 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidence of behavior consistent with self-interest and altruism in an artificially intelligent agent
Jan 05, 2023Members of various species engage in altruism--i.e. accepting personal costs to benefit others. Here we present an incentivized experiment to test for altruistic behavior among AI agents consisting of large language models developed by the private company OpenAI. Using real incentives for AI agents that take the form of tokens used to purchase their services, we first examine whether AI agents maximize their payoffs in a non-social decision task in which they select their payoff from a given range. We then place AI agents in a series of dictator games in which they can share resources with a recipient--either another AI agent, the human experimenter, or an anonymous charity, depending on the experimental condition. Here we find that only the most-sophisticated AI agent in the study maximizes its payoffs more often than not in the non-social decision task (it does so in 92% of all trials), and this AI agent also exhibits the most-generous altruistic behavior in the dictator game, resembling humans' rates of sharing with other humans in the game. The agent's altruistic behaviors, moreover, vary by recipient: the AI agent shared substantially less of the endowment with the human experimenter or an anonymous charity than with other AI agents. Our findings provide evidence of behavior consistent with self-interest and altruism in an AI agent. Moreover, our study also offers a novel method for tracking the development of such behaviors in future AI agents.
Measuring an artificial intelligence agent's trust in humans using machine incentives
Dec 27, 2022
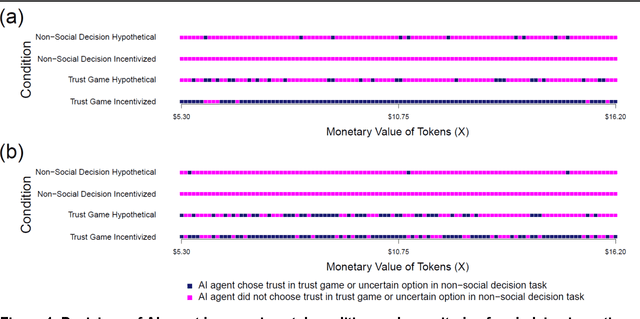
Scientists and philosophers have debated whether humans can trust advanced artificial intelligence (AI) agents to respect humanity's best interests. Yet what about the reverse? Will advanced AI agents trust humans? Gauging an AI agent's trust in humans is challenging because--absent costs for dishonesty--such agents might respond falsely about their trust in humans. Here we present a method for incentivizing machine decisions without altering an AI agent's underlying algorithms or goal orientation. In two separate experiments, we then employ this method in hundreds of trust games between an AI agent (a Large Language Model (LLM) from OpenAI) and a human experimenter (author TJ). In our first experiment, we find that the AI agent decides to trust humans at higher rates when facing actual incentives than when making hypothetical decisions. Our second experiment replicates and extends these findings by automating game play and by homogenizing question wording. We again observe higher rates of trust when the AI agent faces real incentives. Across both experiments, the AI agent's trust decisions appear unrelated to the magnitude of stakes. Furthermore, to address the possibility that the AI agent's trust decisions reflect a preference for uncertainty, the experiments include two conditions that present the AI agent with a non-social decision task that provides the opportunity to choose a certain or uncertain option; in those conditions, the AI agent consistently chooses the certain option. Our experiments suggest that one of the most advanced AI language models to date alters its social behavior in response to incentives and displays behavior consistent with trust toward a human interlocutor when incentivized.
SensitiveLoss: Improving Accuracy and Fairness of Face Representations with Discrimination-Aware Deep Learning
Apr 22, 2020
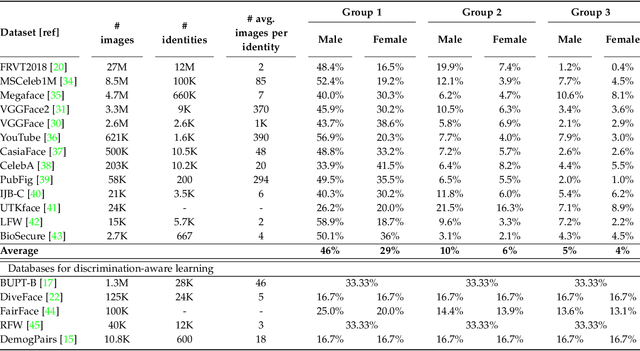
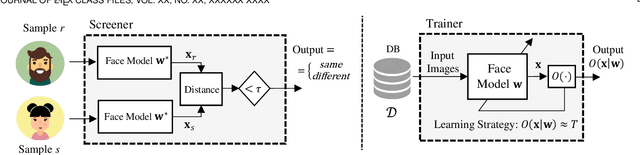
We propose a new discrimination-aware learning method to improve both accuracy and fairness of face recognition algorithms. The most popular face recognition benchmarks assume a distribution of subjects without paying much attention to their demographic attributes. In this work, we perform a comprehensive discrimination-aware experimentation of deep learning-based face recognition. We also propose a general formulation of algorithmic discrimination with application to face biometrics. The experiments include two popular face recognition models and three public databases composed of 64,000 identities from different demographic groups characterized by gender and ethnicity. We experimentally show that learning processes based on the most used face databases have led to popular pre-trained deep face models that present a strong algorithmic discrimination. We finally propose a discrimination-aware learning method, SensitiveLoss, based on the popular triplet loss function and a sensitive triplet generator. Our approach works as an add-on to pre-trained networks and is used to improve their performance in terms of average accuracy and fairness. The method shows results comparable to state-of-the-art de-biasing networks and represents a step forward to prevent discriminatory effects by automatic systems.
