 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Zero-Shot Frame Semantic Parsing with Task Agnostic Ontologies and Simple Labels
May 05, 2023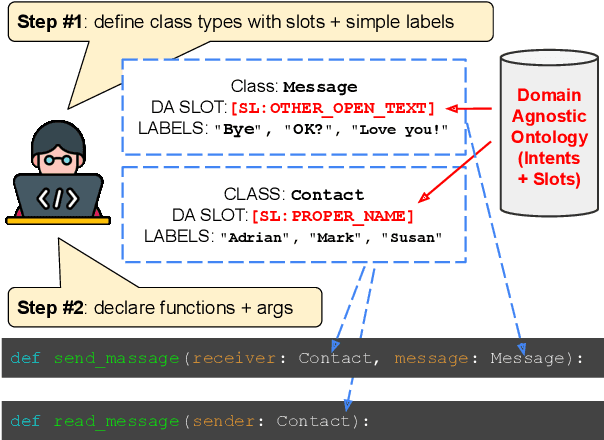
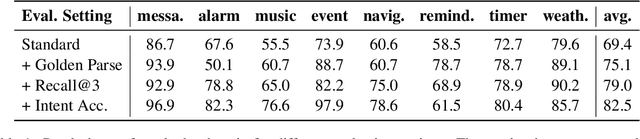
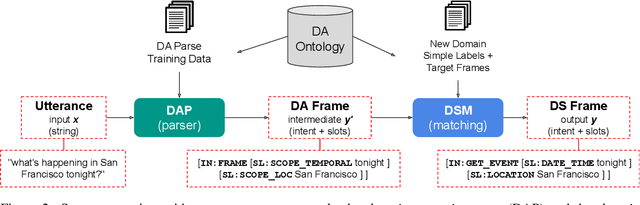
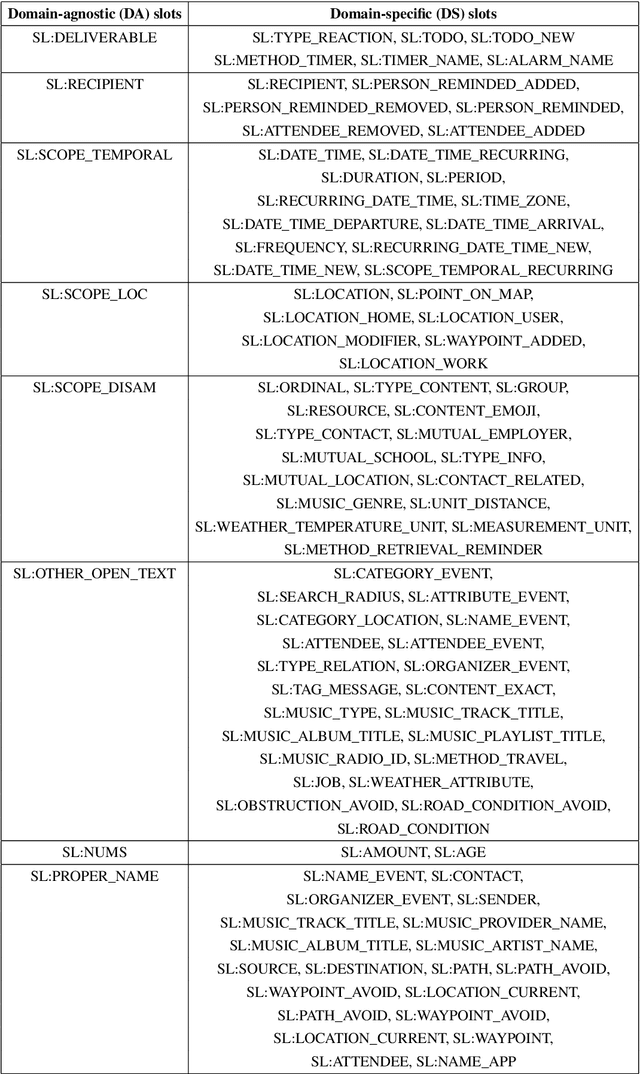
Frame semantic parsing is an important component of task-oriented dialogue systems. Current models rely on a significant amount training data to successfully identify the intent and slots in the user's input utterance. This creates a significant barrier for adding new domains to virtual assistant capabilities, as creation of this data requires highly specialized NLP expertise. In this work we propose OpenFSP, a framework that allows for easy creation of new domains from a handful of simple labels that can be generated without specific NLP knowledge. Our approach relies on creating a small, but expressive, set of domain agnostic slot types that enables easy annotation of new domains. Given such annotation, a matching algorithm relying on sentence encoders predicts the intent and slots for domains defined by end-users. Extensive experiments on the TopV2 dataset shows that our model outperforms strong baselines in this simple labels setting.
FedSynth: Gradient Compression via Synthetic Data in Federated Learning
Apr 04, 2022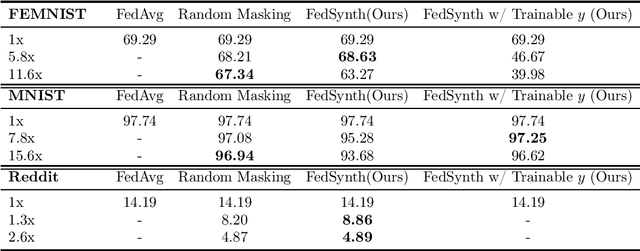
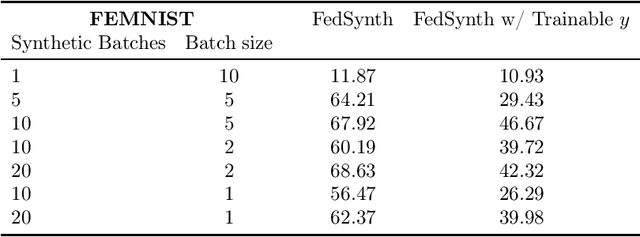

