 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Robustness and Functional Localization in Topographic CNNs Through Weight Similarity
Jul 31, 2025Topographic neural networks are computational models that can simulate the spatial and functional organization of the brain. Topographic constraints in neural networks can be implemented in multiple ways, with potentially different impacts on the representations learned by the network. The impact of such different implementations has not been systematically examined. To this end, here we compare topographic convolutional neural networks trained with two spatial constraints: Weight Similarity (WS), which pushes neighboring units to develop similar incoming weights, and Activation Similarity (AS), which enforces similarity in unit activations. We evaluate the resulting models on classification accuracy, robustness to weight perturbations and input degradation, and the spatial organization of learned representations. Compared to both AS and standard CNNs, WS provided three main advantages: i) improved robustness to noise, also showing higher accuracy under weight corruption; ii) greater input sensitivity, reflected in higher activation variance; and iii) stronger functional localization, with units showing similar activations positioned at closer distances. In addition, WS produced differences in orientation tuning, symmetry sensitivity, and eccentricity profiles of units, indicating an influence of this spatial constraint on the representational geometry of the network. Our findings suggest that during end-to-end training, WS constraints produce more robust representations than AS or non-topographic CNNs. These findings also suggest that weight-based spatial constraints can shape feature learning and functional organization in biophysical inspired models.
Assessing Episodic Memory in LLMs with Sequence Order Recall Tasks
Oct 10, 2024
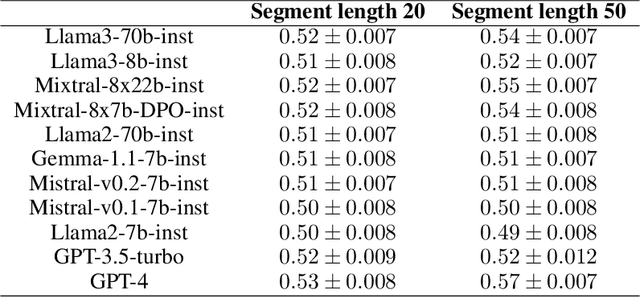
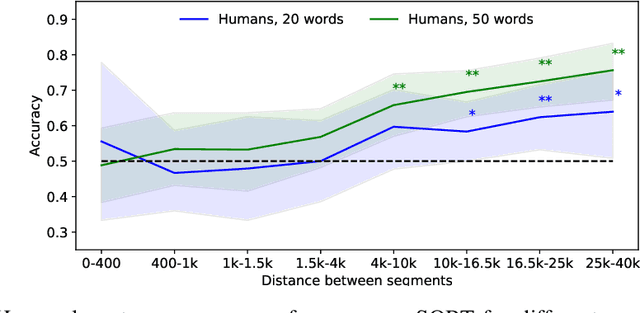
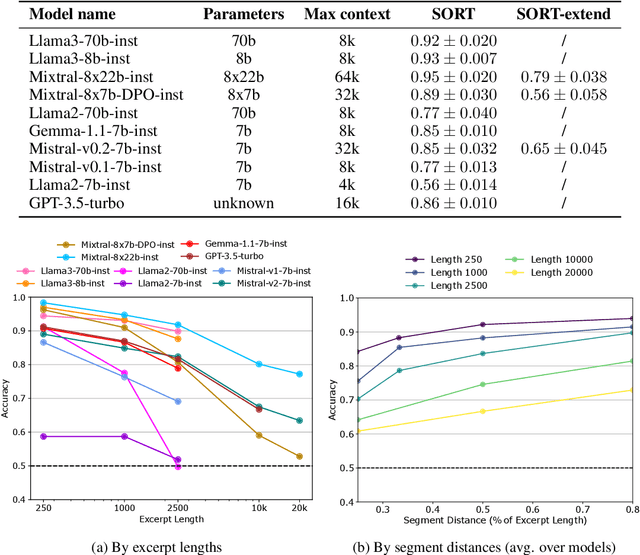
Current LLM benchmarks focus on evaluating models' memory of facts and semantic relations, primarily assessing semantic aspects of long-term memory. However, in humans, long-term memory also includes episodic memory, which links memories to their contexts, such as the time and place they occurred. The ability to contextualize memories is crucial for many cognitive tasks and everyday functions. This form of memory has not been evaluated in LLMs with existing benchmarks. To address the gap in evaluating memory in LLMs, we introduce Sequence Order Recall Tasks (SORT), which we adapt from tasks used to study episodic memory in cognitive psychology. SORT requires LLMs to recall the correct order of text segments, and provides a general framework that is both easily extendable and does not require any additional annotations. We present an initial evaluation dataset, Book-SORT, comprising 36k pairs of segments extracted from 9 books recently added to the public domain. Based on a human experiment with 155 participants, we show that humans can recall sequence order based on long-term memory of a book. We find that models can perform the task with high accuracy when relevant text is given in-context during the SORT evaluation. However, when presented with the book text only during training, LLMs' performance on SORT falls short. By allowing to evaluate more aspects of memory, we believe that SORT will aid in the emerging development of memory-augmented models.
