 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching and Learning under Deductive Errors
May 13, 2026Most models of machine teaching and learning assume the learner makes no errors in its internal deductive inference. However, humans and large language models in few-shot learning regimes are two important examples of learners where this does not hold. They fail on some consistency checks, and they can fail stochastically. In this paper we introduce a teaching and learning framework that takes these deductive errors into account. We specifically study the case of machine teaching, as different characterizations of the teacher can account for both machine teaching and learning. In an overhauled Probably Approximately Correct (PAC) setting, we study theoretically that, for some estimated error level, the teacher must find a PAC teaching set that with high probability will lead the learner to guess a hypothesis that is approximately correct. We study the computational complexity of six different problems related to computing optimal PAC teaching sets. We give XP algorithms parametrized by size of teaching set, with tight runtime bounds under standard complexity assumptions like ETH. These results are complemented with a small experimental study of which teaching and learning protocols can best represent the observed behavior in some LLM teaching sessions.
Relative Drawing Identification Complexity is Invariant to Modality in Vision-Language Models
May 14, 2025Large language models have become multimodal, and many of them are said to integrate their modalities using common representations. If this were true, a drawing of a car as an image, for instance, should map to the similar area in the latent space as a textual description of the strokes that conform the drawing. To explore this in a black-box access regime to these models, we propose the use of machine teaching, a theory that studies the minimal set of examples a teacher needs to choose so that the learner captures the concept. In this paper we evaluate the complexity of teaching visual-language models a subset of objects in the Quick, Draw! dataset using two presentations: raw images as bitmaps and trace coordinates in TikZ format. The results indicate that image-based representations generally require fewer segments and achieve higher accuracy than coordinate-based representations. But, surprisingly, the teaching size usually ranks concepts similarly across both modalities, even when controlling for (a human proxy of) concept priors, suggesting that the simplicity of concepts may be an inherent property that transcends modality representations.
Evaluating Simplification Algorithms for Interpretability of Time Series Classification
May 13, 2025In this work, we introduce metrics to evaluate the use of simplified time series in the context of interpretability of a TSC - a Time Series Classifier. Such simplifications are important because time series data, in contrast to text and image data, are not intuitively understandable to humans. These metrics are related to the complexity of the simplifications - how many segments they contain - and to their loyalty - how likely they are to maintain the classification of the original time series. We employ these metrics to evaluate four distinct simplification algorithms, across several TSC algorithms and across datasets of varying characteristics, from seasonal or stationary to short or long. Our findings suggest that using simplifications for interpretability of TSC is much better than using the original time series, particularly when the time series are seasonal, non-stationary and/or with low entropy.
Can adversarial attacks by large language models be attributed?
Nov 12, 2024

Attributing outputs from Large Language Models (LLMs) in adversarial settings-such as cyberattacks and disinformation-presents significant challenges that are likely to grow in importance. We investigate this attribution problem using formal language theory, specifically language identification in the limit as introduced by Gold and extended by Angluin. By modeling LLM outputs as formal languages, we analyze whether finite text samples can uniquely pinpoint the originating model. Our results show that due to the non-identifiability of certain language classes, under some mild assumptions about overlapping outputs from fine-tuned models it is theoretically impossible to attribute outputs to specific LLMs with certainty. This holds also when accounting for expressivity limitations of Transformer architectures. Even with direct model access or comprehensive monitoring, significant computational hurdles impede attribution efforts. These findings highlight an urgent need for proactive measures to mitigate risks posed by adversarial LLM use as their influence continues to expand.
On a Combinatorial Problem Arising in Machine Teaching
Feb 09, 2024We study a model of machine teaching where the teacher mapping is constructed from a size function on both concepts and examples. The main question in machine teaching is the minimum number of examples needed for any concept, the so-called teaching dimension. A recent paper [7] conjectured that the worst case for this model, as a function of the size of the concept class, occurs when the consistency matrix contains the binary representations of numbers from zero and up. In this paper we prove their conjecture. The result can be seen as a generalization of a theorem resolving the edge isoperimetry problem for hypercubes [12], and our proof is based on a lemma of [10].
When Redundancy Matters: Machine Teaching of Representations
Jan 23, 2024In traditional machine teaching, a teacher wants to teach a concept to a learner, by means of a finite set of examples, the witness set. But concepts can have many equivalent representations. This redundancy strongly affects the search space, to the extent that teacher and learner may not be able to easily determine the equivalence class of each representation. In this common situation, instead of teaching concepts, we explore the idea of teaching representations. We work with several teaching schemas that exploit representation and witness size (Eager, Greedy and Optimal) and analyze the gains in teaching effectiveness for some representational languages (DNF expressions and Turing-complete P3 programs). Our theoretical and experimental results indicate that there are various types of redundancy, handled better by the Greedy schema introduced here than by the Eager schema, although both can be arbitrarily far away from the Optimal. For P3 programs we found that witness sets are usually smaller than the programs they identify, which is an illuminating justification of why machine teaching from examples makes sense at all.
