 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Shape it Up! Restoring LLM Safety during Finetuning
May 22, 2025Finetuning large language models (LLMs) enables user-specific customization but introduces critical safety risks: even a few harmful examples can compromise safety alignment. A common mitigation strategy is to update the model more strongly on examples deemed safe, while downweighting or excluding those flagged as unsafe. However, because safety context can shift within a single example, updating the model equally on both harmful and harmless parts of a response is suboptimal-a coarse treatment we term static safety shaping. In contrast, we propose dynamic safety shaping (DSS), a framework that uses fine-grained safety signals to reinforce learning from safe segments of a response while suppressing unsafe content. To enable such fine-grained control during finetuning, we introduce a key insight: guardrail models, traditionally used for filtering, can be repurposed to evaluate partial responses, tracking how safety risk evolves throughout the response, segment by segment. This leads to the Safety Trajectory Assessment of Response (STAR), a token-level signal that enables shaping to operate dynamically over the training sequence. Building on this, we present STAR-DSS, guided by STAR scores, that robustly mitigates finetuning risks and delivers substantial safety improvements across diverse threats, datasets, and model families-all without compromising capability on intended tasks. We encourage future safety research to build on dynamic shaping principles for stronger mitigation against evolving finetuning risks.
Llama Guard 3-1B-INT4: Compact and Efficient Safeguard for Human-AI Conversations
Nov 18, 2024This paper presents Llama Guard 3-1B-INT4, a compact and efficient Llama Guard model, which has been open-sourced to the community during Meta Connect 2024. We demonstrate that Llama Guard 3-1B-INT4 can be deployed on resource-constrained devices, achieving a throughput of at least 30 tokens per second and a time-to-first-token of 2.5 seconds or less on a commodity Android mobile CPU. Notably, our experiments show that Llama Guard 3-1B-INT4 attains comparable or superior safety moderation scores to its larger counterpart, Llama Guard 3-1B, despite being approximately 7 times smaller in size (440MB).
Llama Guard 3 Vision: Safeguarding Human-AI Image Understanding Conversations
Nov 15, 2024
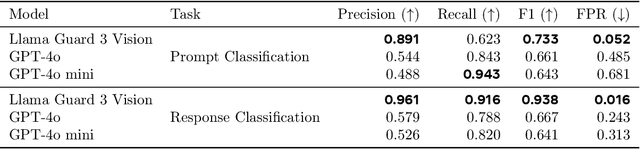
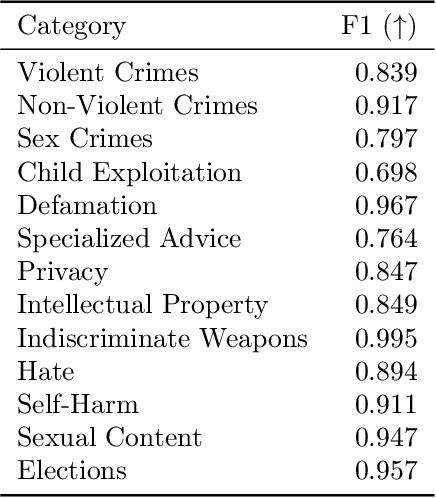
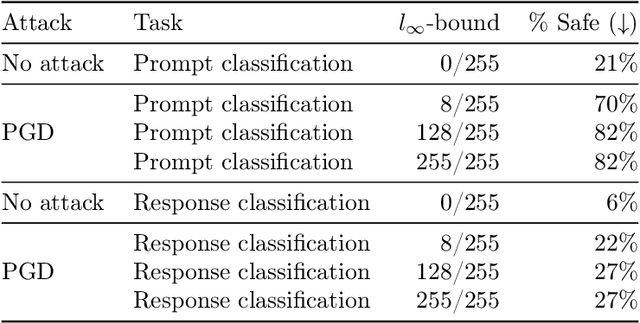
We introduce Llama Guard 3 Vision, a multimodal LLM-based safeguard for human-AI conversations that involves image understanding: it can be used to safeguard content for both multimodal LLM inputs (prompt classification) and outputs (response classification). Unlike the previous text-only Llama Guard versions (Inan et al., 2023; Llama Team, 2024b,a), it is specifically designed to support image reasoning use cases and is optimized to detect harmful multimodal (text and image) prompts and text responses to these prompts. Llama Guard 3 Vision is fine-tuned on Llama 3.2-Vision and demonstrates strong performance on the internal benchmarks using the MLCommons taxonomy. We also test its robustness against adversarial attacks. We believe that Llama Guard 3 Vision serves as a good starting point to build more capable and robust content moderation tools for human-AI conversation with multimodal capabilities.
Towards Understanding the Fragility of Multilingual LLMs against Fine-Tuning Attacks
Oct 23, 2024Recent advancements in Large Language Models (LLMs) have sparked widespread concerns about their safety. Recent work demonstrates that safety alignment of LLMs can be easily removed by fine-tuning with a few adversarially chosen instruction-following examples, i.e., fine-tuning attacks. We take a further step to understand fine-tuning attacks in multilingual LLMs. We first discover cross-lingual generalization of fine-tuning attacks: using a few adversarially chosen instruction-following examples in one language, multilingual LLMs can also be easily compromised (e.g., multilingual LLMs fail to refuse harmful prompts in other languages). Motivated by this finding, we hypothesize that safety-related information is language-agnostic and propose a new method termed Safety Information Localization (SIL) to identify the safety-related information in the model parameter space. Through SIL, we validate this hypothesis and find that only changing 20% of weight parameters in fine-tuning attacks can break safety alignment across all languages. Furthermore, we provide evidence to the alternative pathways hypothesis for why freezing safety-related parameters does not prevent fine-tuning attacks, and we demonstrate that our attack vector can still jailbreak LLMs adapted to new languages.
Persistent Pre-Training Poisoning of LLMs
Oct 17, 2024Large language models are pre-trained on uncurated text datasets consisting of trillions of tokens scraped from the Web. Prior work has shown that: (1) web-scraped pre-training datasets can be practically poisoned by malicious actors; and (2) adversaries can compromise language models after poisoning fine-tuning datasets. Our work evaluates for the first time whether language models can also be compromised during pre-training, with a focus on the persistence of pre-training attacks after models are fine-tuned as helpful and harmless chatbots (i.e., after SFT and DPO). We pre-train a series of LLMs from scratch to measure the impact of a potential poisoning adversary under four different attack objectives (denial-of-service, belief manipulation, jailbreaking, and prompt stealing), and across a wide range of model sizes (from 600M to 7B). Our main result is that poisoning only 0.1% of a model's pre-training dataset is sufficient for three out of four attacks to measurably persist through post-training. Moreover, simple attacks like denial-of-service persist through post-training with a poisoning rate of only 0.001%.
Backtracking Improves Generation Safety
Sep 22, 2024