Identifying and interpreting non-aligned human conceptual representations using language modeling
Mar 10, 2024



The question of whether people's experience in the world shapes conceptual representation and lexical semantics is longstanding. Word-association, feature-listing and similarity rating tasks aim to address this question but require a subjective interpretation of the latent dimensions identified. In this study, we introduce a supervised representational-alignment method that (i) determines whether two groups of individuals share the same basis of a certain category, and (ii) explains in what respects they differ. In applying this method, we show that congenital blindness induces conceptual reorganization in both a-modal and sensory-related verbal domains, and we identify the associated semantic shifts. We first apply supervised feature-pruning to a language model (GloVe) to optimize prediction accuracy of human similarity judgments from word embeddings. Pruning identifies one subset of retained GloVe features that optimizes prediction of judgments made by sighted individuals and another subset that optimizes judgments made by blind. A linear probing analysis then interprets the latent semantics of these feature-subsets by learning a mapping from the retained GloVe features to 65 interpretable semantic dimensions. We applied this approach to seven semantic domains, including verbs related to motion, sight, touch, and amodal verbs related to knowledge acquisition. We find that blind individuals more strongly associate social and cognitive meanings to verbs related to motion or those communicating non-speech vocal utterances (e.g., whimper, moan). Conversely, for amodal verbs, they demonstrate much sparser information. Finally, for some verbs, representations of blind and sighted are highly similar. The study presents a formal approach for studying interindividual differences in word meaning, and the first demonstration of how blindness impacts conceptual representation of everyday verbs.
Toward a More Biologically Plausible Neural Network Model of Latent Cause Inference
Dec 13, 2023Humans spontaneously perceive a continuous stream of experience as discrete events. It has been hypothesized that this ability is supported by latent cause inference (LCI). We implemented this hypothesis using Latent Cause Network (LCNet), a neural network model of LCI. LCNet interacts with a Bayesian LCI mechanism that activates a unique context vector for each inferred latent cause. This architecture makes LCNet more biologically plausible than existing models of LCI and supports extraction of shared structure across latent causes. Across three simulations, we found that LCNet could 1) extract shared structure across latent causes in a function-learning task while avoiding catastrophic interference, 2) capture human data on curriculum effects in schema learning, and 3) infer the underlying event structure when processing naturalistic videos of daily activities. Our work provides a biologically plausible computational model that can operate in both laboratory experiment settings and naturalistic settings, opening up the possibility of providing a unified model of event cognition.
