 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Gamestore: Scalable, Open-Ended Evaluation of Machine General Intelligence with Human Games
Feb 19, 2026Rigorously evaluating machine intelligence against the broad spectrum of human general intelligence has become increasingly important and challenging in this era of rapid technological advance. Conventional AI benchmarks typically assess only narrow capabilities in a limited range of human activity. Most are also static, quickly saturating as developers explicitly or implicitly optimize for them. We propose that a more promising way to evaluate human-like general intelligence in AI systems is through a particularly strong form of general game playing: studying how and how well they play and learn to play \textbf{all conceivable human games}, in comparison to human players with the same level of experience, time, or other resources. We define a "human game" to be a game designed by humans for humans, and argue for the evaluative suitability of this space of all such games people can imagine and enjoy -- the "Multiverse of Human Games". Taking a first step towards this vision, we introduce the AI GameStore, a scalable and open-ended platform that uses LLMs with humans-in-the-loop to synthesize new representative human games, by automatically sourcing and adapting standardized and containerized variants of game environments from popular human digital gaming platforms. As a proof of concept, we generated 100 such games based on the top charts of Apple App Store and Steam, and evaluated seven frontier vision-language models (VLMs) on short episodes of play. The best models achieved less than 10\% of the human average score on the majority of the games, and especially struggled with games that challenge world-model learning, memory and planning. We conclude with a set of next steps for building out the AI GameStore as a practical way to measure and drive progress toward human-like general intelligence in machines.
Learning Abstractions for Hierarchical Planning in Program-Synthesis Agents
Jan 31, 2026Humans learn abstractions and use them to plan efficiently to quickly generalize across tasks -- an ability that remains challenging for state-of-the-art large language model (LLM) agents and deep reinforcement learning (RL) systems. Inspired by the cognitive science of how people form abstractions and intuitive theories of their world knowledge, Theory-Based RL (TBRL) systems, such as TheoryCoder, exhibit strong generalization through effective use of abstractions. However, they heavily rely on human-provided abstractions and sidestep the abstraction-learning problem. We introduce TheoryCoder-2, a new TBRL agent that leverages LLMs' in-context learning ability to actively learn reusable abstractions rather than relying on hand-specified ones, by synthesizing abstractions from experience and integrating them into a hierarchical planning process. We conduct experiments on diverse environments, including BabyAI, Minihack and VGDL games like Sokoban. We find that TheoryCoder-2 is significantly more sample-efficient than baseline LLM agents augmented with classical planning domain construction, reasoning-based planning, and prior program-synthesis agents such as WorldCoder. TheoryCoder-2 is able to solve complex tasks that the baselines fail, while only requiring minimal human prompts, unlike prior TBRL systems.
Subjective functions
Dec 17, 2025Where do objective functions come from? How do we select what goals to pursue? Human intelligence is adept at synthesizing new objective functions on the fly. How does this work, and can we endow artificial systems with the same ability? This paper proposes an approach to answering these questions, starting with the concept of a subjective function, a higher-order objective function that is endogenous to the agent (i.e., defined with respect to the agent's features, rather than an external task). Expected prediction error is studied as a concrete example of a subjective function. This proposal has many connections to ideas in psychology, neuroscience, and machine learning.
Gradient Descent as Loss Landscape Navigation: a Normative Framework for Deriving Learning Rules
Oct 30, 2025Learning rules -- prescriptions for updating model parameters to improve performance -- are typically assumed rather than derived. Why do some learning rules work better than others, and under what assumptions can a given rule be considered optimal? We propose a theoretical framework that casts learning rules as policies for navigating (partially observable) loss landscapes, and identifies optimal rules as solutions to an associated optimal control problem. A range of well-known rules emerge naturally within this framework under different assumptions: gradient descent from short-horizon optimization, momentum from longer-horizon planning, natural gradients from accounting for parameter space geometry, non-gradient rules from partial controllability, and adaptive optimizers like Adam from online Bayesian inference of loss landscape shape. We further show that continual learning strategies like weight resetting can be understood as optimal responses to task uncertainty. By unifying these phenomena under a single objective, our framework clarifies the computational structure of learning and offers a principled foundation for designing adaptive algorithms.
