 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Between fMRI Responses to Movies and their Natural Language Annotations
Apr 10, 2017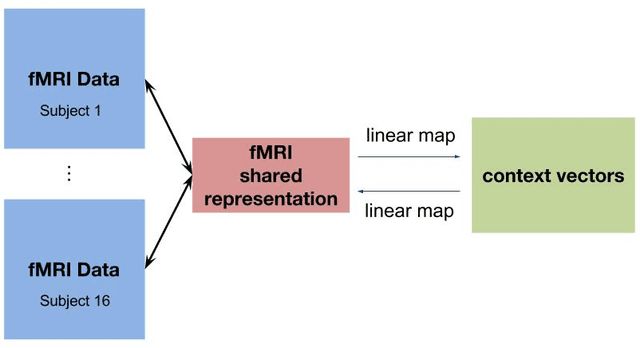
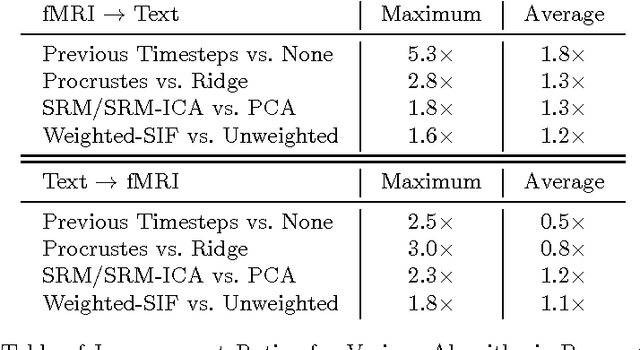
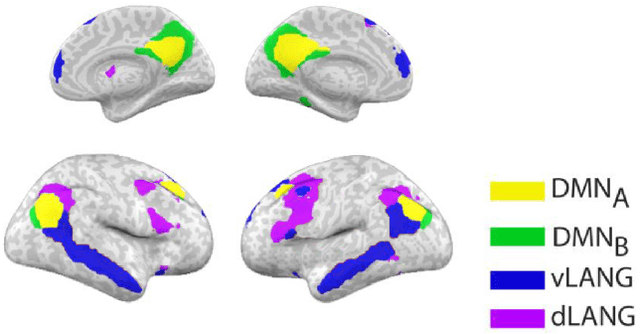
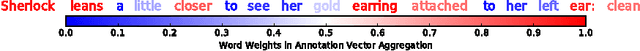
Several research groups have shown how to correlate fMRI responses to the meanings of presented stimuli. This paper presents new methods for doing so when only a natural language annotation is available as the description of the stimulus. We study fMRI data gathered from subjects watching an episode of BBCs Sherlock [1], and learn bidirectional mappings between fMRI responses and natural language representations. We show how to leverage data from multiple subjects watching the same movie to improve the accuracy of the mappings, allowing us to succeed at a scene classification task with 72% accuracy (random guessing would give 4%) and at a scene ranking task with average rank in the top 4% (random guessing would give 50%). The key ingredients are (a) the use of the Shared Response Model (SRM) and its variant SRM-ICA [2, 3] to aggregate fMRI data from multiple subjects, both of which are shown to be superior to standard PCA in producing low-dimensional representations for the tasks in this paper; (b) a sentence embedding technique adapted from the natural language processing (NLP) literature [4] that produces semantic vector representation of the annotations; (c) using previous timestep information in the featurization of the predictor data.
A Searchlight Factor Model Approach for Locating Shared Information in Multi-Subject fMRI Analysis
Sep 29, 2016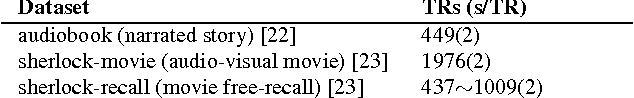
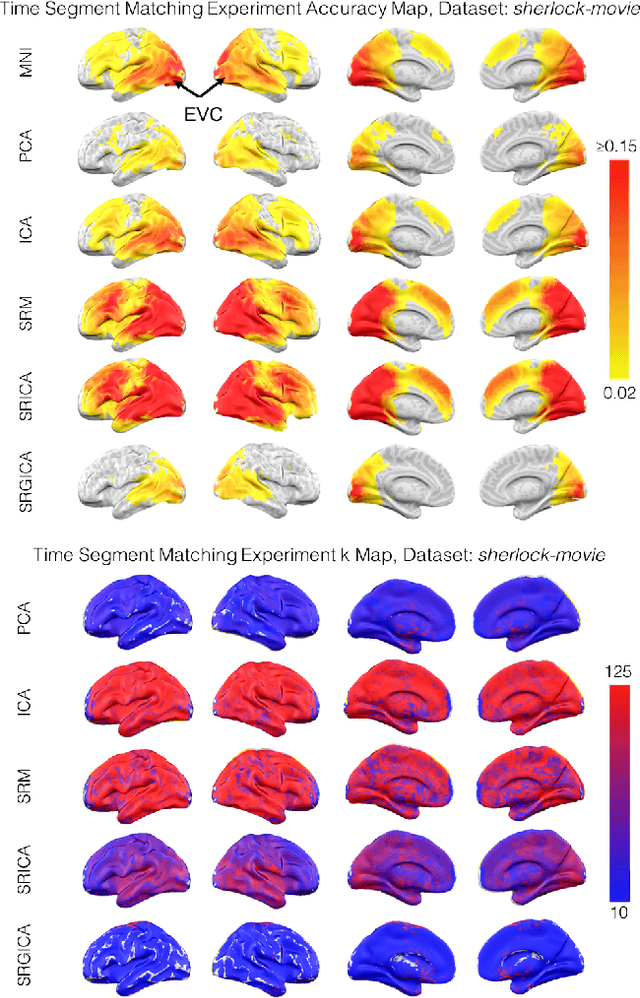
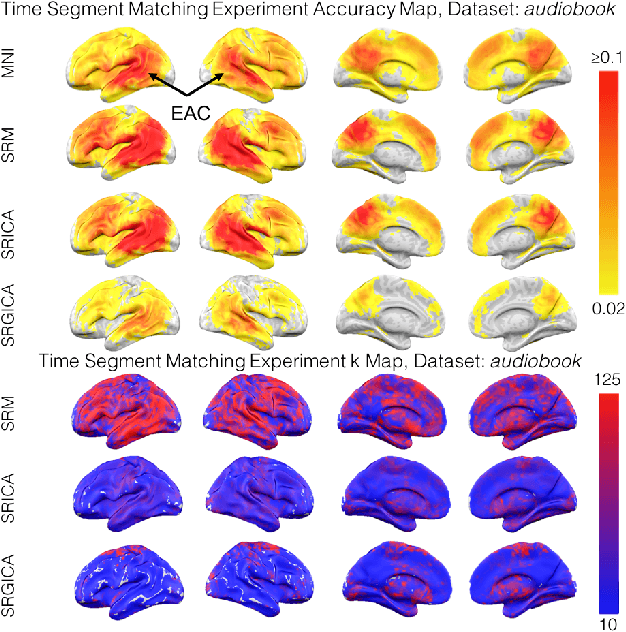
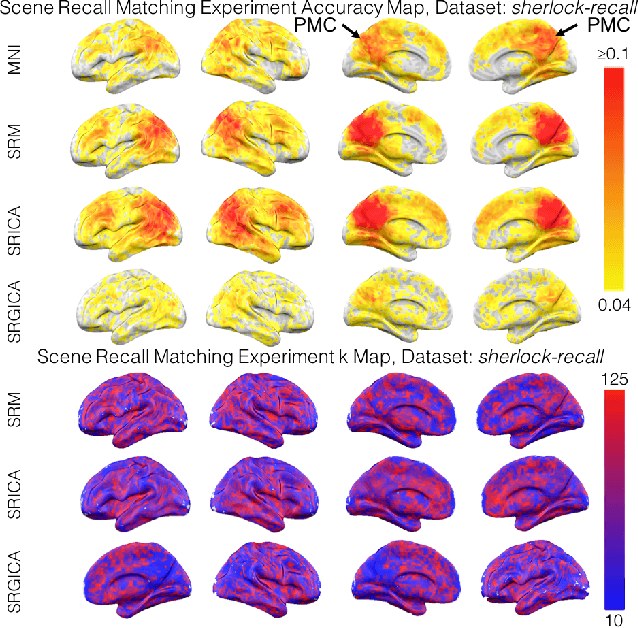
