 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany-Tier Instruction Hierarchy in LLM Agents
Apr 14, 2026Large language model agents receive instructions from many sources-system messages, user prompts, tool outputs, other agents, and more-each carrying different levels of trust and authority. When these instructions conflict, agents must reliably follow the highest-privilege instruction to remain safe and effective. The dominant paradigm, instruction hierarchy (IH), assumes a fixed, small set of privilege levels (typically fewer than five) defined by rigid role labels (e.g., system > user). This is inadequate for real-world agentic settings, where conflicts can arise across far more sources and contexts. In this work, we propose Many-Tier Instruction Hierarchy (ManyIH), a paradigm for resolving instruction conflicts among instructions with arbitrarily many privilege levels. We introduce ManyIH-Bench, the first benchmark for ManyIH. ManyIH-Bench requires models to navigate up to 12 levels of conflicting instructions with varying privileges, comprising 853 agentic tasks (427 coding and 426 instruction-following). ManyIH-Bench composes constraints developed by LLMs and verified by humans to create realistic and difficult test cases spanning 46 real-world agents. Our experiments show that even the current frontier models perform poorly (~40% accuracy) when instruction conflict scales. This work underscores the urgent need for methods that explicitly target fine-grained, scalable instruction conflict resolution in agentic settings.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Positional Encoding via Token-Aware Phase Attention
Sep 16, 2025We prove under practical assumptions that Rotary Positional Embedding (RoPE) introduces an intrinsic distance-dependent bias in attention scores that limits RoPE's ability to model long-context. RoPE extension methods may alleviate this issue, but they typically require post-hoc adjustments after pretraining, such as rescaling or hyperparameters retuning. This paper introduces Token-Aware Phase Attention (TAPA), a new positional encoding method that incorporates a learnable phase function into the attention mechanism. TAPA preserves token interactions over long range, extends to longer contexts with direct and light fine-tuning, extrapolates to unseen lengths, and attains significantly lower perplexity on long-context than RoPE families.
Llama Guard 3-1B-INT4: Compact and Efficient Safeguard for Human-AI Conversations
Nov 18, 2024This paper presents Llama Guard 3-1B-INT4, a compact and efficient Llama Guard model, which has been open-sourced to the community during Meta Connect 2024. We demonstrate that Llama Guard 3-1B-INT4 can be deployed on resource-constrained devices, achieving a throughput of at least 30 tokens per second and a time-to-first-token of 2.5 seconds or less on a commodity Android mobile CPU. Notably, our experiments show that Llama Guard 3-1B-INT4 attains comparable or superior safety moderation scores to its larger counterpart, Llama Guard 3-1B, despite being approximately 7 times smaller in size (440MB).
Llama Guard 3 Vision: Safeguarding Human-AI Image Understanding Conversations
Nov 15, 2024
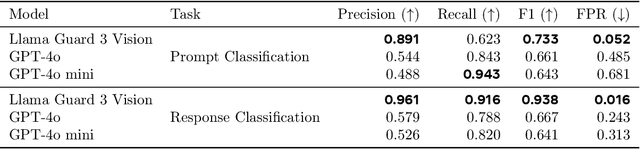
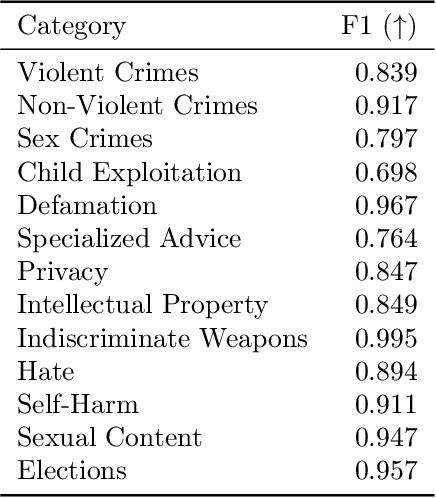
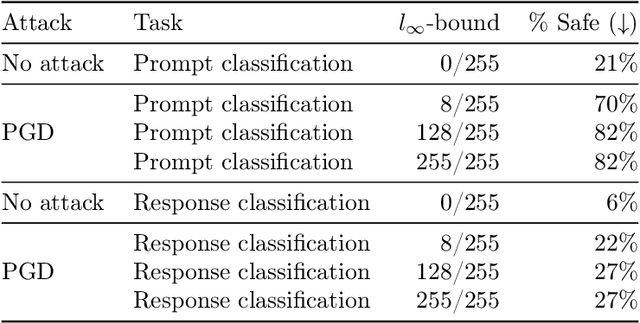
We introduce Llama Guard 3 Vision, a multimodal LLM-based safeguard for human-AI conversations that involves image understanding: it can be used to safeguard content for both multimodal LLM inputs (prompt classification) and outputs (response classification). Unlike the previous text-only Llama Guard versions (Inan et al., 2023; Llama Team, 2024b,a), it is specifically designed to support image reasoning use cases and is optimized to detect harmful multimodal (text and image) prompts and text responses to these prompts. Llama Guard 3 Vision is fine-tuned on Llama 3.2-Vision and demonstrates strong performance on the internal benchmarks using the MLCommons taxonomy. We also test its robustness against adversarial attacks. We believe that Llama Guard 3 Vision serves as a good starting point to build more capable and robust content moderation tools for human-AI conversation with multimodal capabilities.
