 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReport on Candidate Computational Indicators for Conscious Valenced Experience
Apr 25, 2024This report enlists 13 functional conditions cashed out in computational terms that have been argued to be constituent of conscious valenced experience. These are extracted from existing empirical and theoretical literature on, among others, animal sentience, medical disorders, anaesthetics, philosophy, evolution, neuroscience, and artificial intelligence.
A Test for Evaluating Performance in Human-Computer Systems
Jun 28, 2022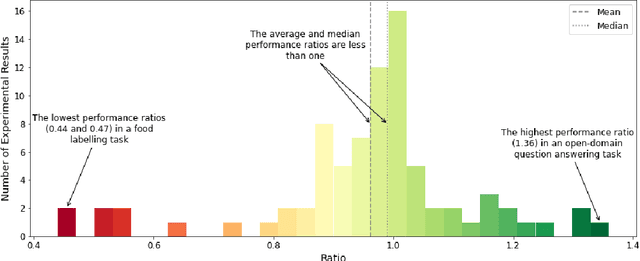
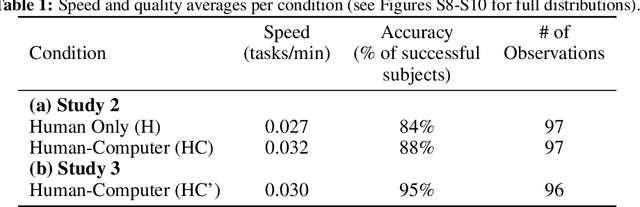

The Turing test for comparing computer performance to that of humans is well known, but, surprisingly, there is no widely used test for comparing how much better human-computer systems perform relative to humans alone, computers alone, or other baselines. Here, we show how to perform such a test using the ratio of means as a measure of effect size. Then we demonstrate the use of this test in three ways. First, in an analysis of 79 recently published experimental results, we find that, surprisingly, over half of the studies find a decrease in performance, the mean and median ratios of performance improvement are both approximately 1 (corresponding to no improvement at all), and the maximum ratio is 1.36 (a 36% improvement). Second, we experimentally investigate whether a higher performance improvement ratio is obtained when 100 human programmers generate software using GPT-3, a massive, state-of-the-art AI system. In this case, we find a speed improvement ratio of 1.27 (a 27% improvement). Finally, we find that 50 human non-programmers using GPT-3 can perform the task about as well as--and less expensively than--the human programmers. In this case, neither the non-programmers nor the computer would have been able to perform the task alone, so this is an example of a very strong form of human-computer synergy.
