 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Dec 07, 2023



We introduce Llama Guard, an LLM-based input-output safeguard model geared towards Human-AI conversation use cases. Our model incorporates a safety risk taxonomy, a valuable tool for categorizing a specific set of safety risks found in LLM prompts (i.e., prompt classification). This taxonomy is also instrumental in classifying the responses generated by LLMs to these prompts, a process we refer to as response classification. For the purpose of both prompt and response classification, we have meticulously gathered a dataset of high quality. Llama Guard, a Llama2-7b model that is instruction-tuned on our collected dataset, albeit low in volume, demonstrates strong performance on existing benchmarks such as the OpenAI Moderation Evaluation dataset and ToxicChat, where its performance matches or exceeds that of currently available content moderation tools. Llama Guard functions as a language model, carrying out multi-class classification and generating binary decision scores. Furthermore, the instruction fine-tuning of Llama Guard allows for the customization of tasks and the adaptation of output formats. This feature enhances the model's capabilities, such as enabling the adjustment of taxonomy categories to align with specific use cases, and facilitating zero-shot or few-shot prompting with diverse taxonomies at the input. We are making Llama Guard model weights available and we encourage researchers to further develop and adapt them to meet the evolving needs of the community for AI safety.
Attention or Convolution: Transformer Encoders in Audio Language Models for Inference Efficiency
Nov 05, 2023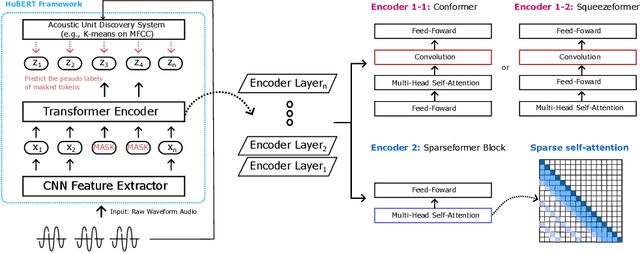
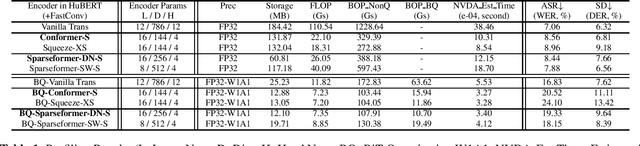
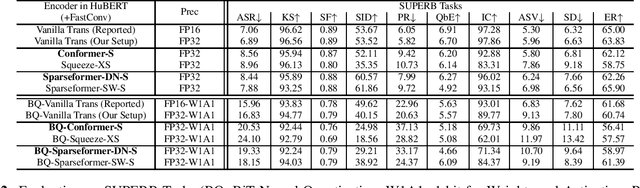
In this paper, we show that a simple self-supervised pre-trained audio model can achieve comparable inference efficiency to more complicated pre-trained models with speech transformer encoders. These speech transformers rely on mixing convolutional modules with self-attention modules. They achieve state-of-the-art performance on ASR with top efficiency. We first show that employing these speech transformers as an encoder significantly improves the efficiency of pre-trained audio models as well. However, our study shows that we can achieve comparable efficiency with advanced self-attention solely. We demonstrate that this simpler approach is particularly beneficial with a low-bit weight quantization technique of a neural network to improve efficiency. We hypothesize that it prevents propagating the errors between different quantized modules compared to recent speech transformers mixing quantized convolution and the quantized self-attention modules.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
Structured Summarization: Unified Text Segmentation and Segment Labeling as a Generation Task
Sep 28, 2022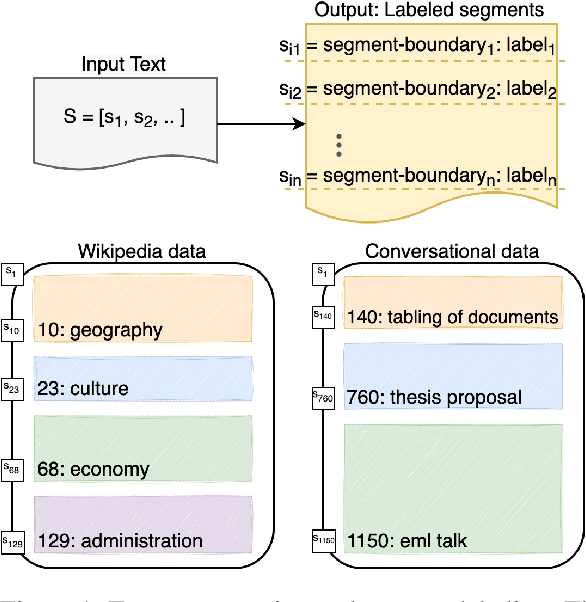
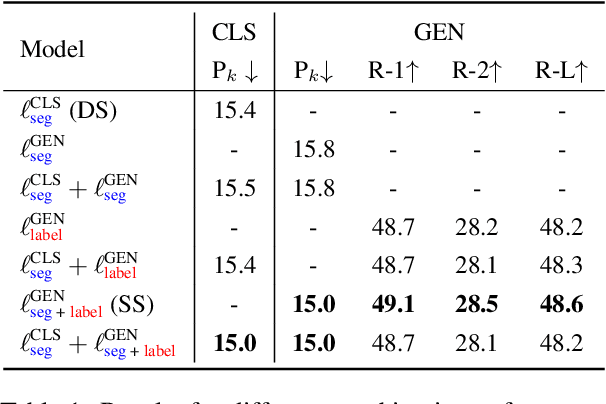
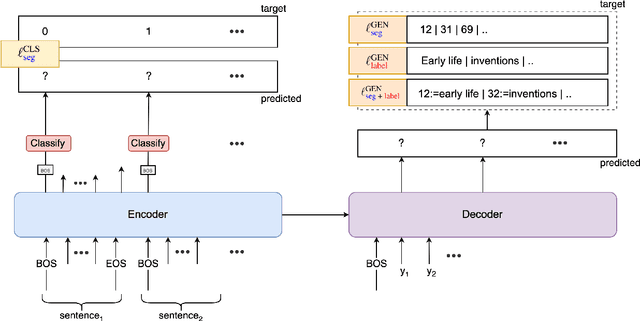