PrE-Text: Training Language Models on Private Federated Data in the Age of LLMs
Jun 05, 2024On-device training is currently the most common approach for training machine learning (ML) models on private, distributed user data. Despite this, on-device training has several drawbacks: (1) most user devices are too small to train large models on-device, (2) on-device training is communication- and computation-intensive, and (3) on-device training can be difficult to debug and deploy. To address these problems, we propose Private Evolution-Text (PrE-Text), a method for generating differentially private (DP) synthetic textual data. First, we show that across multiple datasets, training small models (models that fit on user devices) with PrE-Text synthetic data outperforms small models trained on-device under practical privacy regimes ($\epsilon=1.29$, $\epsilon=7.58$). We achieve these results while using 9$\times$ fewer rounds, 6$\times$ less client computation per round, and 100$\times$ less communication per round. Second, finetuning large models on PrE-Text's DP synthetic data improves large language model (LLM) performance on private data across the same range of privacy budgets. Altogether, these results suggest that training on DP synthetic data can be a better option than training a model on-device on private distributed data. Code is available at https://github.com/houcharlie/PrE-Text.
Privately Customizing Prefinetuning to Better Match User Data in Federated Learning
Feb 23, 2023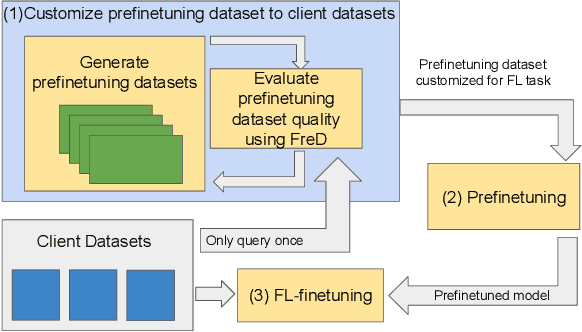

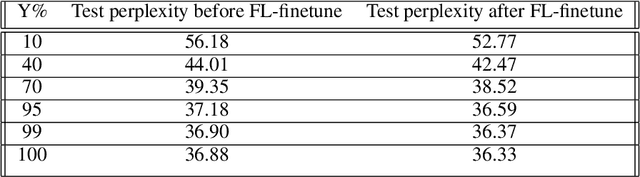
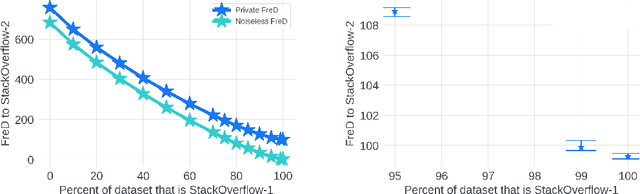
In Federated Learning (FL), accessing private client data incurs communication and privacy costs. As a result, FL deployments commonly prefinetune pretrained foundation models on a (large, possibly public) dataset that is held by the central server; they then FL-finetune the model on a private, federated dataset held by clients. Evaluating prefinetuning dataset quality reliably and privately is therefore of high importance. To this end, we propose FreD (Federated Private Fr\'echet Distance) -- a privately computed distance between a prefinetuning dataset and federated datasets. Intuitively, it privately computes and compares a Fr\'echet distance between embeddings generated by a large language model on both the central (public) dataset and the federated private client data. To make this computation privacy-preserving, we use distributed, differentially-private mean and covariance estimators. We show empirically that FreD accurately predicts the best prefinetuning dataset at minimal privacy cost. Altogether, using FreD we demonstrate a proof-of-concept for a new approach in private FL training: (1) customize a prefinetuning dataset to better match user data (2) prefinetune (3) perform FL-finetuning.
