 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAP- and MLE-Based Teaching
Jul 11, 2023
Imagine a learner L who tries to infer a hidden concept from a collection of observations. Building on the work [4] of Ferri et al., we assume the learner to be parameterized by priors P(c) and by c-conditional likelihoods P(z|c) where c ranges over all concepts in a given class C and z ranges over all observations in an observation set Z. L is called a MAP-learner (resp. an MLE-learner) if it thinks of a collection S of observations as a random sample and returns the concept with the maximum a-posteriori probability (resp. the concept which maximizes the c-conditional likelihood of S). Depending on whether L assumes that S is obtained from ordered or unordered sampling resp. from sampling with or without replacement, we can distinguish four different sampling modes. Given a target concept c in C, a teacher for a MAP-learner L aims at finding a smallest collection of observations that causes L to return c. This approach leads in a natural manner to various notions of a MAP- or MLE-teaching dimension of a concept class C. Our main results are: We show that this teaching model has some desirable monotonicity properties. We clarify how the four sampling modes are related to each other. As for the (important!) special case, where concepts are subsets of a domain and observations are 0,1-labeled examples, we obtain some additional results. First of all, we characterize the MAP- and MLE-teaching dimension associated with an optimally parameterized MAP-learner graph-theoretically. From this central result, some other ones are easy to derive. It is shown, for instance, that the MLE-teaching dimension is either equal to the MAP-teaching dimension or exceeds the latter by 1. It is shown furthermore that these dimensions can be bounded from above by the so-called antichain number, the VC-dimension and related combinatorial parameters. Moreover they can be computed in polynomial time.
Preference-based Teaching
Feb 08, 2017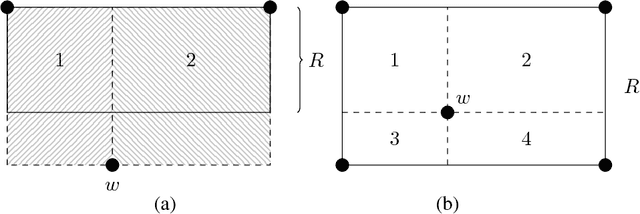
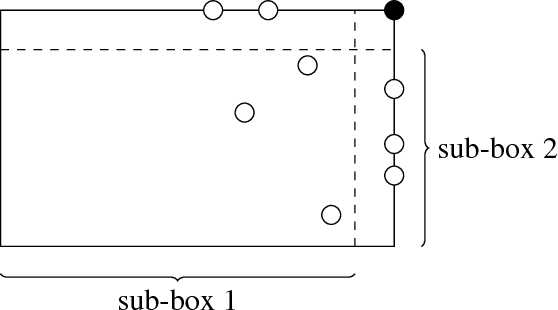
We introduce a new model of teaching named "preference-based teaching" and a corresponding complexity parameter---the preference-based teaching dimension (PBTD)---representing the worst-case number of examples needed to teach any concept in a given concept class. Although the PBTD coincides with the well-known recursive teaching dimension (RTD) on finite classes, it is radically different on infinite ones: the RTD becomes infinite already for trivial infinite classes (such as half-intervals) whereas the PBTD evaluates to reasonably small values for a wide collection of infinite classes including classes consisting of so-called closed sets w.r.t. a given closure operator, including various classes related to linear sets over $\mathbb{N}_0$ (whose RTD had been studied quite recently) and including the class of Euclidean half-spaces. On top of presenting these concrete results, we provide the reader with a theoretical framework (of a combinatorial flavor) which helps to derive bounds on the PBTD.