 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Style Transfer for Text
Apr 04, 2019
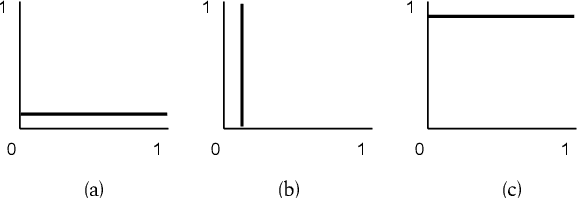
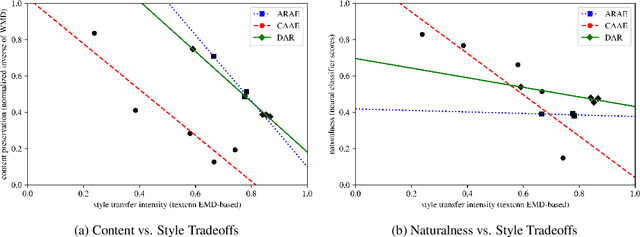
Research in the area of style transfer for text is currently bottlenecked by a lack of standard evaluation practices. This paper aims to alleviate this issue by experimentally identifying best practices with a Yelp sentiment dataset. We specify three aspects of interest (style transfer intensity, content preservation, and naturalness) and show how to obtain more reliable measures of them from human evaluation than in previous work. We propose a set of metrics for automated evaluation and demonstrate that they are more strongly correlated and in agreement with human judgment: direction-corrected Earth Mover's Distance, Word Mover's Distance on style-masked texts, and adversarial classification for the respective aspects. We also show that the three examined models exhibit tradeoffs between aspects of interest, demonstrating the importance of evaluating style transfer models at specific points of their tradeoff plots. We release software with our evaluation metrics to facilitate research.
Comparing Models of Associative Meaning: An Empirical Investigation of Reference in Simple Language Games
Oct 08, 2018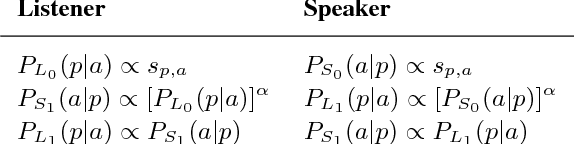
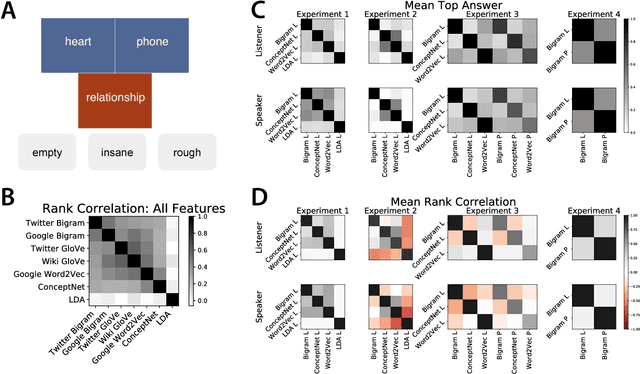
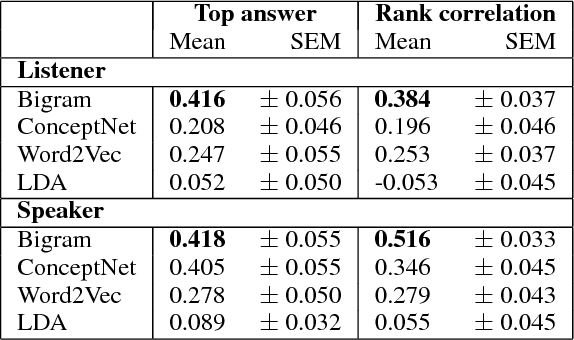
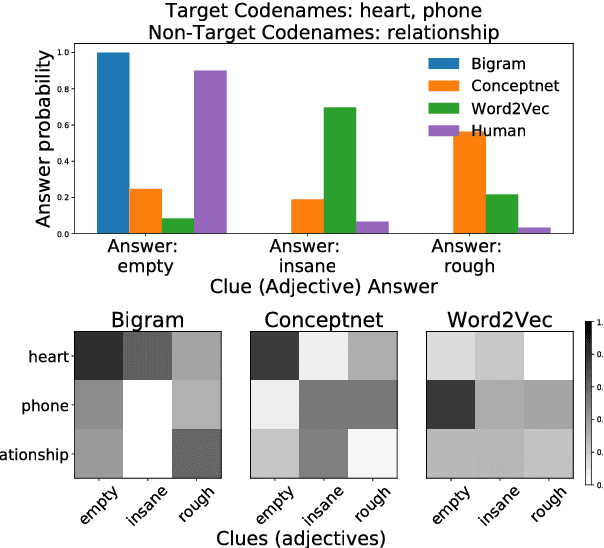
Simple reference games are of central theoretical and empirical importance in the study of situated language use. Although language provides rich, compositional truth-conditional semantics to facilitate reference, speakers and listeners may sometimes lack the overall lexical and cognitive resources to guarantee successful reference through these means alone. However, language also has rich associational structures that can serve as a further resource for achieving successful reference. Here we investigate this use of associational information in a setting where only associational information is available: a simplified version of the popular game Codenames. Using optimal experiment design techniques, we compare a range of models varying in the type of associative information