FedSynth: Gradient Compression via Synthetic Data in Federated Learning
Apr 04, 2022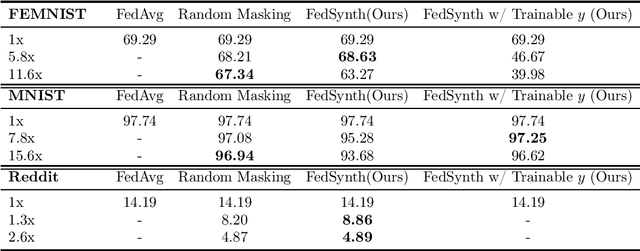
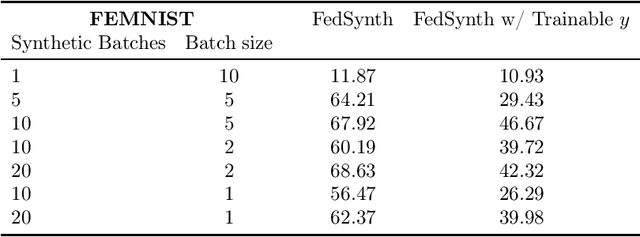

Model compression is important in federated learning (FL) with large models to reduce communication cost. Prior works have been focusing on sparsification based compression that could desparately affect the global model accuracy. In this work, we propose a new scheme for upstream communication where instead of transmitting the model update, each client learns and transmits a light-weight synthetic dataset such that using it as the training data, the model performs similarly well on the real training data. The server will recover the local model update via the synthetic data and apply standard aggregation. We then provide a new algorithm FedSynth to learn the synthetic data locally. Empirically, we find our method is comparable/better than random masking baselines in all three common federated learning benchmark datasets.
Papaya: Practical, Private, and Scalable Federated Learning
Nov 08, 2021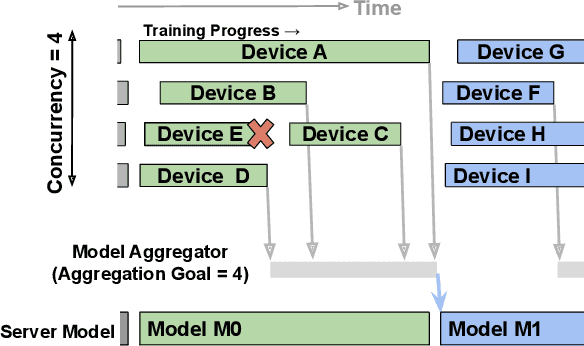
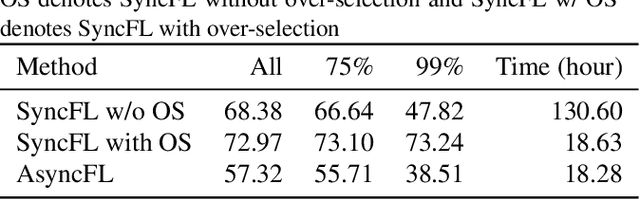
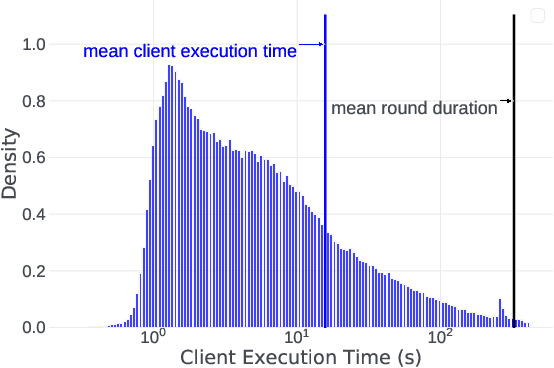
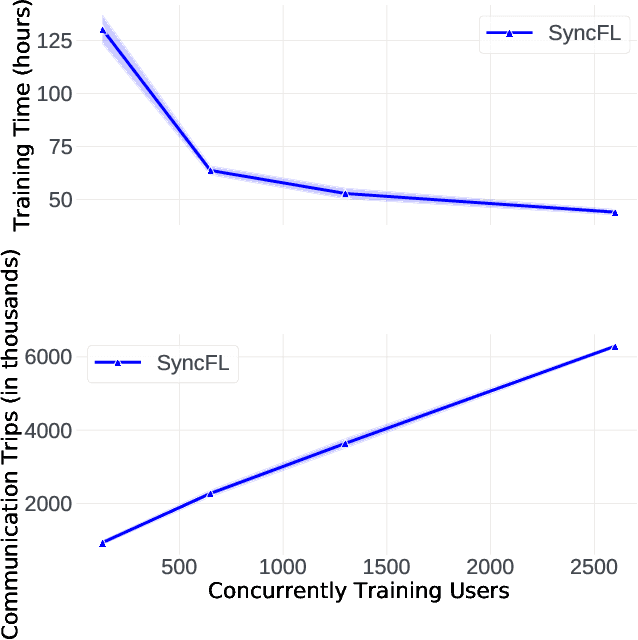
Cross-device Federated Learning (FL) is a distributed learning paradigm with several challenges that differentiate it from traditional distributed learning, variability in the system characteristics on each device, and millions of clients coordinating with a central server being primary ones. Most FL systems described in the literature are synchronous - they perform a synchronized aggregation of model updates from individual clients. Scaling synchronous FL is challenging since increasing the number of clients training in parallel leads to diminishing returns in training speed, analogous to large-batch training. Moreover, stragglers hinder synchronous FL training. In this work, we outline a production asynchronous FL system design. Our work tackles the aforementioned issues, sketches of some of the system design challenges and their solutions, and touches upon principles that emerged from building a production FL system for millions of clients. Empirically, we demonstrate that asynchronous FL converges faster than synchronous FL when training across nearly one hundred million devices. In particular, in high concurrency settings, asynchronous FL is 5x faster and has nearly 8x less communication overhead than synchronous FL.
