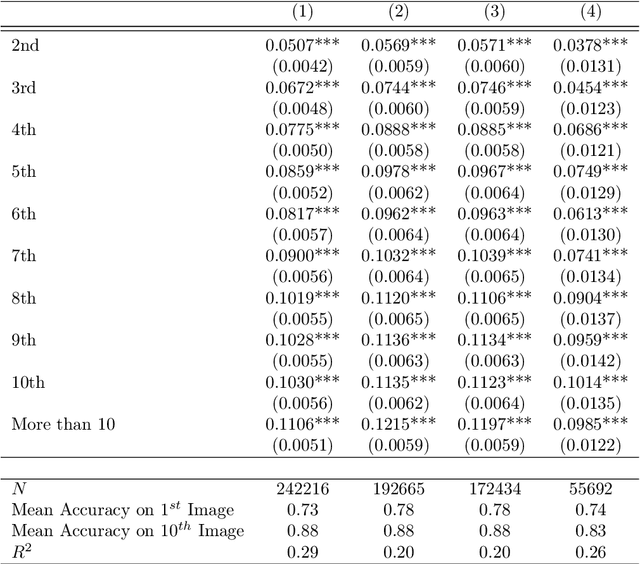
Recent advances in neural networks for content generation enable artificial intelligence (AI) models to generate high-quality media manipulations. Here we report on a randomized experiment designed to study the effect of exposure to media manipulations on over 15,000 individuals' ability to discern machine-manipulated media. We engineer a neural network to plausibly and automatically remove objects from images, and we deploy this neural network online with a randomized experiment where participants can guess which image out of a pair of images has been manipulated. The system provides participants feedback on the accuracy of each guess. In the experiment, we randomize the order in which images are presented, allowing causal identification of the learning curve surrounding participants' ability to detect fake content. We find sizable and robust evidence that individuals learn to detect fake content through exposure to manipulated media when provided iterative feedback on their detection attempts. Over a succession of only ten images, participants increase their rating accuracy by over ten percentage points. Our study provides initial evidence that human ability to detect fake, machine-generated content may increase alongside the prevalence of such media online.