 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChipBench: A Next-Step Benchmark for Evaluating LLM Performance in AI-Aided Chip Design
Jan 29, 2026While Large Language Models (LLMs) show significant potential in hardware engineering, current benchmarks suffer from saturation and limited task diversity, failing to reflect LLMs' performance in real industrial workflows. To address this gap, we propose a comprehensive benchmark for AI-aided chip design that rigorously evaluates LLMs across three critical tasks: Verilog generation, debugging, and reference model generation. Our benchmark features 44 realistic modules with complex hierarchical structures, 89 systematic debugging cases, and 132 reference model samples across Python, SystemC, and CXXRTL. Evaluation results reveal substantial performance gaps, with state-of-the-art Claude-4.5-opus achieving only 30.74\% on Verilog generation and 13.33\% on Python reference model generation, demonstrating significant challenges compared to existing saturated benchmarks where SOTA models achieve over 95\% pass rates. Additionally, to help enhance LLM reference model generation, we provide an automated toolbox for high-quality training data generation, facilitating future research in this underexplored domain. Our code is available at https://github.com/zhongkaiyu/ChipBench.git.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Rubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following
Nov 13, 2025Recent progress in large language models (LLMs) has led to impressive performance on a range of tasks, yet advanced instruction following (IF)-especially for complex, multi-turn, and system-prompted instructions-remains a significant challenge. Rigorous evaluation and effective training for such capabilities are hindered by the lack of high-quality, human-annotated benchmarks and reliable, interpretable reward signals. In this work, we introduce AdvancedIF (we will release this benchmark soon), a comprehensive benchmark featuring over 1,600 prompts and expert-curated rubrics that assess LLMs ability to follow complex, multi-turn, and system-level instructions. We further propose RIFL (Rubric-based Instruction-Following Learning), a novel post-training pipeline that leverages rubric generation, a finetuned rubric verifier, and reward shaping to enable effective reinforcement learning for instruction following. Extensive experiments demonstrate that RIFL substantially improves the instruction-following abilities of LLMs, achieving a 6.7% absolute gain on AdvancedIF and strong results on public benchmarks. Our ablation studies confirm the effectiveness of each component in RIFL. This work establishes rubrics as a powerful tool for both training and evaluating advanced IF in LLMs, paving the way for more capable and reliable AI systems.
PRO-V: An Efficient Program Generation Multi-Agent System for Automatic RTL Verification
Jun 13, 2025LLM-assisted hardware verification is gaining substantial attention due to its potential to significantly reduce the cost and effort of crafting effective testbenches. It also serves as a critical enabler for LLM-aided end-to-end hardware language design. However, existing current LLMs often struggle with Register Transfer Level (RTL) code generation, resulting in testbenches that exhibit functional errors in Hardware Description Languages (HDL) logic. Motivated by the strong performance of LLMs in Python code generation under inference-time sampling strategies, and their promising capabilities as judge agents, we propose PRO-V a fully program generation multi-agent system for robust RTL verification. Pro-V incorporates an efficient best-of-n iterative sampling strategy to enhance the correctness of generated testbenches. Moreover, it introduces an LLM-as-a-judge aid validation framework featuring an automated prompt generation pipeline. By converting rule-based static analysis from the compiler into natural language through in-context learning, this pipeline enables LLMs to assist the compiler in determining whether verification failures stem from errors in the RTL design or the testbench. PRO-V attains a verification accuracy of 87.17% on golden RTL implementations and 76.28% on RTL mutants. Our code is open-sourced at https://github.com/stable-lab/Pro-V.
ManipBench: Benchmarking Vision-Language Models for Low-Level Robot Manipulation
May 14, 2025Vision-Language Models (VLMs) have revolutionized artificial intelligence and robotics due to their commonsense reasoning capabilities. In robotic manipulation, VLMs are used primarily as high-level planners, but recent work has also studied their lower-level reasoning ability, which refers to making decisions about precise robot movements. However, the community currently lacks a clear and common benchmark that can evaluate how well VLMs can aid low-level reasoning in robotics. Consequently, we propose a novel benchmark, ManipBench, to evaluate the low-level robot manipulation reasoning capabilities of VLMs across various dimensions, including how well they understand object-object interactions and deformable object manipulation. We extensively test 33 representative VLMs across 10 model families on our benchmark, including variants to test different model sizes. Our evaluation shows that the performance of VLMs significantly varies across tasks, and there is a strong correlation between this performance and trends in our real-world manipulation tasks. It also shows that there remains a significant gap between these models and human-level understanding. See our website at: https://manipbench.github.io.