Convex Latent Effect Logit Model via Sparse and Low-rank Decomposition
Aug 22, 2021
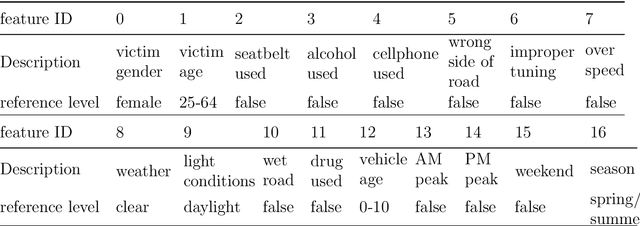
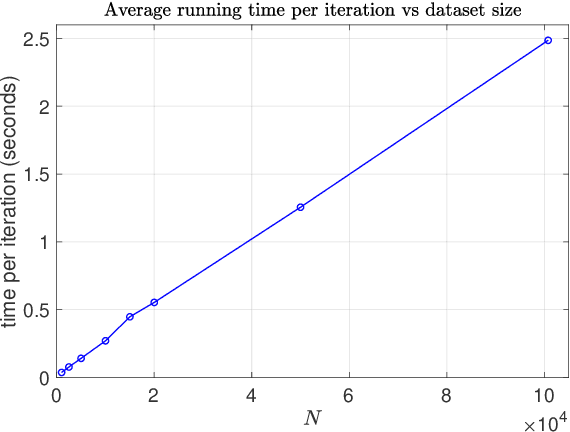
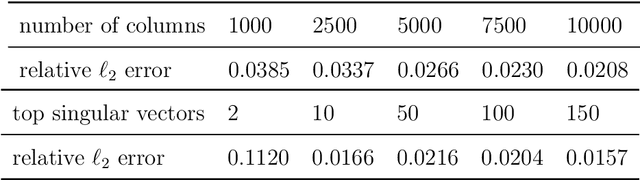
In this paper, we propose a convex formulation for learning logistic regression model (logit) with latent heterogeneous effect on sub-population. In transportation, logistic regression and its variants are often interpreted as discrete choice models under utility theory (McFadden, 2001). Two prominent applications of logit models in the transportation domain are traffic accident analysis and choice modeling. In these applications, researchers often want to understand and capture the individual variation under the same accident or choice scenario. The mixed effect logistic regression (mixed logit) is a popular model employed by transportation researchers. To estimate the distribution of mixed logit parameters, a non-convex optimization problem with nested high-dimensional integrals needs to be solved. Simulation-based optimization is typically applied to solve the mixed logit parameter estimation problem. Despite its popularity, the mixed logit approach for learning individual heterogeneity has several downsides. First, the parametric form of the distribution requires domain knowledge and assumptions imposed by users, although this issue can be addressed to some extent by using a non-parametric approach. Second, the optimization problems arise from parameter estimation for mixed logit and the non-parametric extensions are non-convex, which leads to unstable model interpretation. Third, the simulation size in simulation-assisted estimation lacks finite-sample theoretical guarantees and is chosen somewhat arbitrarily in practice. To address these issues, we are motivated to develop a formulation that models the latent individual heterogeneity while preserving convexity, and avoids the need for simulation-based approximation. Our setup is based on decomposing the parameters into a sparse homogeneous component in the population and low-rank heterogeneous parts for each individual.