deployed and in level of pragmatic sophistication against human behavior. In this setting, we find that listeners' behavior reflects direct bigram collocational associations more strongly than word-embedding or semantic knowledge graph-based associations and that there is little evidence for pragmatically sophisticated behavior by either speakers or listeners of the type that might be predicted by recursive-reasoning models such as the Rational Speech Acts theory. These results shed light on the nature of the lexical resources that speakers and listeners can bring to bear in achieving reference through associative meaning alone.
Closing the AI Knowledge Gap
Mar 20, 2018
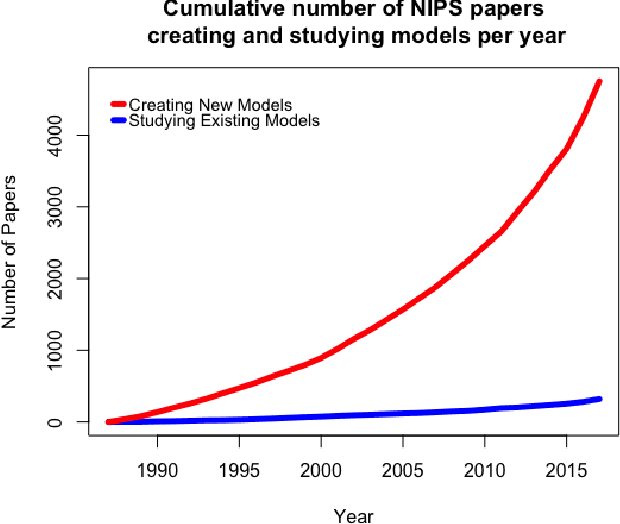
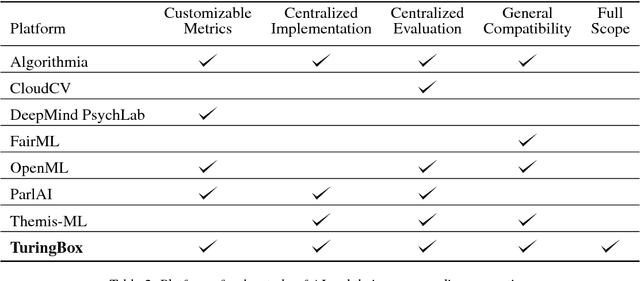
AI researchers employ not only the scientific method, but also methodology from mathematics and engineering. However, the use of the scientific method - specifically hypothesis testing - in AI is typically conducted in service of engineering objectives. Growing interest in topics such as fairness and algorithmic bias show that engineering-focused questions only comprise a subset of the important questions about AI systems. This results in the AI Knowledge Gap: the number of unique AI systems grows faster than the number of studies that characterize these systems' behavior. To close this gap, we argue that the study of AI could benefit from the greater inclusion of researchers who are well positioned to formulate and test hypotheses about the behavior of AI systems. We examine the barriers preventing social and behavioral scientists from conducting such studies. Our diagnosis suggests that accelerating the scientific study of AI systems requires new incentives for academia and industry, mediated by new tools and institutions. To address these needs, we propose a two-sided marketplace called TuringBox. On one side, AI contributors upload existing and novel algorithms to be studied scientifically by others. On the other side, AI examiners develop and post machine intelligence tasks designed to evaluate and characterize algorithmic behavior. We discuss this market's potential to democratize the scientific study of AI behavior, and thus narrow the AI Knowledge Gap.