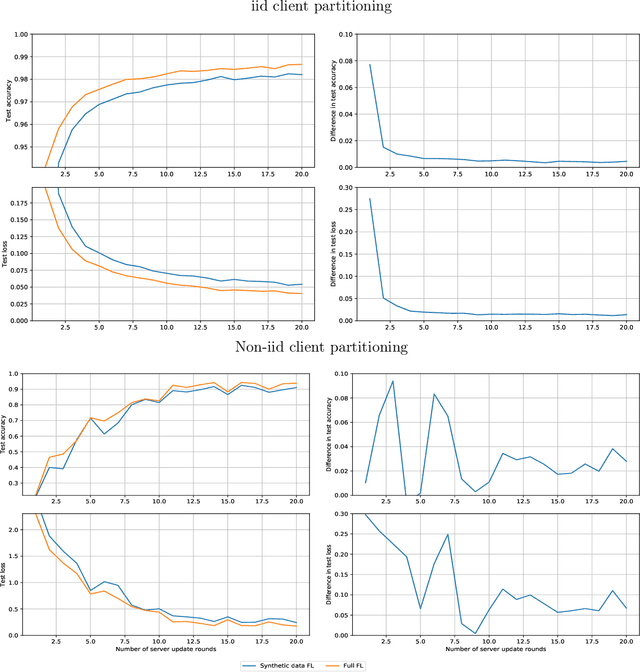
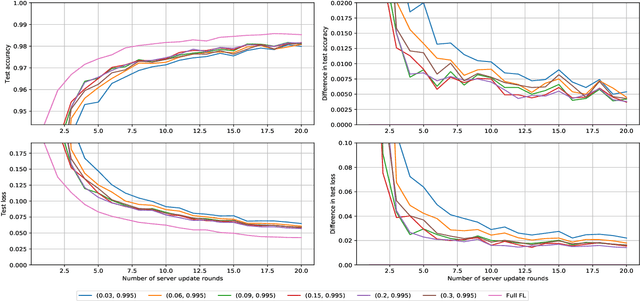
Model compression is important in federated learning (FL) with large models to reduce communication cost. Prior works have been focusing on sparsification based compression that could desparately affect the global model accuracy. In this work, we propose a new scheme for upstream communication where instead of transmitting the model update, each client learns and transmits a light-weight synthetic dataset such that using it as the training data, the model performs similarly well on the real training data. The server will recover the local model update via the synthetic data and apply standard aggregation. We then provide a new algorithm FedSynth to learn the synthetic data locally. Empirically, we find our method is comparable/better than random masking baselines in all three common federated learning benchmark datasets.
AutoNLU: Detecting, root-causing, and fixing NLU model errors
Oct 12, 2021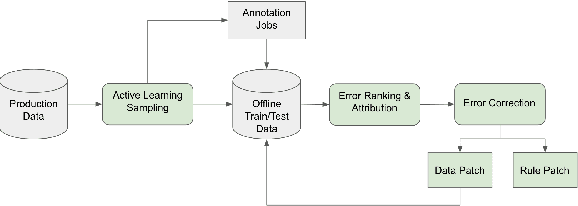