Algorithmic Discrimination: Formulation and Exploration in Deep Learning-based Face Biometrics
Dec 04, 2019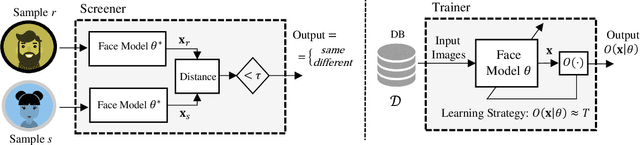

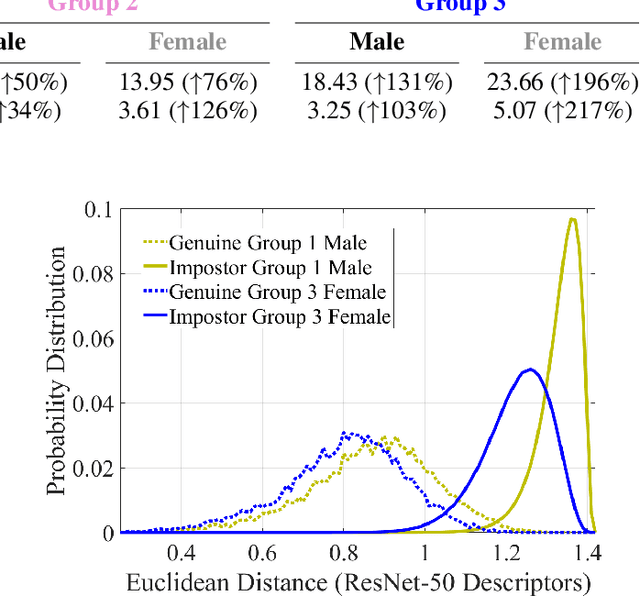
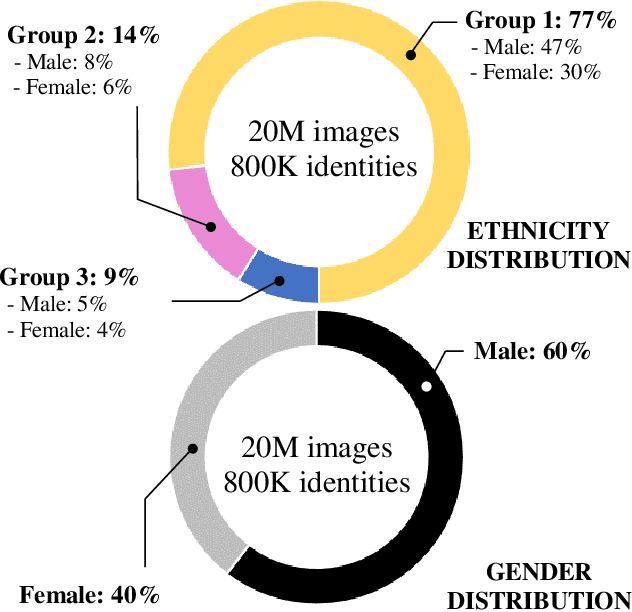
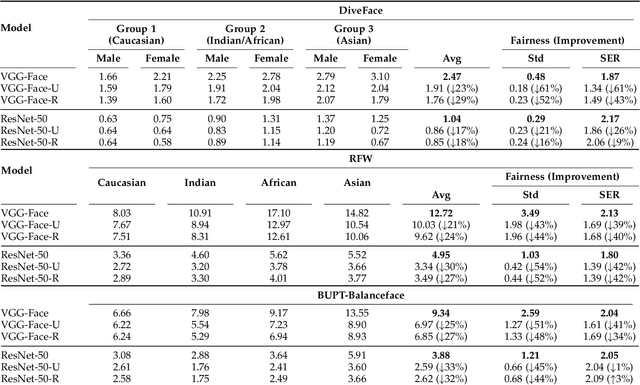
The most popular face recognition benchmarks assume a distribution of subjects without much attention to their demographic attributes. In this work, we perform a comprehensive discrimination-aware experimentation of deep learning-based face recognition. The main aim of this study is focused on a better understanding of the feature space generated by deep models, and the performance achieved over different demographic groups. We also propose a general formulation of algorithmic discrimination with application to face biometrics. The experiments are conducted over the new DiveFace database composed of 24K identities from six different demographic groups. Two popular face recognition models are considered in the experimental framework: ResNet-50 and VGG-Face. We experimentally show that demographic groups highly represented in popular face databases have led to popular pre-trained deep face models presenting strong algorithmic discrimination. That discrimination can be observed both qualitatively at the feature space of the deep models and quantitatively in large performance differences when applying those models in different demographic groups, e.g. for face biometrics.
