 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Dec 07, 2023



We introduce Llama Guard, an LLM-based input-output safeguard model geared towards Human-AI conversation use cases. Our model incorporates a safety risk taxonomy, a valuable tool for categorizing a specific set of safety risks found in LLM prompts (i.e., prompt classification). This taxonomy is also instrumental in classifying the responses generated by LLMs to these prompts, a process we refer to as response classification. For the purpose of both prompt and response classification, we have meticulously gathered a dataset of high quality. Llama Guard, a Llama2-7b model that is instruction-tuned on our collected dataset, albeit low in volume, demonstrates strong performance on existing benchmarks such as the OpenAI Moderation Evaluation dataset and ToxicChat, where its performance matches or exceeds that of currently available content moderation tools. Llama Guard functions as a language model, carrying out multi-class classification and generating binary decision scores. Furthermore, the instruction fine-tuning of Llama Guard allows for the customization of tasks and the adaptation of output formats. This feature enhances the model's capabilities, such as enabling the adjustment of taxonomy categories to align with specific use cases, and facilitating zero-shot or few-shot prompting with diverse taxonomies at the input. We are making Llama Guard model weights available and we encourage researchers to further develop and adapt them to meet the evolving needs of the community for AI safety.
Attention or Convolution: Transformer Encoders in Audio Language Models for Inference Efficiency
Nov 05, 2023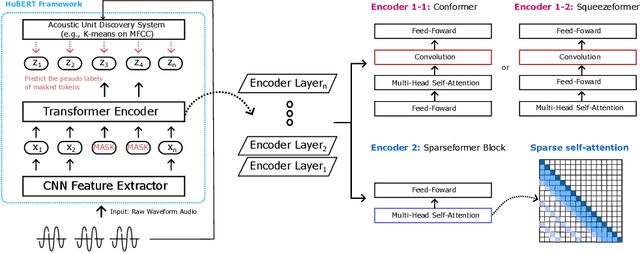
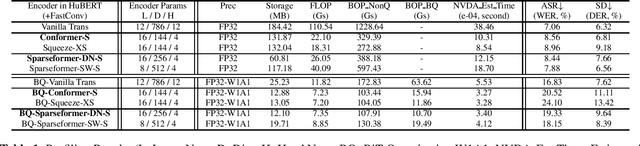
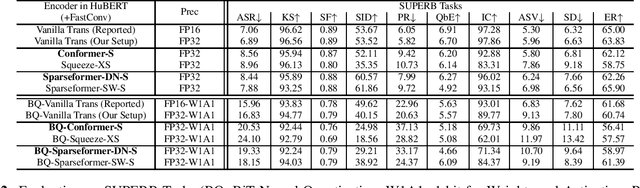
In this paper, we show that a simple self-supervised pre-trained audio model can achieve comparable inference efficiency to more complicated pre-trained models with speech transformer encoders. These speech transformers rely on mixing convolutional modules with self-attention modules. They achieve state-of-the-art performance on ASR with top efficiency. We first show that employing these speech transformers as an encoder significantly improves the efficiency of pre-trained audio models as well. However, our study shows that we can achieve comparable efficiency with advanced self-attention solely. We demonstrate that this simpler approach is particularly beneficial with a low-bit weight quantization technique of a neural network to improve efficiency. We hypothesize that it prevents propagating the errors between different quantized modules compared to recent speech transformers mixing quantized convolution and the quantized self-attention modules.
Effective Long-Context Scaling of Foundation Models
Sep 27, 2023