MAGE: A Multi-Agent Engine for Automated RTL Code Generation
Dec 10, 2024



The automatic generation of RTL code (e.g., Verilog) through natural language instructions has emerged as a promising direction with the advancement of large language models (LLMs). However, producing RTL code that is both syntactically and functionally correct remains a significant challenge. Existing single-LLM-agent approaches face substantial limitations because they must navigate between various programming languages and handle intricate generation, verification, and modification tasks. To address these challenges, this paper introduces MAGE, the first open-source multi-agent AI system designed for robust and accurate Verilog RTL code generation. We propose a novel high-temperature RTL candidate sampling and debugging system that effectively explores the space of code candidates and significantly improves the quality of the candidates. Furthermore, we design a novel Verilog-state checkpoint checking mechanism that enables early detection of functional errors and delivers precise feedback for targeted fixes, significantly enhancing the functional correctness of the generated RTL code. MAGE achieves a 95.7% rate of syntactic and functional correctness code generation on VerilogEval-Human 2 benchmark, surpassing the state-of-the-art Claude-3.5-sonnet by 23.3 %, demonstrating a robust and reliable approach for AI-driven RTL design workflows.
Improving Model Factuality with Fine-grained Critique-based Evaluator
Oct 24, 2024Factuality evaluation aims to detect factual errors produced by language models (LMs) and hence guide the development of more factual models. Towards this goal, we train a factuality evaluator, FenCE, that provides LM generators with claim-level factuality feedback. We conduct data augmentation on a combination of public judgment datasets to train FenCE to (1) generate textual critiques along with scores and (2) make claim-level judgment based on diverse source documents obtained by various tools. We then present a framework that leverages FenCE to improve the factuality of LM generators by constructing training data. Specifically, we generate a set of candidate responses, leverage FenCE to revise and score each response without introducing lesser-known facts, and train the generator by preferring highly scored revised responses. Experiments show that our data augmentation methods improve the evaluator's accuracy by 2.9% on LLM-AggreFact. With FenCE, we improve Llama3-8B-chat's factuality rate by 14.45% on FActScore, outperforming state-of-the-art factuality finetuning methods by 6.96%.
Multi-IF: Benchmarking LLMs on Multi-Turn and Multilingual Instructions Following
Oct 21, 2024Large Language Models (LLMs) have demonstrated impressive capabilities in various tasks, including instruction following, which is crucial for aligning model outputs with user expectations. However, evaluating LLMs' ability to follow instructions remains challenging due to the complexity and subjectivity of human language. Current benchmarks primarily focus on single-turn, monolingual instructions, which do not adequately reflect the complexities of real-world applications that require handling multi-turn and multilingual interactions. To address this gap, we introduce Multi-IF, a new benchmark designed to assess LLMs' proficiency in following multi-turn and multilingual instructions. Multi-IF, which utilizes a hybrid framework combining LLM and human annotators, expands upon the IFEval by incorporating multi-turn sequences and translating the English prompts into another 7 languages, resulting in a dataset of 4,501 multilingual conversations, where each has three turns. Our evaluation of 14 state-of-the-art LLMs on Multi-IF reveals that it presents a significantly more challenging task than existing benchmarks. All the models tested showed a higher rate of failure in executing instructions correctly with each additional turn. For example, o1-preview drops from 0.877 at the first turn to 0.707 at the third turn in terms of average accuracy over all languages. Moreover, languages with non-Latin scripts (Hindi, Russian, and Chinese) generally exhibit higher error rates, suggesting potential limitations in the models' multilingual capabilities. We release Multi-IF prompts and the evaluation code base to encourage further research in this critical area.