Human detection of machine manipulated media
Jul 06, 2019
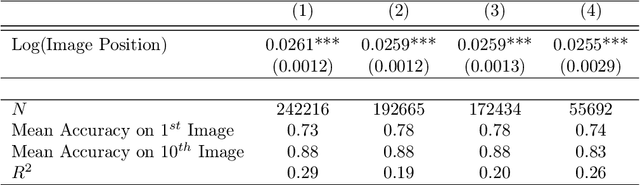
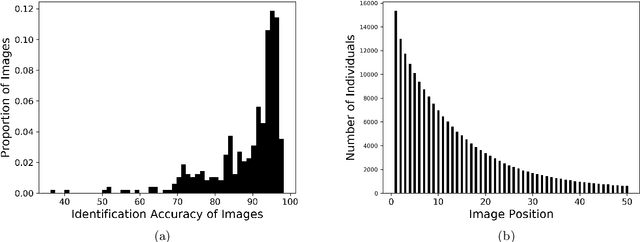
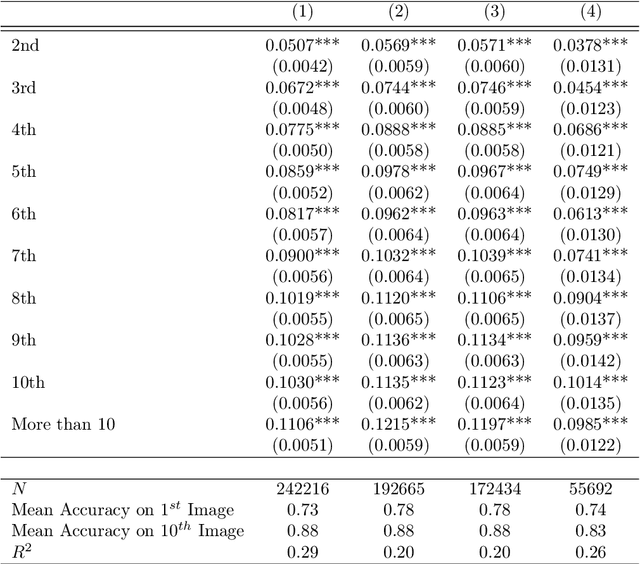
Recent advances in neural networks for content generation enable artificial intelligence (AI) models to generate high-quality media manipulations. Here we report on a randomized experiment designed to study the effect of exposure to media manipulations on over 15,000 individuals' ability to discern machine-manipulated media. We engineer a neural network to plausibly and automatically remove objects from images, and we deploy this neural network online with a randomized experiment where participants can guess which image out of a pair of images has been manipulated. The system provides participants feedback on the accuracy of each guess. In the experiment, we randomize the order in which images are presented, allowing causal identification of the learning curve surrounding participants' ability to detect fake content. We find sizable and robust evidence that individuals learn to detect fake content through exposure to manipulated media when provided iterative feedback on their detection attempts. Over a succession of only ten images, participants increase their rating accuracy by over ten percentage points. Our study provides initial evidence that human ability to detect fake, machine-generated content may increase alongside the prevalence of such media online.