We present a series of long-context LLMs that support effective context windows of up to 32,768 tokens. Our model series are built through continual pretraining from Llama 2 with longer training sequences and on a dataset where long texts are upsampled. We perform extensive evaluation on language modeling, synthetic context probing tasks, and a wide range of research benchmarks. On research benchmarks, our models achieve consistent improvements on most regular tasks and significant improvements on long-context tasks over Llama 2. Notably, with a cost-effective instruction tuning procedure that does not require human-annotated long instruction data, the 70B variant can already surpass gpt-3.5-turbo-16k's overall performance on a suite of long-context tasks. Alongside these results, we provide an in-depth analysis on the individual components of our method. We delve into Llama's position encodings and discuss its limitation in modeling long dependencies. We also examine the impact of various design choices in the pretraining process, including the data mix and the training curriculum of sequence lengths -- our ablation experiments suggest that having abundant long texts in the pretrain dataset is not the key to achieving strong performance, and we empirically verify that long context continual pretraining is more efficient and similarly effective compared to pretraining from scratch with long sequences.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
Structured Summarization: Unified Text Segmentation and Segment Labeling as a Generation Task
Sep 28, 2022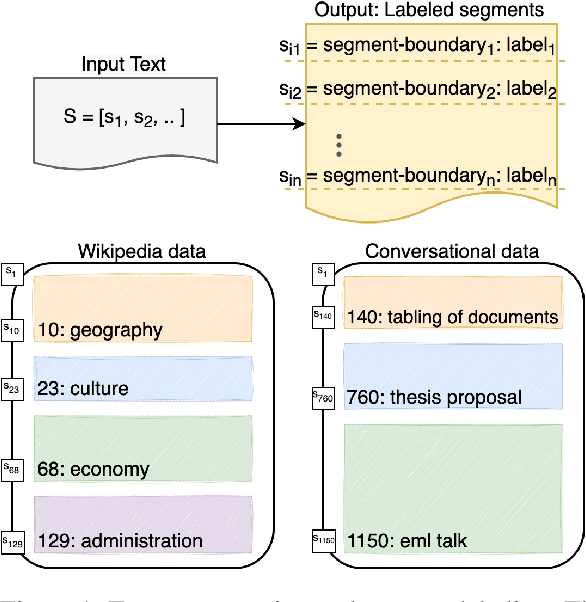
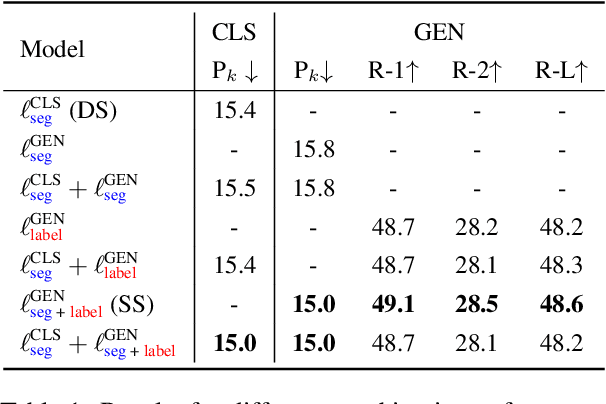
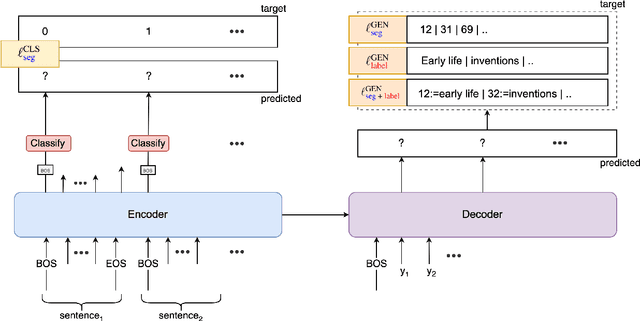

Text segmentation aims to divide text into contiguous, semantically coherent segments, while segment labeling deals with producing labels for each segment. Past work has shown success in tackling segmentation and labeling for documents and conversations. This has been possible with a combination of task-specific pipelines, supervised and unsupervised learning objectives. In this work, we propose a single encoder-decoder neural network that can handle long documents and conversations, trained simultaneously for both segmentation and segment labeling using only standard supervision. We successfully show a way to solve the combined task as a pure generation task, which we refer to as structured summarization. We apply the same technique to both document and conversational data, and we show state of the art performance across datasets for both segmentation and labeling, under both high- and low-resource settings. Our results establish a strong case for considering text segmentation and segment labeling as a whole, and moving towards general-purpose techniques that don't depend on domain expertise or task-specific components.