There is a growing interest in joint multi-subject fMRI analysis. The challenge of such analysis comes from inherent anatomical and functional variability across subjects. One approach to resolving this is a shared response factor model. This assumes a shared and time synchronized stimulus across subjects. Such a model can often identify shared information, but it may not be able to pinpoint with high resolution the spatial location of this information. In this work, we examine a searchlight based shared response model to identify shared information in small contiguous regions (searchlights) across the whole brain. Validation using classification tasks demonstrates that we can pinpoint informative local regions.
A Convolutional Autoencoder for Multi-Subject fMRI Data Aggregation
Aug 17, 2016
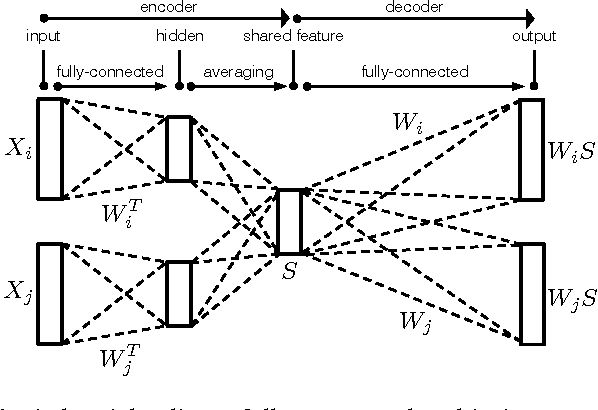
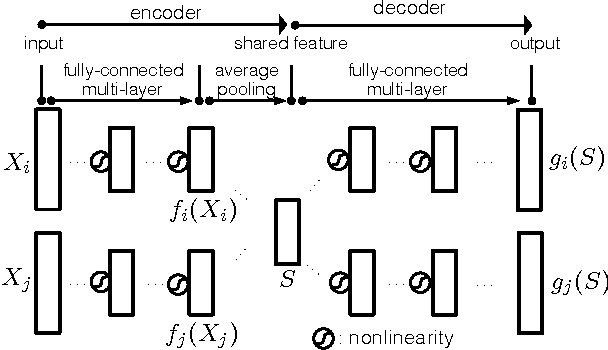
Finding the most effective way to aggregate multi-subject fMRI data is a long-standing and challenging problem. It is of increasing interest in contemporary fMRI studies of human cognition due to the scarcity of data per subject and the variability of brain anatomy and functional response across subjects. Recent work on latent factor models shows promising results in this task but this approach does not preserve spatial locality in the brain. We examine two ways to combine the ideas of a factor model and a searchlight based analysis to aggregate multi-subject fMRI data while preserving spatial locality. We first do this directly by combining a recent factor method known as a shared response model with searchlight analysis. Then we design a multi-view convolutional autoencoder for the same task. Both approaches preserve spatial locality and have competitive or better performance compared with standard searchlight analysis and the shared response model applied across the whole brain. We also report a system design to handle the computational challenge of training the convolutional autoencoder.