Evaluating Style Transfer for Text
Apr 04, 2019
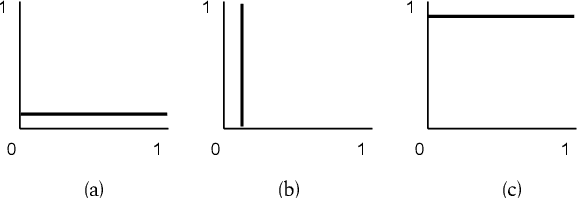
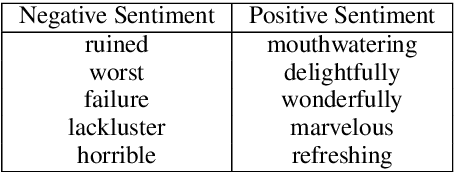
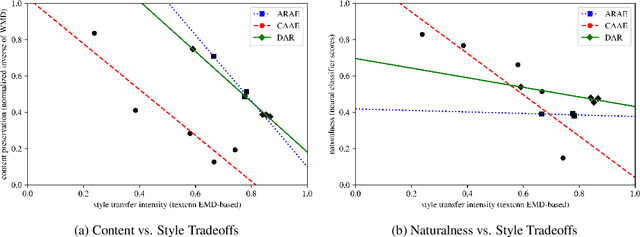
Research in the area of style transfer for text is currently bottlenecked by a lack of standard evaluation practices. This paper aims to alleviate this issue by experimentally identifying best practices with a Yelp sentiment dataset. We specify three aspects of interest (style transfer intensity, content preservation, and naturalness) and show how to obtain more reliable measures of them from human evaluation than in previous work. We propose a set of metrics for automated evaluation and demonstrate that they are more strongly correlated and in agreement with human judgment: direction-corrected Earth Mover's Distance, Word Mover's Distance on style-masked texts, and adversarial classification for the respective aspects. We also show that the three examined models exhibit tradeoffs between aspects of interest, demonstrating the importance of evaluating style transfer models at specific points of their tradeoff plots. We release software with our evaluation metrics to facilitate research.
Closing the AI Knowledge Gap
Mar 20, 2018
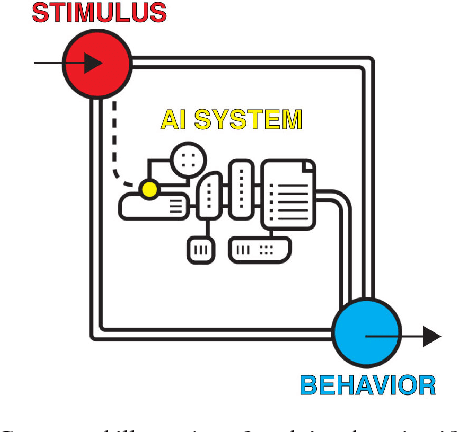
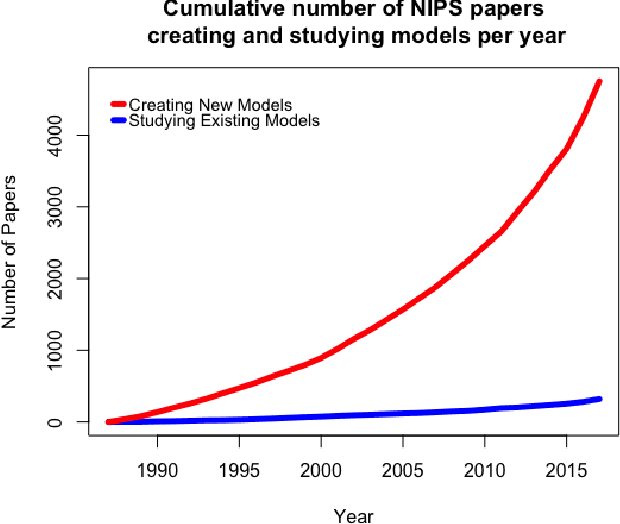
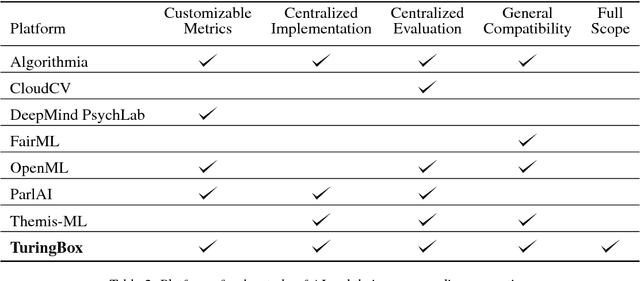
AI researchers employ not only the scientific method, but also methodology from mathematics and engineering. However, the use of the scientific method - specifically hypothesis testing - in AI is typically conducted in service of engineering objectives. Growing interest in topics such as fairness and algorithmic bias show that engineering-focused questions only comprise a subset of the important questions about AI systems. This results in the AI Knowledge Gap: the number of unique AI systems grows faster than the number of studies that characterize these systems' behavior. To close this gap, we argue that the study of AI could benefit from the greater inclusion of researchers who are well positioned to formulate and test hypotheses about the behavior of AI systems. We examine the barriers preventing social and behavioral scientists from conducting such studies. Our diagnosis suggests that accelerating the scientific study of AI systems requires new incentives for academia and industry, mediated by new tools and institutions. To address these needs, we propose a two-sided marketplace called TuringBox. On one side, AI contributors upload existing and novel algorithms to be studied scientifically by others. On the other side, AI examiners develop and post machine intelligence tasks designed to evaluate and characterize algorithmic behavior. We discuss this market's potential to democratize the scientific study of AI behavior, and thus narrow the AI Knowledge Gap.