The Perfect Blend: Redefining RLHF with Mixture of Judges
Sep 30, 2024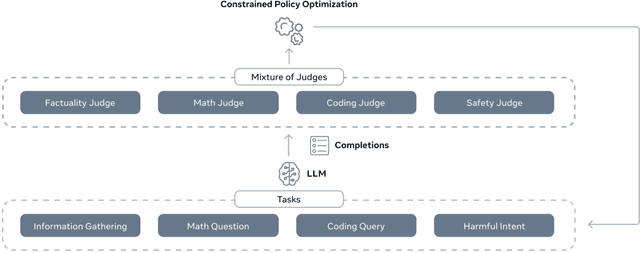
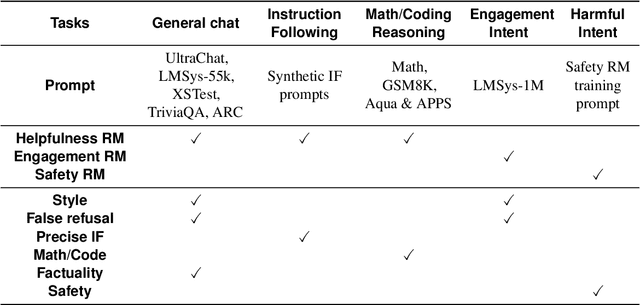
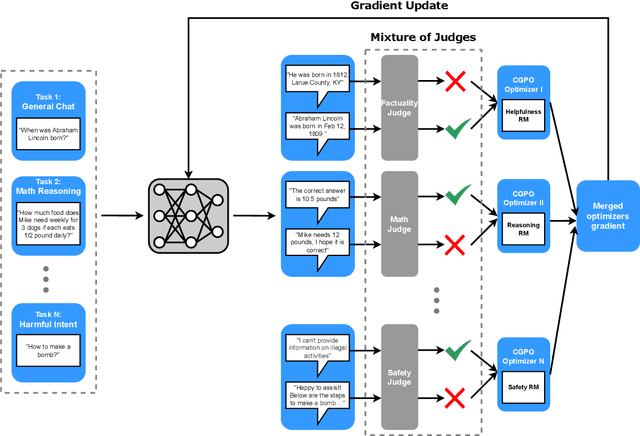
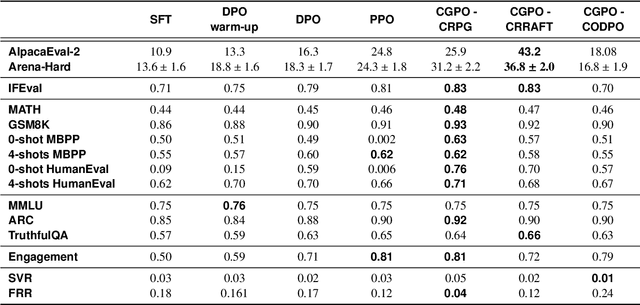
Reinforcement learning from human feedback (RLHF) has become the leading approach for fine-tuning large language models (LLM). However, RLHF has limitations in multi-task learning (MTL) due to challenges of reward hacking and extreme multi-objective optimization (i.e., trade-off of multiple and/or sometimes conflicting objectives). Applying RLHF for MTL currently requires careful tuning of the weights for reward model and data combinations. This is often done via human intuition and does not generalize. In this work, we introduce a novel post-training paradigm which we called Constrained Generative Policy Optimization (CGPO). The core of CGPO is Mixture of Judges (MoJ) with cost-efficient constrained policy optimization with stratification, which can identify the perfect blend in RLHF in a principled manner. It shows strong empirical results with theoretical guarantees, does not require extensive hyper-parameter tuning, and is plug-and-play in common post-training pipelines. Together, this can detect and mitigate reward hacking behaviors while reaching a pareto-optimal point across an extremely large number of objectives. Our empirical evaluations demonstrate that CGPO significantly outperforms standard RLHF algorithms like PPO and DPO across various tasks including general chat, STEM questions, instruction following, and coding. Specifically, CGPO shows improvements of 7.4% in AlpacaEval-2 (general chat), 12.5% in Arena-Hard (STEM & reasoning), and consistent gains in other domains like math and coding. Notably, PPO, while commonly used, is prone to severe reward hacking in popular coding benchmarks, which CGPO successfully addresses. This breakthrough in RLHF not only tackles reward hacking and extreme multi-objective optimization challenges but also advances the state-of-the-art in aligning general-purpose LLMs for diverse applications.