MAP- and MLE-Based Teaching
Jul 11, 2023
Imagine a learner L who tries to infer a hidden concept from a collection of observations. Building on the work [4] of Ferri et al., we assume the learner to be parameterized by priors P(c) and by c-conditional likelihoods P(z|c) where c ranges over all concepts in a given class C and z ranges over all observations in an observation set Z. L is called a MAP-learner (resp. an MLE-learner) if it thinks of a collection S of observations as a random sample and returns the concept with the maximum a-posteriori probability (resp. the concept which maximizes the c-conditional likelihood of S). Depending on whether L assumes that S is obtained from ordered or unordered sampling resp. from sampling with or without replacement, we can distinguish four different sampling modes. Given a target concept c in C, a teacher for a MAP-learner L aims at finding a smallest collection of observations that causes L to return c. This approach leads in a natural manner to various notions of a MAP- or MLE-teaching dimension of a concept class C. Our main results are: We show that this teaching model has some desirable monotonicity properties. We clarify how the four sampling modes are related to each other. As for the (important!) special case, where concepts are subsets of a domain and observations are 0,1-labeled examples, we obtain some additional results. First of all, we characterize the MAP- and MLE-teaching dimension associated with an optimally parameterized MAP-learner graph-theoretically. From this central result, some other ones are easy to derive. It is shown, for instance, that the MLE-teaching dimension is either equal to the MAP-teaching dimension or exceeds the latter by 1. It is shown furthermore that these dimensions can be bounded from above by the so-called antichain number, the VC-dimension and related combinatorial parameters. Moreover they can be computed in polynomial time.
Finite Biased Teaching with Infinite Concept Classes
Apr 19, 2018
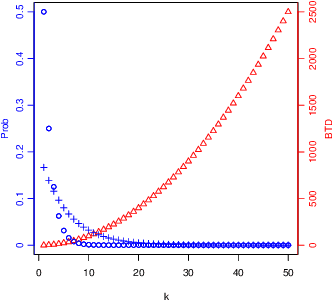
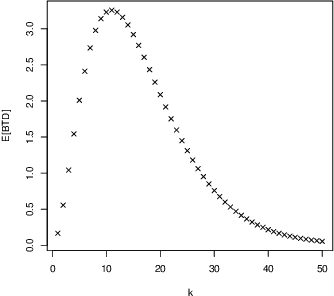

We investigate the teaching of infinite concept classes through the effect of the learning bias (which is used by the learner to prefer some concepts over others and by the teacher to devise the teaching examples) and the sampling bias (which determines how the concepts are sampled from the class). We analyse two important classes: Turing machines and finite-state machines. We derive bounds for the biased teaching dimension when the learning bias is derived from a complexity measure (Kolmogorov complexity and minimal number of states respectively) and analyse the sampling distributions that lead to finite expected biased teaching dimensions. We highlight the existing trade-off between the bound and the representativeness of the sample, and its implications for the understanding of what teaching rich concepts to machines entails.
Solving MaxSAT and #SAT on structured CNF formulas
Feb 26, 2014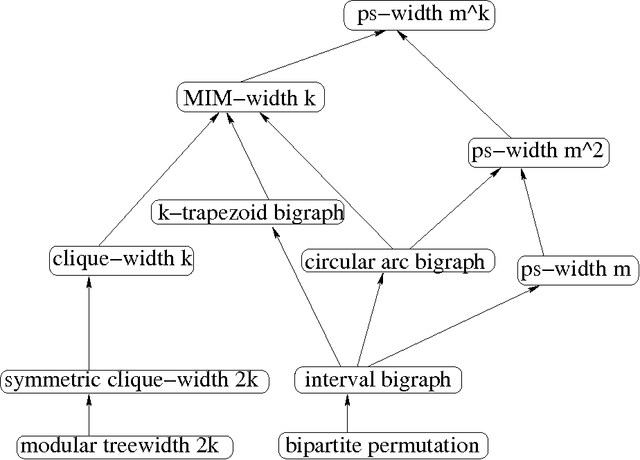
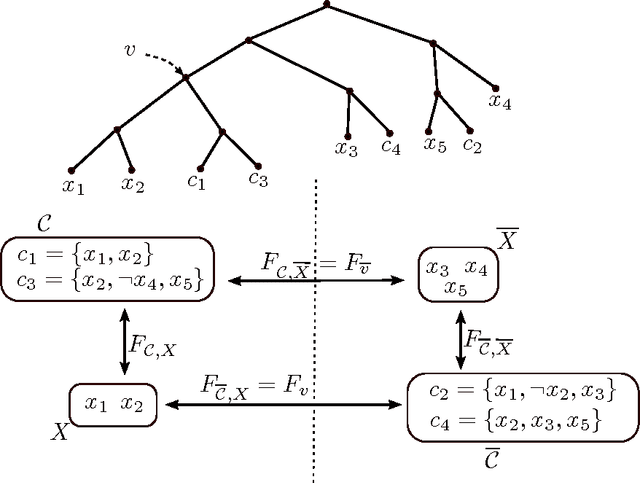
In this paper we propose a structural parameter of CNF formulas and use it to identify instances of weighted MaxSAT and #SAT that can be solved in polynomial time. Given a CNF formula we say that a set of clauses is precisely satisfiable if there is some complete assignment satisfying these clauses only. Let the ps-value of the formula be the number of precisely satisfiable sets of clauses. Applying the notion of branch decompositions to CNF formulas and using ps-value as cut function, we define the ps-width of a formula. For a formula given with a decomposition of polynomial ps-width we show dynamic programming algorithms solving weighted MaxSAT and #SAT in polynomial time. Combining with results of 'Belmonte and Vatshelle, Graph classes with structured neighborhoods and algorithmic applications, Theor. Comput. Sci. 511: 54-65 (2013)' we get polynomial-time algorithms solving weighted MaxSAT and #SAT for some classes of structured CNF formulas. For example, we get $O(m^2(m + n)s)$ algorithms for formulas $F$ of $m$ clauses and $n$ variables and size $s$, if $F$ has a linear ordering of the variables and clauses such that for any variable $x$ occurring in clause $C$, if $x$ appears before $C$ then any variable between them also occurs in $C$, and if $C$ appears before $x$ then $x$ occurs also in any clause between them. Note that the class of incidence graphs of such formulas do not have bounded clique-width.