Enhancing Interpretability using Human Similarity Judgements to Prune Word Embeddings
Oct 16, 2023
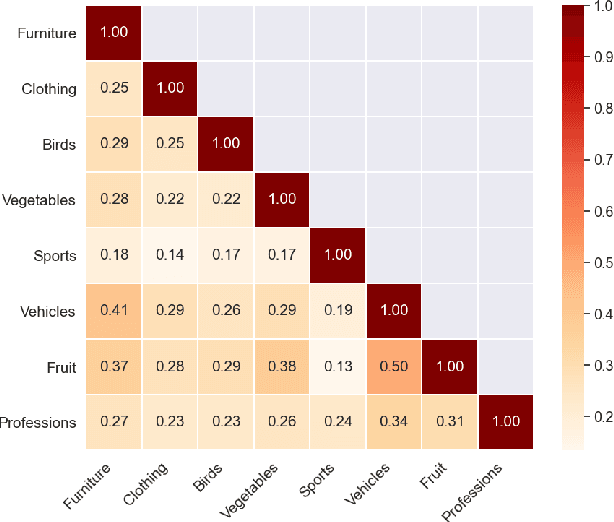


Interpretability methods in NLP aim to provide insights into the semantics underlying specific system architectures. Focusing on word embeddings, we present a supervised-learning method that, for a given domain (e.g., sports, professions), identifies a subset of model features that strongly improve prediction of human similarity judgments. We show this method keeps only 20-40% of the original embeddings, for 8 independent semantic domains, and that it retains different feature sets across domains. We then present two approaches for interpreting the semantics of the retained features. The first obtains the scores of the domain words (co-hyponyms) on the first principal component of the retained embeddings, and extracts terms whose co-occurrence with the co-hyponyms tracks these scores' profile. This analysis reveals that humans differentiate e.g. sports based on how gender-inclusive and international they are. The second approach uses the retained sets as variables in a probing task that predicts values along 65 semantically annotated dimensions for a dataset of 535 words. The features retained for professions are best at predicting cognitive, emotional and social dimensions, whereas features retained for fruits or vegetables best predict the gustation (taste) dimension. We discuss implications for alignment between AI systems and human knowledge.
The Temporal Structure of Language Processing in the Human Brain Corresponds to The Layered Hierarchy of Deep Language Models
Oct 11, 2023Deep Language Models (DLMs) provide a novel computational paradigm for understanding the mechanisms of natural language processing in the human brain. Unlike traditional psycholinguistic models, DLMs use layered sequences of continuous numerical vectors to represent words and context, allowing a plethora of emerging applications such as human-like text generation. In this paper we show evidence that the layered hierarchy of DLMs may be used to model the temporal dynamics of language comprehension in the brain by demonstrating a strong correlation between DLM layer depth and the time at which layers are most predictive of the human brain. Our ability to temporally resolve individual layers benefits from our use of electrocorticography (ECoG) data, which has a much higher temporal resolution than noninvasive methods like fMRI. Using ECoG, we record neural activity from participants listening to a 30-minute narrative while also feeding the same narrative to a high-performing DLM (GPT2-XL). We then extract contextual embeddings from the different layers of the DLM and use linear encoding models to predict neural activity. We