 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Verbatim Short-Term Memory in Neural Language Models
Oct 24, 2022



When a language model is trained to predict natural language sequences, its prediction at each moment depends on a representation of prior context. What kind of information about the prior context can language models retrieve? We tested whether language models could retrieve the exact words that occurred previously in a text. In our paradigm, language models (transformers and an LSTM) processed English text in which a list of nouns occurred twice. We operationalized retrieval as the reduction in surprisal from the first to the second list. We found that the transformers retrieved both the identity and ordering of nouns from the first list. Further, the transformers' retrieval was markedly enhanced when they were trained on a larger corpus and with greater model depth. Lastly, their ability to index prior tokens was dependent on learned attention patterns. In contrast, the LSTM exhibited less precise retrieval, which was limited to list-initial tokens and to short intervening texts. The LSTM's retrieval was not sensitive to the order of nouns and it improved when the list was semantically coherent. We conclude that transformers implemented something akin to a working memory system that could flexibly retrieve individual token representations across arbitrary delays; conversely, the LSTM maintained a coarser and more rapidly-decaying semantic gist of prior tokens, weighted toward the earliest items.
Mapping Between fMRI Responses to Movies and their Natural Language Annotations
Apr 10, 2017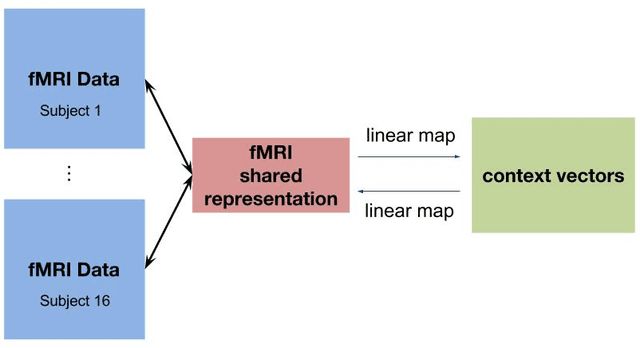
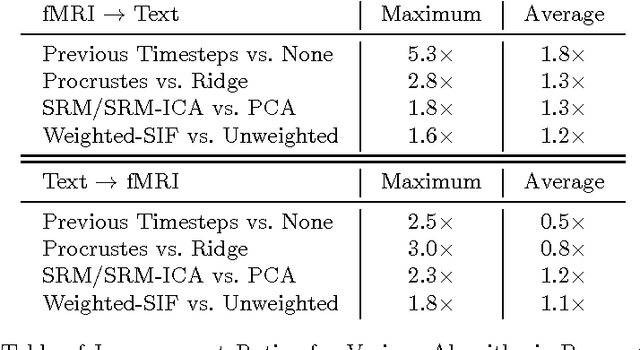
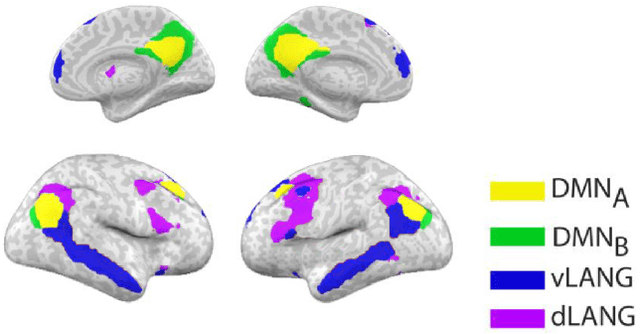
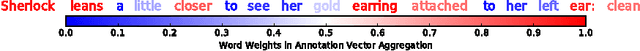
Several research groups have shown how to correlate fMRI responses to the meanings of presented stimuli. This paper presents new methods for doing so when only a natural language annotation is available as the description of the stimulus. We study fMRI data gathered from subjects watching an episode of BBCs Sherlock [1], and learn bidirectional mappings between fMRI responses and natural language representations. We show how to leverage data from multiple subjects watching the same movie to improve the accuracy of the mappings, allowing us to succeed at a scene classification task with 72% accuracy (random guessing would give 4%) and at a scene ranking task with average rank in the top 4% (random guessing would give 50%). The key ingredients are (a) the use of the Shared Response Model (SRM) and its variant SRM-ICA [2, 3] to aggregate fMRI data from multiple subjects, both of which are shown to be superior to standard PCA in producing low-dimensional representations for the tasks in this paper; (b) a sentence embedding technique adapted from the natural language processing (NLP) literature [4] that produces semantic vector representation of the annotations; (c) using previous timestep information in the featurization of the predictor data.