Human-Level Reinforcement Learning through Theory-Based Modeling, Exploration, and Planning
Jul 27, 2021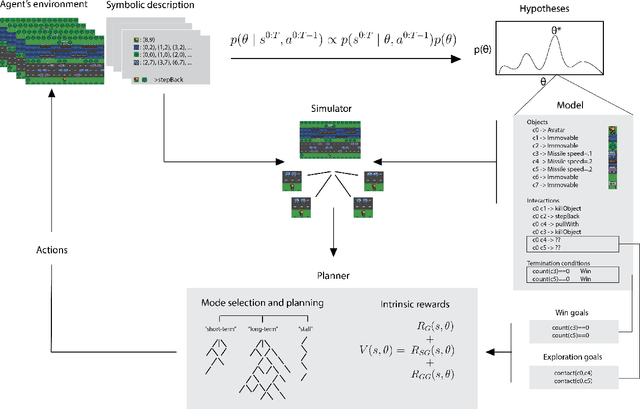
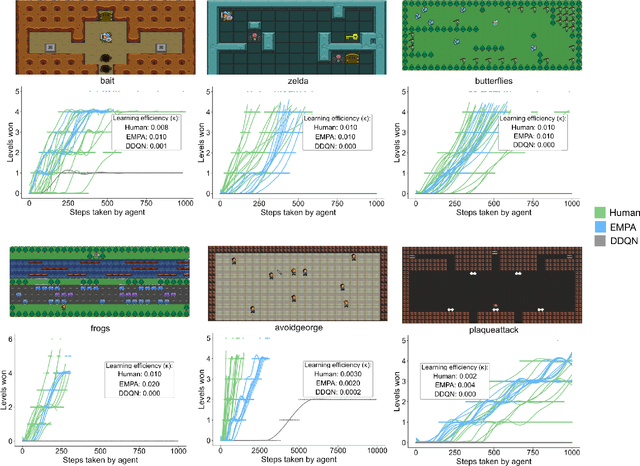
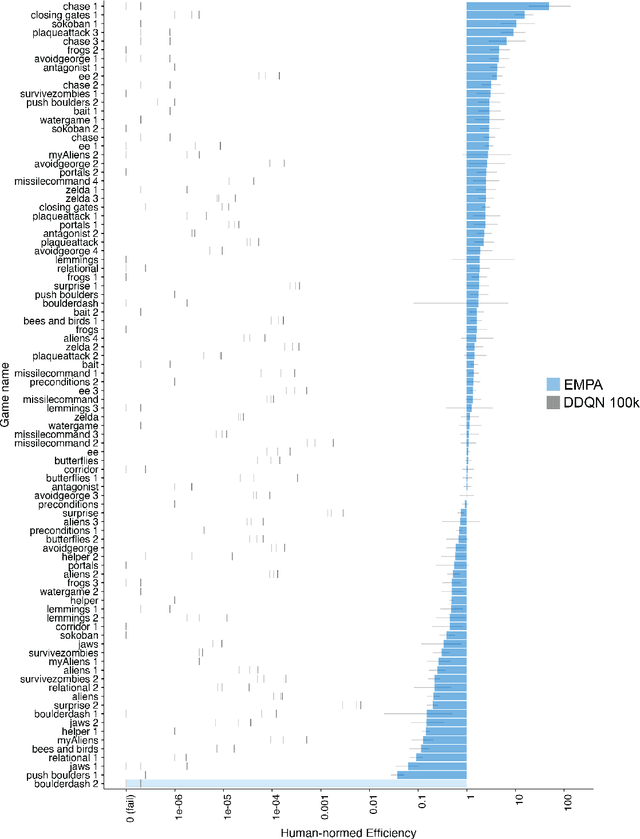
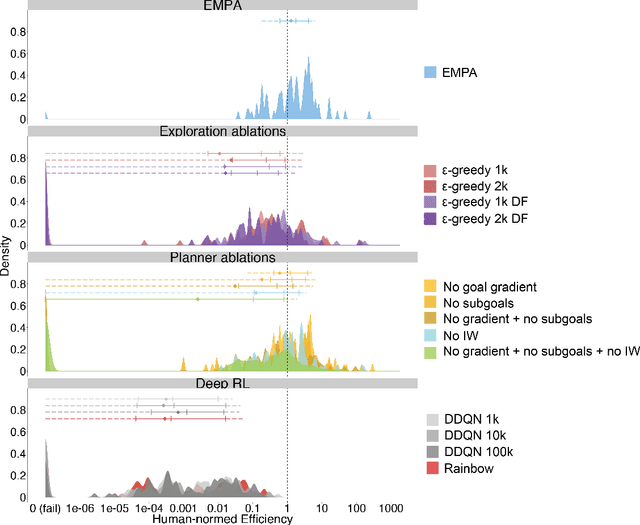
Reinforcement learning (RL) studies how an agent comes to achieve reward in an environment through interactions over time. Recent advances in machine RL have surpassed human expertise at the world's oldest board games and many classic video games, but they require vast quantities of experience to learn successfully -- none of today's algorithms account for the human ability to learn so many different tasks, so quickly. Here we propose a new approach to this challenge based on a particularly strong form of model-based RL which we call Theory-Based Reinforcement Learning, because it uses human-like intuitive theories -- rich, abstract, causal models of physical objects, intentional agents, and their interactions -- to explore and model an environment, and plan effectively to achieve task goals. We instantiate the approach in a video game playing agent called EMPA (the Exploring, Modeling, and Planning Agent), which performs Bayesian inference to learn probabilistic generative models expressed as programs for a game-engine simulator, and runs internal simulations over these models to support efficient object-based, relational exploration and heuristic planning. EMPA closely matches human learning efficiency on a suite of 90 challenging Atari-style video games, learning new games in just minutes of game play and generalizing robustly to new game situations and new levels. The model also captures fine-grained structure in people's exploration trajectories and learning dynamics. Its design and behavior suggest a way forward for building more general human-like AI systems.