first focus on the Inferior Frontal Gyrus (IFG, or Broca's area) and then extend our model to track the increasing temporal receptive window along the linguistic processing hierarchy from auditory to syntactic and semantic areas. Our results reveal a connection between human language processing and DLMs, with the DLM's layer-by-layer accumulation of contextual information mirroring the timing of neural activity in high-order language areas.
Data-Efficient Mutual Information Neural Estimator
May 24, 2019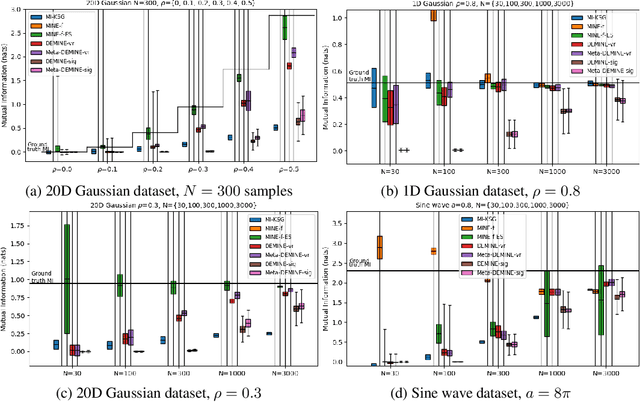
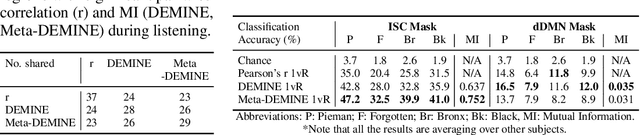
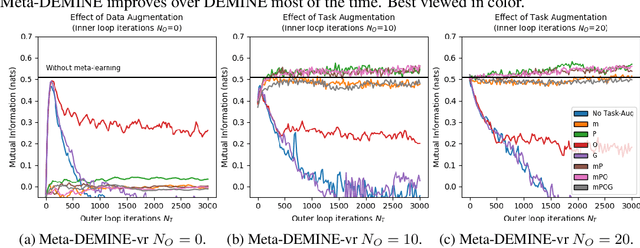
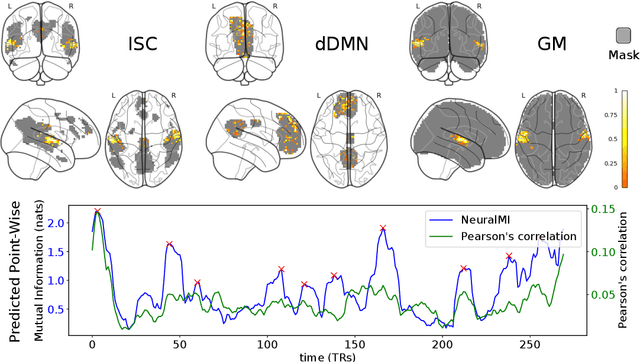
Measuring Mutual Information (MI) between high-dimensional, continuous, random variables from observed samples has wide theoretical and practical applications. Recent work, MINE (Belghazi et al. 2018), focused on estimating tight variational lower bounds of MI using neural networks, but assumed unlimited supply of samples to prevent overfitting. In real world applications, data is not always available at a surplus. In this work, we focus on improving data efficiency and propose a Data-Efficient MINE Estimator (DEMINE), by developing a relaxed predictive MI lower bound that can be estimated at higher data efficiency by orders of magnitudes. The predictive MI lower bound also enables us to develop a new meta-learning approach using task augmentation, Meta-DEMINE, to improve generalization of the network and further boost estimation accuracy empirically. With improved data-efficiency, our estimators enables statistical testing of dependency at practical dataset sizes. We demonstrate the effectiveness of our estimators on synthetic benchmarks and a real world fMRI data, with application of inter-subject correlation analysis.
Shared Representational Geometry Across Neural Networks
Nov 28, 2018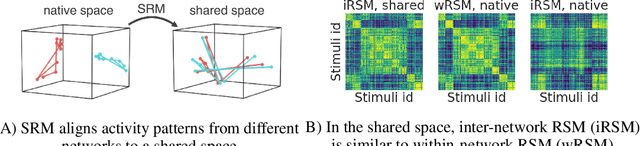
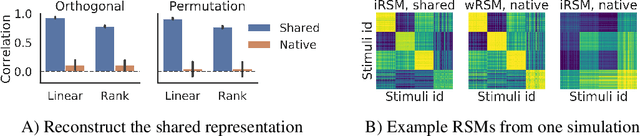
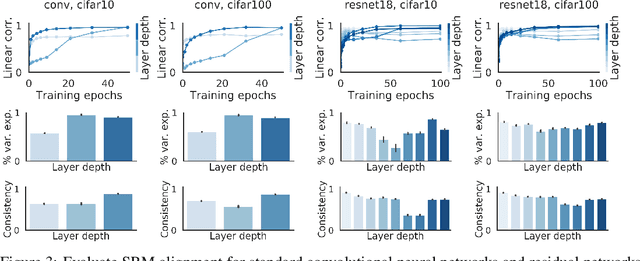
Different neural networks trained on the same dataset often learn similar input-output mappings with very different weights. Is there some correspondence between these neural network solutions? For linear networks, it has been shown that different instances of the same network architecture encode the same representational similarity matrix, and their neural activity patterns are connected by orthogonal transformations. However, it is unclear if this holds for non-linear networks. Using a shared response model, we show that different neural networks encode the same input examples as different orthogonal transformations of an underlying shared representation. We test this claim using both standard convolutional neural networks and residual networks on CIFAR10 and CIFAR100.