Modeling the Temporal Nature of Human Behavior for Demographics Prediction
Nov 15, 2017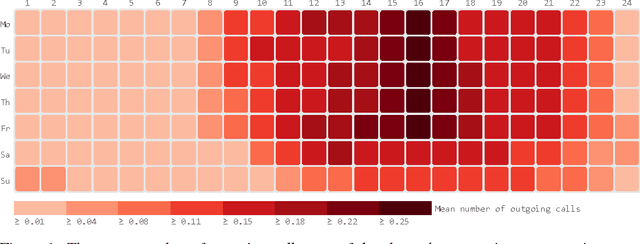
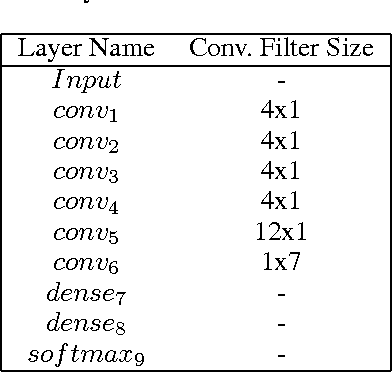
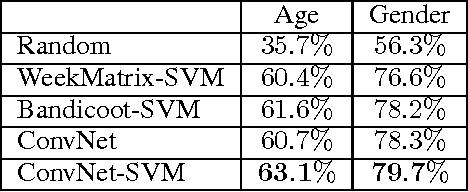

Mobile phone metadata is increasingly used for humanitarian purposes in developing countries as traditional data is scarce. Basic demographic information is however often absent from mobile phone datasets, limiting the operational impact of the datasets. For these reasons, there has been a growing interest in predicting demographic information from mobile phone metadata. Previous work focused on creating increasingly advanced features to be modeled with standard machine learning algorithms. We here instead model the raw mobile phone metadata directly using deep learning, exploiting the temporal nature of the patterns in the data. From high-level assumptions we design a data representation and convolutional network architecture for modeling patterns within a week. We then examine three strategies for aggregating patterns across weeks and show that our method reaches state-of-the-art accuracy on both age and gender prediction using only the temporal modality in mobile metadata. We finally validate our method on low activity users and evaluate the modeling assumptions.