Learning with AMIGo: Adversarially Motivated Intrinsic Goals
Jun 22, 2020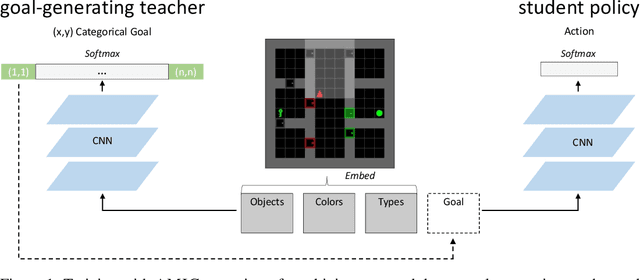
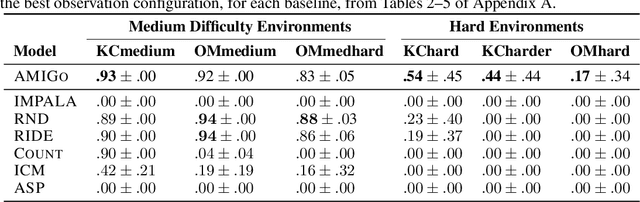
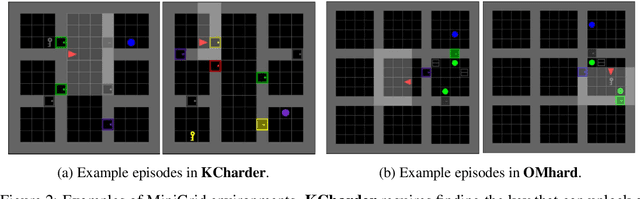
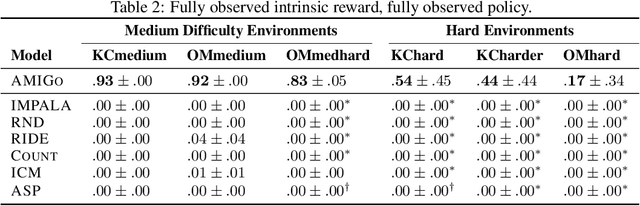
A key challenge for reinforcement learning (RL) consists of learning in environments with sparse extrinsic rewards. In contrast to current RL methods, humans are able to learn new skills with little or no reward by using various forms of intrinsic motivation. We propose AMIGo, a novel agent incorporating a goal-generating teacher that proposes Adversarially Motivated Intrinsic Goals to train a goal-conditioned "student" policy in the absence of (or alongside) environment reward. Specifically, through a simple but effective "constructively adversarial" objective, the teacher learns to propose increasingly challenging---yet achievable---goals that allow the student to learn general skills for acting in a new environment, independent of the task to be solved. We show that our method generates a natural curriculum of self-proposed goals which ultimately allows the agent to solve challenging procedurally-generated tasks where other forms of intrinsic motivation and state-of-the-art RL methods fail.
Logical Rule Induction and Theory Learning Using Neural Theorem Proving
Sep 12, 2018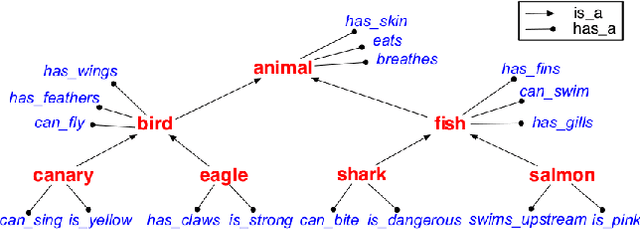
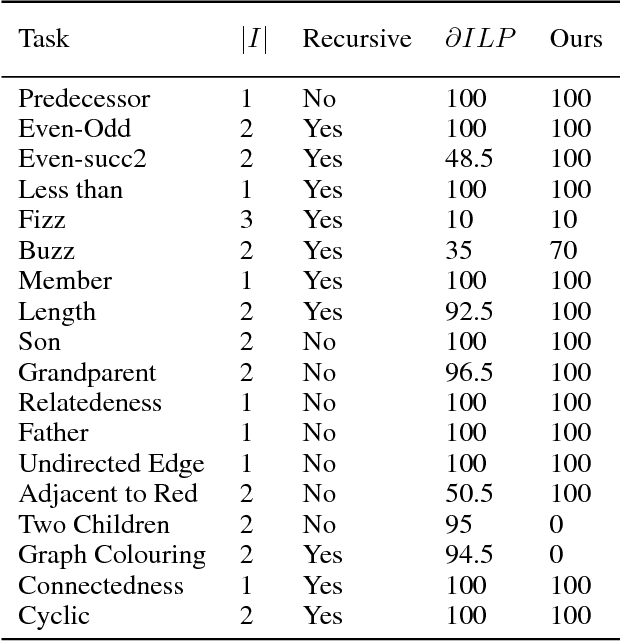
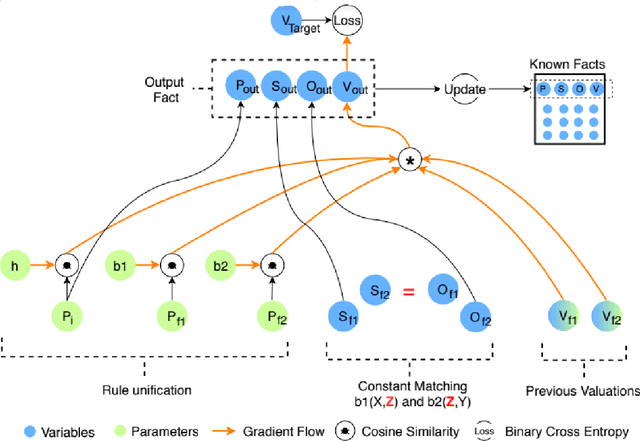
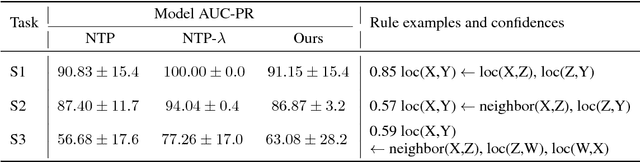
A hallmark of human cognition is the ability to continually acquire and distill observations of the world into meaningful, predictive theories. In this paper we present a new mechanism for logical theory acquisition which takes a set of observed facts and learns to extract from them a set of logical rules and a small set of core facts which together entail the observations. Our approach is neuro-symbolic in the sense that the rule pred- icates and core facts are given dense vector representations. The rules are applied to the core facts using a soft unification procedure to infer additional facts. After k steps of forward