Fast weight programming and linear transformers: from machine learning to neurobiology
Aug 11, 2025Recent advances in artificial neural networks for machine learning, and language modeling in particular, have established a family of recurrent neural network (RNN) architectures that, unlike conventional RNNs with vector-form hidden states, use two-dimensional (2D) matrix-form hidden states. Such 2D-state RNNs, known as Fast Weight Programmers (FWPs), can be interpreted as a neural network whose synaptic weights (called fast weights) dynamically change over time as a function of input observations, and serve as short-term memory storage; corresponding synaptic weight modifications are controlled or programmed by another network (the programmer) whose parameters are trained (e.g., by gradient descent). In this Primer, we review the technical foundations of FWPs, their computational characteristics, and their connections to transformers and state space models. We also discuss connections between FWPs and models of synaptic plasticity in the brain, suggesting a convergence of natural and artificial intelligence.
Synthesizing world models for bilevel planning
Mar 26, 2025Modern reinforcement learning (RL) systems have demonstrated remarkable capabilities in complex environments, such as video games. However, they still fall short of achieving human-like sample efficiency and adaptability when learning new domains. Theory-based reinforcement learning (TBRL) is an algorithmic framework specifically designed to address this gap. Modeled on cognitive theories, TBRL leverages structured, causal world models - "theories" - as forward simulators for use in planning, generalization and exploration. Although current TBRL systems provide compelling explanations of how humans learn to play video games, they face several technical limitations: their theory languages are restrictive, and their planning algorithms are not scalable. To address these challenges, we introduce TheoryCoder, an instantiation of TBRL that exploits hierarchical representations of theories and efficient program synthesis methods for more powerful learning and planning. TheoryCoder equips agents with general-purpose abstractions (e.g., "move to"), which are then grounded in a particular environment by learning a low-level transition model (a Python program synthesized from observations by a large language model). A bilevel planning algorithm can exploit this hierarchical structure to solve large domains. We demonstrate that this approach can be successfully applied to diverse and challenging grid-world games, where approaches based on directly synthesizing a policy perform poorly. Ablation studies demonstrate the benefits of using hierarchical abstractions.
General Reasoning Requires Learning to Reason from the Get-go
Feb 26, 2025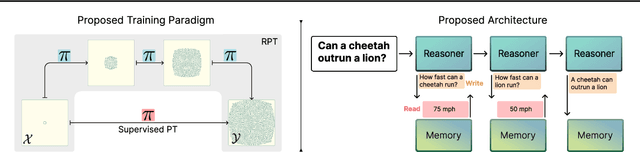
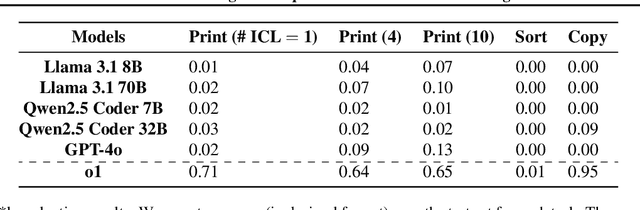
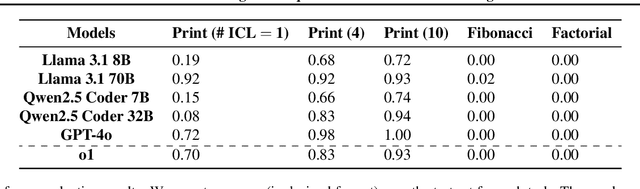
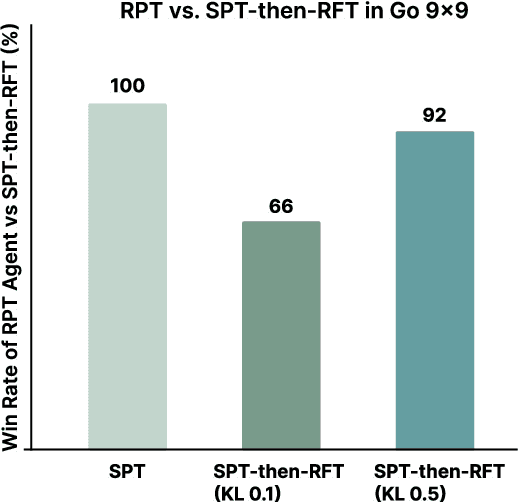
Large Language Models (LLMs) have demonstrated impressive real-world utility, exemplifying artificial useful intelligence (AUI). However, their ability to reason adaptively and robustly -- the hallmarks of artificial general intelligence (AGI) -- remains fragile. While LLMs seemingly succeed in commonsense reasoning, programming, and mathematics, they struggle to generalize algorithmic understanding across novel contexts. Our experiments with algorithmic tasks in esoteric programming languages reveal that LLM's reasoning overfits to the training data and is limited in its transferability. We hypothesize that the core issue underlying such limited transferability is the coupling of reasoning and knowledge in LLMs. To transition from AUI to AGI, we propose disentangling knowledge and reasoning through three key directions: (1) pretaining to reason using RL from scratch as an alternative to the widely used next-token prediction pretraining, (2) using a curriculum of synthetic tasks to ease the learning of a \textit{reasoning prior} for RL that can then be transferred to natural language tasks, and (3) learning more generalizable reasoning functions using a small context window to reduce exploiting spurious correlations between tokens. Such a reasoning system coupled with a trained retrieval system and a large external memory bank as a knowledge store can overcome several limitations of existing architectures at learning to reason in novel scenarios.