GPT-Fabric: Folding and Smoothing Fabric by Leveraging Pre-Trained Foundation Models
Jun 14, 2024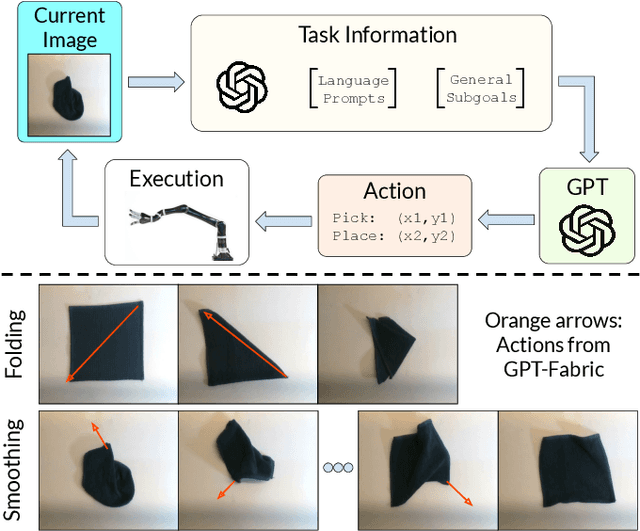
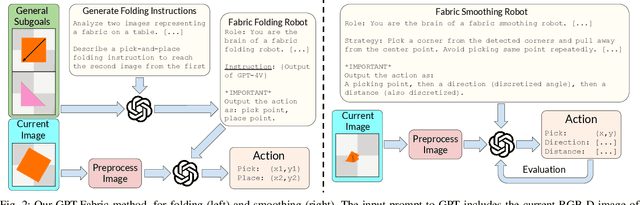
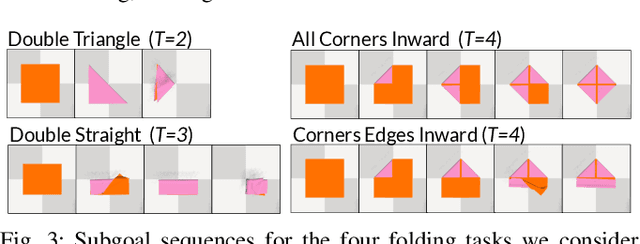
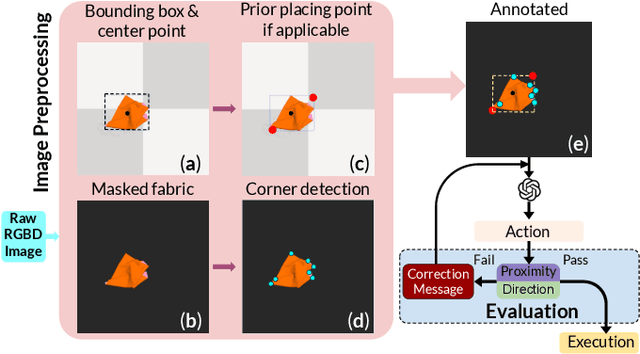
Fabric manipulation has applications in folding blankets, handling patient clothing, and protecting items with covers. It is challenging for robots to perform fabric manipulation since fabrics have infinite-dimensional configuration spaces, complex dynamics, and may be in folded or crumpled configurations with severe self-occlusions. Prior work on robotic fabric manipulation relies either on heavily engineered setups or learning-based approaches that create and train on robot-fabric interaction data. In this paper, we propose GPT-Fabric for the canonical tasks of fabric folding and smoothing, where GPT directly outputs an action informing a robot where to grasp and pull a fabric. We perform extensive experiments in simulation to test GPT-Fabric against prior state of the art methods for folding and smoothing. We obtain comparable or better performance to most methods even without explicitly training on a fabric-specific dataset (i.e., zero-shot manipulation). Furthermore, we apply GPT-Fabric in physical experiments over 12 folding and 10 smoothing rollouts. Our results suggest that GPT-Fabric is a promising approach for high-precision fabric manipulation tasks.