Mapping Between fMRI Responses to Movies and their Natural Language Annotations
Apr 10, 2017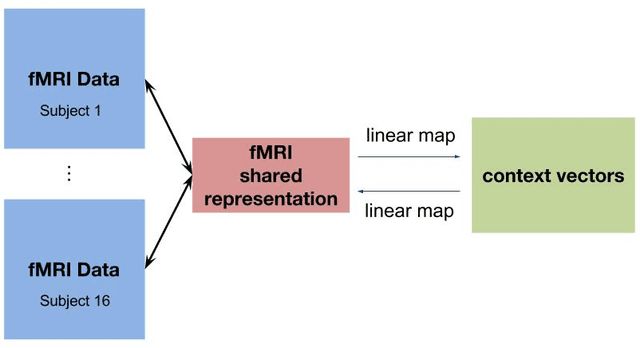
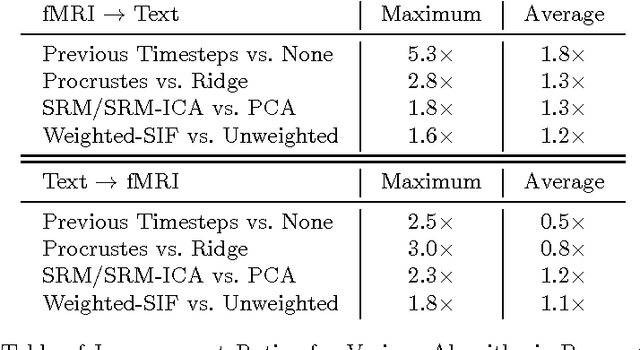
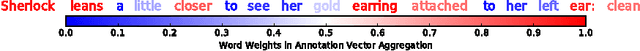
Several research groups have shown how to correlate fMRI responses to the meanings of presented stimuli. This paper presents new methods for doing so when only a natural language annotation is available as the description of the stimulus. We study fMRI data gathered from subjects watching an episode of BBCs Sherlock [1], and learn bidirectional mappings between fMRI responses and natural language representations. We show how to leverage data from multiple subjects watching the same movie to improve the accuracy of the mappings, allowing us to succeed at a scene classification task with 72% accuracy (random guessing would give 4%) and at a scene ranking task with average rank in the top 4% (random guessing would give 50%). The key ingredients are (a) the use of the Shared Response Model (SRM) and its variant SRM-ICA [2, 3] to aggregate fMRI data from multiple subjects, both of which are shown to be superior to standard PCA in producing low-dimensional representations for the tasks in this paper; (b) a