Key-value memory in the brain
Jan 06, 2025


Classical models of memory in psychology and neuroscience rely on similarity-based retrieval of stored patterns, where similarity is a function of retrieval cues and the stored patterns. While parsimonious, these models do not allow distinct representations for storage and retrieval, despite their distinct computational demands. Key-value memory systems, in contrast, distinguish representations used for storage (values) and those used for retrieval (keys). This allows key-value memory systems to optimize simultaneously for fidelity in storage and discriminability in retrieval. We review the computational foundations of key-value memory, its role in modern machine learning systems, related ideas from psychology and neuroscience, applications to a number of empirical puzzles, and possible biological implementations.
Do Mice Grok? Glimpses of Hidden Progress During Overtraining in Sensory Cortex
Nov 05, 2024



Does learning of task-relevant representations stop when behavior stops changing? Motivated by recent theoretical advances in machine learning and the intuitive observation that human experts continue to learn from practice even after mastery, we hypothesize that task-specific representation learning can continue, even when behavior plateaus. In a novel reanalysis of recently published neural data, we find evidence for such learning in posterior piriform cortex of mice following continued training on a task, long after behavior saturates at near-ceiling performance ("overtraining"). This learning is marked by an increase in decoding accuracy from piriform neural populations and improved performance on held-out generalization tests. We demonstrate that class representations in cortex continue to separate during overtraining, so that examples that were incorrectly classified at the beginning of overtraining can abruptly be correctly classified later on, despite no changes in behavior during that time. We hypothesize this hidden yet rich learning takes the form of approximate margin maximization; we validate this and other predictions in the neural data, as well as build and interpret a simple synthetic model that recapitulates these phenomena. We conclude by showing how this model of late-time feature learning implies an explanation for the empirical puzzle of overtraining reversal in animal learning, where task-specific representations are more robust to particular task changes because the learned features can be reused.
Artificial intelligence for science: The easy and hard problems
Aug 24, 2024
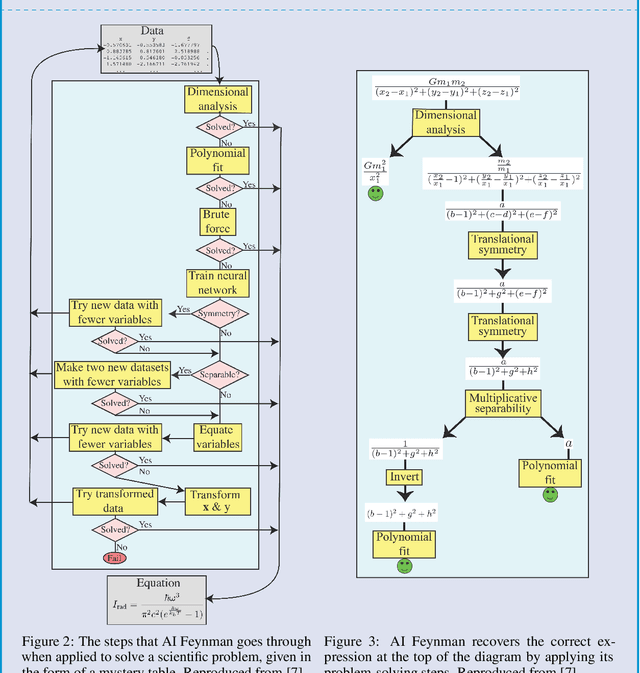

A suite of impressive scientific discoveries have been driven by recent advances in artificial intelligence. These almost all result from training flexible algorithms to solve difficult optimization problems specified in advance by teams of domain scientists and engineers with access to large amounts of data. Although extremely useful, this kind of problem solving only corresponds to one part of science - the "easy problem." The other part of scientific research is coming up with the problem itself - the "hard problem." Solving the hard problem is beyond the capacities of current algorithms for scientific discovery because it requires continual conceptual revision based on poorly defined constraints. We can make progress on understanding how humans solve the hard problem by studying the cognitive science of scientists, and then use the results to design new computational agents that automatically infer and update their scientific paradigms.