 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgem2sv: A Scalable Benchmark for Map-to-Street-View Spatial Reasoning
Jan 27, 2026Vision--language models (VLMs) achieve strong performance on many multimodal benchmarks but remain brittle on spatial reasoning tasks that require aligning abstract overhead representations with egocentric views. We introduce m2sv, a scalable benchmark for map-to-street-view spatial reasoning that asks models to infer camera viewing direction by aligning a north-up overhead map with a Street View image captured at the same real-world intersection. We release m2sv-20k, a geographically diverse benchmark with controlled ambiguity, along with m2sv-sft-11k, a curated set of structured reasoning traces for supervised fine-tuning. Despite strong performance on existing multimodal benchmarks, the best evaluated VLM achieves only 65.2% accuracy on m2sv, far below the human baseline of 95%. While supervised fine-tuning and reinforcement learning yield consistent gains, cross-benchmark evaluations reveal limited transfer. Beyond aggregate accuracy, we systematically analyze difficulty in map-to-street-view reasoning using both structural signals and human effort, and conduct an extensive failure analysis of adapted open models. Our findings highlight persistent gaps in geometric alignment, evidence aggregation, and reasoning consistency, motivating future work on grounded spatial reasoning across viewpoints.
What Matters in Data Curation for Multimodal Reasoning? Insights from the DCVLR Challenge
Jan 16, 2026We study data curation for multimodal reasoning through the NeurIPS 2025 Data Curation for Vision-Language Reasoning (DCVLR) challenge, which isolates dataset selection by fixing the model and training protocol. Using a compact curated dataset derived primarily from Walton Multimodal Cold Start, our submission placed first in the challenge. Through post-competition ablations, we show that difficulty-based example selection on an aligned base dataset is the dominant driver of performance gains. Increasing dataset size does not reliably improve mean accuracy under the fixed training recipe, but mainly reduces run-to-run variance, while commonly used diversity and synthetic augmentation heuristics provide no additional benefit and often degrade performance. These results characterize DCVLR as a saturation-regime evaluation and highlight the central role of alignment and difficulty in data-efficient multimodal reasoning.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Effective Long-Context Scaling of Foundation Models
Sep 27, 2023



We present a series of long-context LLMs that support effective context windows of up to 32,768 tokens. Our model series are built through continual pretraining from Llama 2 with longer training sequences and on a dataset where long texts are upsampled. We perform extensive evaluation on language modeling, synthetic context probing tasks, and a wide range of research benchmarks. On research benchmarks, our models achieve consistent improvements on most regular tasks and significant improvements on long-context tasks over Llama 2. Notably, with a cost-effective instruction tuning procedure that does not require human-annotated long instruction data, the 70B variant can already surpass gpt-3.5-turbo-16k's overall performance on a suite of long-context tasks. Alongside these results, we provide an in-depth analysis on the individual components of our method. We delve into Llama's position encodings and discuss its limitation in modeling long dependencies. We also examine the impact of various design choices in the pretraining process, including the data mix and the training curriculum of sequence lengths -- our ablation experiments suggest that having abundant long texts in the pretrain dataset is not the key to achieving strong performance, and we empirically verify that long context continual pretraining is more efficient and similarly effective compared to pretraining from scratch with long sequences.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
A Theory on Adam Instability in Large-Scale Machine Learning
Apr 25, 2023



We present a theory for the previously unexplained divergent behavior noticed in the training of large language models. We argue that the phenomenon is an artifact of the dominant optimization algorithm used for training, called Adam. We observe that Adam can enter a state in which the parameter update vector has a relatively large norm and is essentially uncorrelated with the direction of descent on the training loss landscape, leading to divergence. This artifact is more likely to be observed in the training of a deep model with a large batch size, which is the typical setting of large-scale language model training. To argue the theory, we present observations from the training runs of the language models of different scales: 7 billion, 30 billion, 65 billion, and 546 billion parameters.
Over-parametrization via Lifting for Low-rank Matrix Sensing: Conversion of Spurious Solutions to Strict Saddle Points
Feb 15, 2023
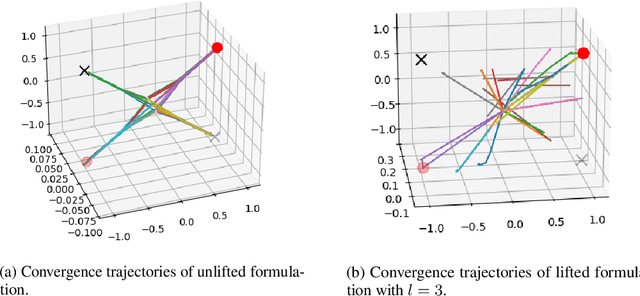

This paper studies the role of over-parametrization in solving non-convex optimization problems. The focus is on the important class of low-rank matrix sensing, where we propose an infinite hierarchy of non-convex problems via the lifting technique and the Burer-Monteiro factorization. This contrasts with the existing over-parametrization technique where the search rank is limited by the dimension of the matrix and it does not allow a rich over-parametrization of an arbitrary degree. We show that although the spurious solutions of the problem remain stationary points through the hierarchy, they will be transformed into strict saddle points (under some technical conditions) and can be escaped via local search methods. This is the first result in the literature showing that over-parametrization creates a negative curvature for escaping spurious solutions. We also derive a bound on how much over-parametrization is requited to enable the elimination of spurious solutions.
Global Convergence of MAML for LQR
May 31, 2020



The paper studies the performance of the Model-Agnostic Meta-Learning (MAML) algorithm as an optimization method. The goal is to determine the global convergence of MAML on sequential decision-making tasks possessing a common structure. We prove that the benign landscape of a single task leads to the global convergence of MAML in the single-task scenario and in the scenario of multiple structurally connected tasks. We also show that there is a two-task scenario that does not possess this global convergence property even for identical tasks. We analyze the landscape of the MAML objective on LQR tasks to determine what type of similarities in their structures enables the algorithm to converge to the globally optimal solution.