Text segmentation aims to divide text into contiguous, semantically coherent segments, while segment labeling deals with producing labels for each segment. Past work has shown success in tackling segmentation and labeling for documents and conversations. This has been possible with a combination of task-specific pipelines, supervised and unsupervised learning objectives. In this work, we propose a single encoder-decoder neural network that can handle long documents and conversations, trained simultaneously for both segmentation and segment labeling using only standard supervision. We successfully show a way to solve the combined task as a pure generation task, which we refer to as structured summarization. We apply the same technique to both document and conversational data, and we show state of the art performance across datasets for both segmentation and labeling, under both high- and low-resource settings. Our results establish a strong case for considering text segmentation and segment labeling as a whole, and moving towards general-purpose techniques that don't depend on domain expertise or task-specific components.
Conversational Answer Generation and Factuality for Reading Comprehension Question-Answering
Mar 11, 2021
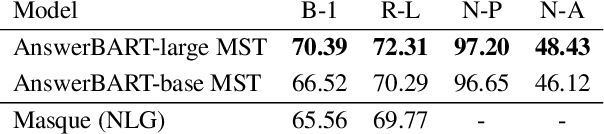
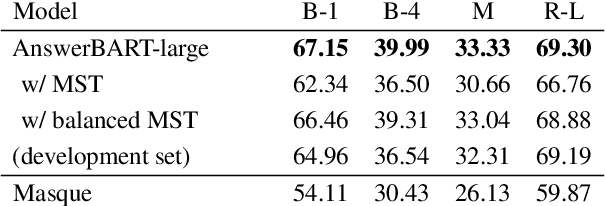
Question answering (QA) is an important use case on voice assistants. A popular approach to QA is extractive reading comprehension (RC) which finds an answer span in a text passage. However, extractive answers are often unnatural in a conversational context which results in suboptimal user experience. In this work, we investigate conversational answer generation for QA. We propose AnswerBART, an end-to-end generative RC model which combines answer generation from multiple passages with passage ranking and answerability. Moreover, a hurdle in applying generative RC are hallucinations where the answer is factually inconsistent with the passage text. We leverage recent work from summarization to evaluate factuality. Experiments show that AnswerBART significantly improves over previous best published results on MS MARCO 2.1 NLGEN by 2.5 ROUGE-L and NarrativeQA by 9.4 ROUGE-L.
Best Practices for Data-Efficient Modeling in NLG:How to Train Production-Ready Neural Models with Less Data
Nov 08, 2020Natural language generation (NLG) is a critical component in conversational systems, owing to its role of formulating a correct and natural text response. Traditionally, NLG components have been deployed using template-based solutions. Although neural network solutions recently developed in the research community have been shown to provide several benefits, deployment of such model-based solutions has been challenging due to high latency, correctness issues, and high data needs. In this paper, we present approaches that have helped us deploy data-efficient neural solutions for NLG in conversational systems to production. We describe a family of sampling and modeling techniques to attain production quality with light-weight neural network models using only a fraction of the data that would be necessary otherwise, and show a thorough comparison between each. Our results show that domain complexity dictates the appropriate approach to achieve high data efficiency. Finally, we distill the lessons from our experimental findings into a list of best practices for production-level NLG model development, and present them in a brief runbook. Importantly, the end products of all of the techniques are small sequence-to-sequence models (2Mb) that we can reliably deploy in production.