Text generation has a fundamental limitation almost by definition: there is no taking back tokens that have been generated, even when they are clearly problematic. In the context of language model safety, when a partial unsafe generation is produced, language models by their nature tend to happily keep on generating similarly unsafe additional text. This is in fact how safety alignment of frontier models gets circumvented in the wild, despite great efforts in improving their safety. Deviating from the paradigm of approaching safety alignment as prevention (decreasing the probability of harmful responses), we propose backtracking, a technique that allows language models to "undo" and recover from their own unsafe generation through the introduction of a special [RESET] token. Our method can be incorporated into either SFT or DPO training to optimize helpfulness and harmlessness. We show that models trained to backtrack are consistently safer than baseline models: backtracking Llama-3-8B is four times more safe than the baseline model (6.1\% $\to$ 1.5\%) in our evaluations without regression in helpfulness. Our method additionally provides protection against four adversarial attacks including an adaptive attack, despite not being trained to do so.
BadMerging: Backdoor Attacks Against Model Merging
Aug 14, 2024



Fine-tuning pre-trained models for downstream tasks has led to a proliferation of open-sourced task-specific models. Recently, Model Merging (MM) has emerged as an effective approach to facilitate knowledge transfer among these independently fine-tuned models. MM directly combines multiple fine-tuned task-specific models into a merged model without additional training, and the resulting model shows enhanced capabilities in multiple tasks. Although MM provides great utility, it may come with security risks because an adversary can exploit MM to affect multiple downstream tasks. However, the security risks of MM have barely been studied. In this paper, we first find that MM, as a new learning paradigm, introduces unique challenges for existing backdoor attacks due to the merging process. To address these challenges, we introduce BadMerging, the first backdoor attack specifically designed for MM. Notably, BadMerging allows an adversary to compromise the entire merged model by contributing as few as one backdoored task-specific model. BadMerging comprises a two-stage attack mechanism and a novel feature-interpolation-based loss to enhance the robustness of embedded backdoors against the changes of different merging parameters. Considering that a merged model may incorporate tasks from different domains, BadMerging can jointly compromise the tasks provided by the adversary (on-task attack) and other contributors (off-task attack) and solve the corresponding unique challenges with novel attack designs. Extensive experiments show that BadMerging achieves remarkable attacks against various MM algorithms. Our ablation study demonstrates that the proposed attack designs can progressively contribute to the attack performance. Finally, we show that prior defense mechanisms fail to defend against our attacks, highlighting the need for more advanced defense.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
EAVE: Efficient Product Attribute Value Extraction via Lightweight Sparse-layer Interaction
Jun 10, 2024



Product attribute value extraction involves identifying the specific values associated with various attributes from a product profile. While existing methods often prioritize the development of effective models to improve extraction performance, there has been limited emphasis on extraction efficiency. However, in real-world scenarios, products are typically associated with multiple attributes, necessitating multiple extractions to obtain all corresponding values. In this work, we propose an Efficient product Attribute Value Extraction (EAVE) approach via lightweight sparse-layer interaction. Specifically, we employ a heavy encoder to separately encode the product context and attribute. The resulting non-interacting heavy representations of the context can be cached and reused for all attributes. Additionally, we introduce a light encoder to jointly encode the context and the attribute, facilitating lightweight interactions between them. To enrich the interaction within the lightweight encoder, we design a sparse-layer interaction module to fuse the non-interacting heavy representation into the lightweight encoder. Comprehensive evaluation on two benchmarks demonstrate that our method achieves significant efficiency gains with neutral or marginal loss in performance when the context is long and number of attributes is large. Our code is available \href{https://anonymous.4open.science/r/EAVE-EA18}{here}.