inference, the consequences are compared to the initial observations and the rules and core facts are then encouraged towards representations that more faithfully generate the observations through inference. Our approach is based on a novel neural forward-chaining differentiable rule induction network. The rules are interpretable and learned compositionally from their predicates, which may be invented. We demonstrate the efficacy of our approach on a variety of ILP rule induction and domain theory learning datasets.
A First Step in Combining Cognitive Event Features and Natural Language Representations to Predict Emotions
Oct 23, 2017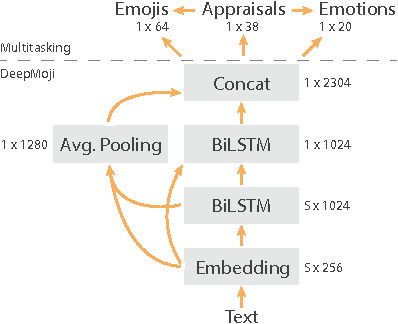

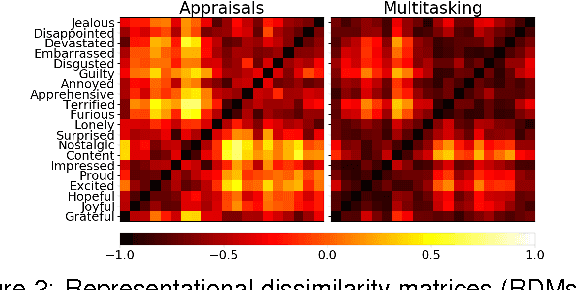
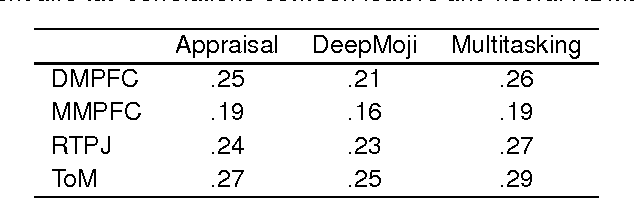
We explore the representational space of emotions by combining methods from different academic fields. Cognitive science has proposed appraisal theory as a view on human emotion with previous research showing how human-rated abstract event features can predict fine-grained emotions and capture the similarity space of neural patterns in mentalizing brain regions. At the same time, natural language processing (NLP) has demonstrated how transfer and multitask learning can be used to cope with scarcity of annotated data for text modeling. The contribution of this work is to show that appraisal theory can be combined with NLP for mutual benefit. First, fine-grained emotion prediction can be improved to human-level performance by using NLP representations in addition to appraisal features. Second, using the appraisal features as auxiliary targets during training can improve predictions even when only text is available as input. Third, we obtain a representation with a similarity matrix that better correlates with the neural activity across regions. Best results are achieved when the model is trained to simultaneously predict appraisals, emotions and emojis using a shared representation. While these results are preliminary, the integration of cognitive neuroscience and NLP techniques opens up an interesting direction for future research.