Towards Deep and Representation Learning for Talent Search at LinkedIn
Sep 17, 2018
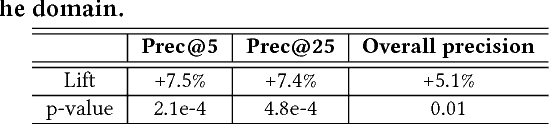
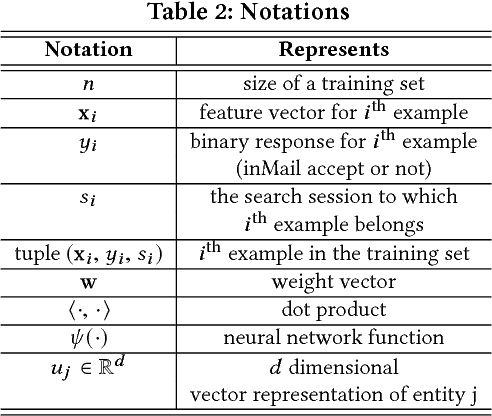
Talent search and recommendation systems at LinkedIn strive to match the potential candidates to the hiring needs of a recruiter or a hiring manager expressed in terms of a search query or a job posting. Recent work in this domain has mainly focused on linear models, which do not take complex relationships between features into account, as well as ensemble tree models, which introduce non-linearity but are still insufficient for exploring all the potential feature interactions, and strictly separate feature generation from modeling. In this paper, we present the results of our application of deep and representation learning models on LinkedIn Recruiter. Our key contributions include: (i) Learning semantic representations of sparse entities within the talent search domain, such as recruiter ids, candidate ids, and skill entity ids, for which we utilize neural network models that take advantage of LinkedIn Economic Graph, and (ii) Deep models for learning recruiter engagement and candidate response in talent search applications. We also explore learning to rank approaches applied to deep models, and show the benefits for the talent search use case. Finally, we present offline and online evaluation results for LinkedIn talent search and recommendation systems, and discuss potential challenges along the path to a fully deep model architecture. The challenges and approaches discussed generalize to any multi-faceted search engine.
Tying Word Vectors and Word Classifiers: A Loss Framework for Language Modeling
Mar 11, 2017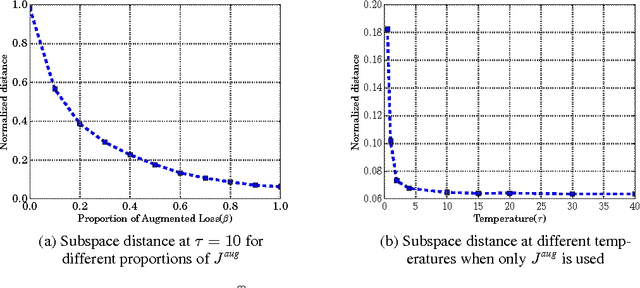
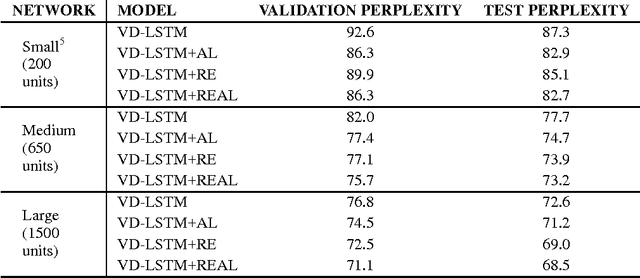
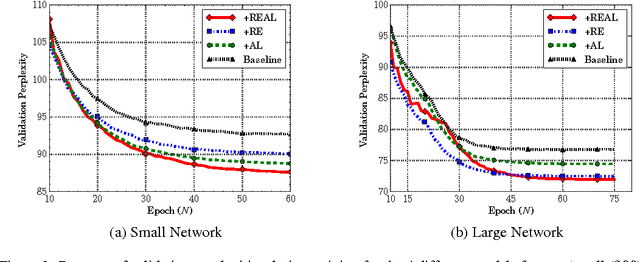

Recurrent neural networks have been very successful at predicting sequences of words in tasks such as language modeling. However, all such models are based on the conventional classification framework, where the model is trained against one-hot targets, and each word is represented both as an input and as an output in isolation. This causes inefficiencies in learning both in terms of utilizing all of the information and in terms of the number of parameters needed to train. We introduce a novel theoretical framework that facilitates better learning in language modeling, and show that our framework leads to tying together the input embedding and the output projection matrices, greatly reducing the number of trainable variables. Our framework leads to state of the art performance on the Penn Treebank with a variety of network models.