A First Step in Combining Cognitive Event Features and Natural Language Representations to Predict Emotions
Oct 23, 2017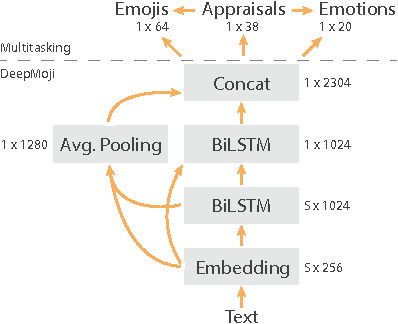

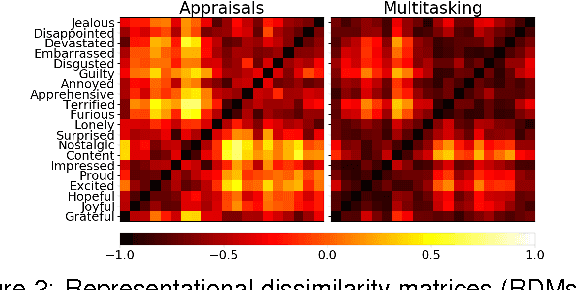
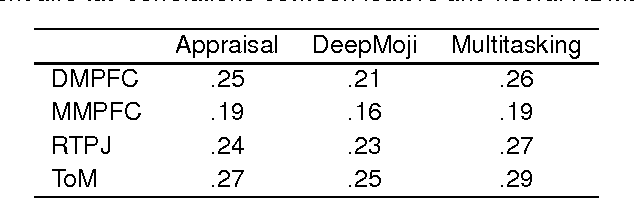
We explore the representational space of emotions by combining methods from different academic fields. Cognitive science has proposed appraisal theory as a view on human emotion with previous research showing how human-rated abstract event features can predict fine-grained emotions and capture the similarity space of neural patterns in mentalizing brain regions. At the same time, natural language processing (NLP) has demonstrated how transfer and multitask learning can be used to cope with scarcity of annotated data for text modeling. The contribution of this work is to show that appraisal theory can be combined with NLP for mutual benefit. First, fine-grained emotion prediction can be improved to human-level performance by using NLP representations in addition to appraisal features. Second, using the appraisal features as auxiliary targets during training can improve predictions even when only text is available as input. Third, we obtain a representation with a similarity matrix that better correlates with the neural activity across regions. Best results are achieved when the model is trained to simultaneously predict appraisals, emotions and emojis using a shared representation. While these results are preliminary, the integration of cognitive neuroscience and NLP techniques opens up an interesting direction for future research.
Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm
Oct 07, 2017
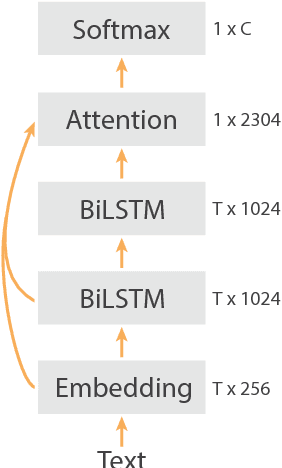
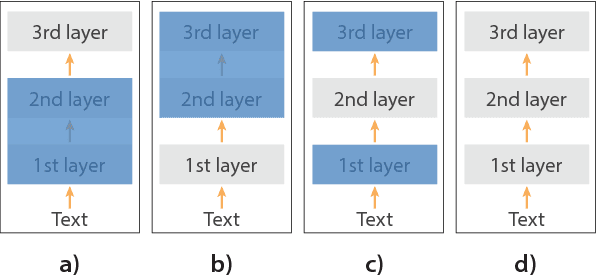
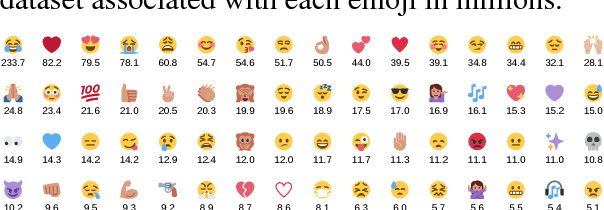
NLP tasks are often limited by scarcity of manually annotated data. In social media sentiment analysis and related tasks, researchers have therefore used binarized emoticons and specific hashtags as forms of distant supervision. Our paper shows that by extending the distant supervision to a more diverse set of noisy labels, the models can learn richer representations. Through emoji prediction on a dataset of 1246 million tweets containing one of 64 common emojis we obtain state-of-the-art performance on 8 benchmark datasets within sentiment, emotion and sarcasm detection using a single pretrained model. Our analyses confirm that the diversity of our emotional labels yield a performance improvement over previous distant supervision approaches.