sentence embedding technique adapted from the natural language processing (NLP) literature [4] that produces semantic vector representation of the annotations; (c) using previous timestep information in the featurization of the predictor data.
A Searchlight Factor Model Approach for Locating Shared Information in Multi-Subject fMRI Analysis
Sep 29, 2016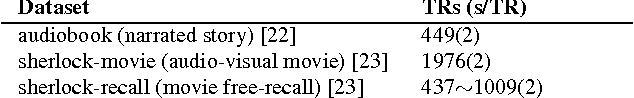
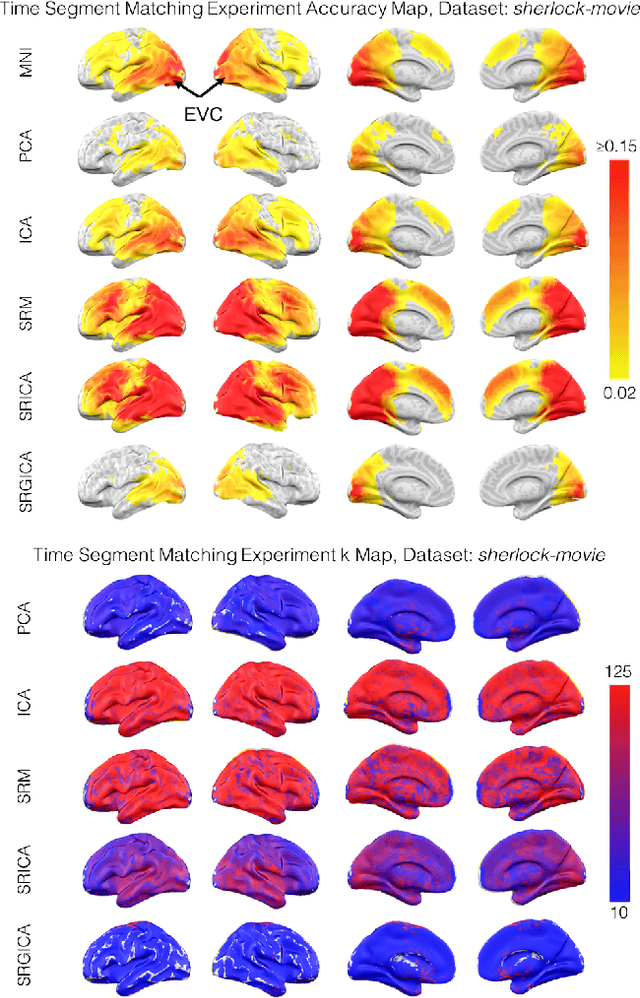
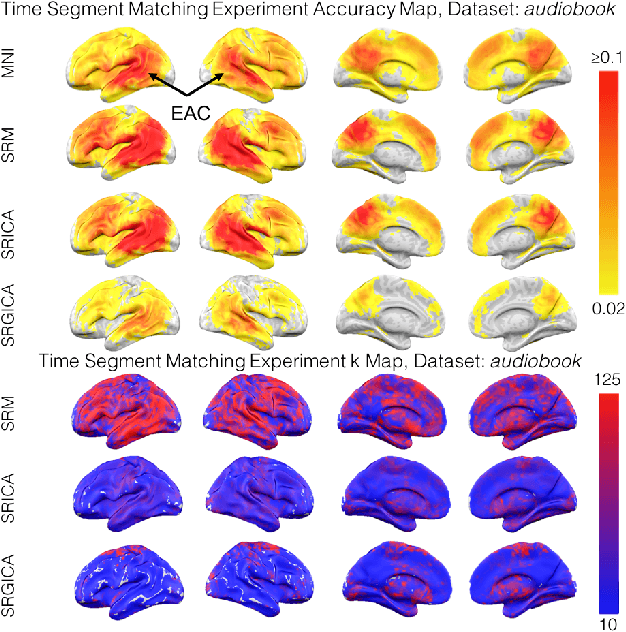
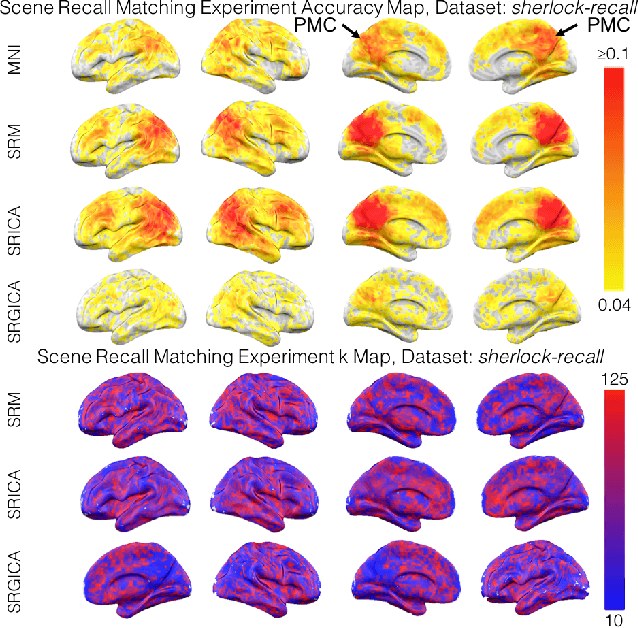
There is a growing interest in joint multi-subject fMRI analysis. The challenge of such analysis comes from inherent anatomical and functional variability across subjects. One approach to resolving this is a shared response factor model. This assumes a shared and time synchronized stimulus across subjects. Such a model can often identify shared information, but it may not be able to pinpoint with high resolution the spatial location of this information. In this work, we examine a searchlight based shared response model to identify shared information in small contiguous regions (searchlights) across the whole brain. Validation using classification tasks demonstrates that we can pinpoint informative local regions.