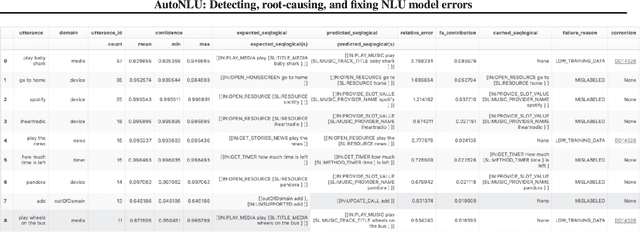

Improving the quality of Natural Language Understanding (NLU) models, and more specifically, task-oriented semantic parsing models, in production is a cumbersome task. In this work, we present a system called AutoNLU, which we designed to scale the NLU quality improvement process. It adds automation to three key steps: detection, attribution, and correction of model errors, i.e., bugs. We detected four times more failed tasks than with random sampling, finding that even a simple active learning sampling method on an uncalibrated model is surprisingly effective for this purpose. The AutoNLU tool empowered linguists to fix ten times more semantic parsing bugs than with prior manual processes, auto-correcting 65% of all identified bugs.
Federated Learning via Synthetic Data
Aug 11, 2020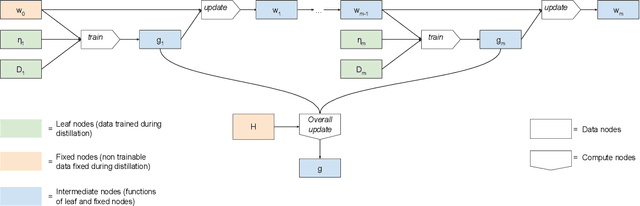

Federated learning allows for the training of a model using data on multiple clients without the clients transmitting that raw data. However the standard method is to transmit model parameters (or updates), which for modern neural networks can be on the scale of millions of parameters, inflicting significant computational costs on the clients. We propose a method for federated learning where instead of transmitting a gradient update back to the server, we instead transmit a small amount of synthetic `data'. We describe the procedure and show some experimental results suggesting this procedure has potential, providing more than an order of magnitude reduction in communication costs with minimal model degradation.
Not All are Made Equal: Consistency of Weighted Averaging Estimators Under Active Learning
Oct 11, 2019
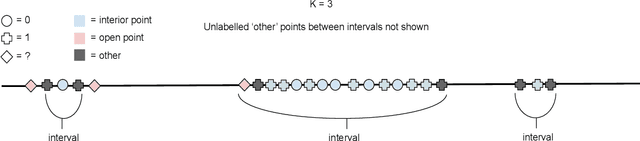
Active learning seeks to build the best possible model with a budget of labelled data by sequentially selecting the next point to label. However the training set is no longer \textit{iid}, violating the conditions required by existing consistency results. Inspired by the success of Stone's Theorem we aim to regain consistency for weighted averaging estimators under active learning. Based on ideas in \citet{dasgupta2012consistency}, our approach is to enforce a small amount of random sampling by running an augmented version of the underlying active learning algorithm. We generalize Stone's Theorem in the noise free setting, proving consistency for well known classifiers such as $k$-NN, histogram and kernel estimators under conditions which mirror classical results. However in the presence of noise we can no longer deal with these estimators in a unified manner; for some satisfying this condition also guarantees sufficiency in the noisy case, while for others we can achieve near perfect inconsistency while this condition holds. Finally we provide conditions for consistency in the presence of noise, which give insight into why these estimators can behave so differently under the combination of noise and active learning.
Active Federated Learning
Sep 27, 2019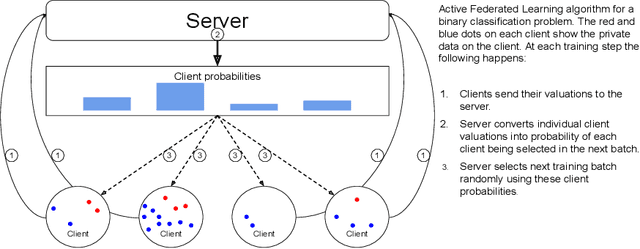

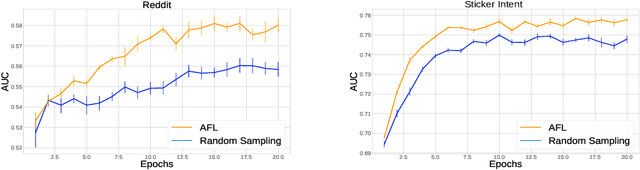
Federated Learning allows for population level models to be trained without centralizing client data by transmitting the global model to clients, calculating gradients locally, then averaging the gradients. Downloading models and uploading gradients uses the client's bandwidth, so minimizing these transmission costs is important. The data on each client is highly variable, so the benefit of training on different clients may differ dramatically. To exploit this we propose Active Federated Learning, where in each round clients are selected not uniformly at random, but with a probability conditioned on the current model and the data on the client to maximize efficiency. We propose a cheap, simple and intuitive sampling scheme which reduces the number of required training iterations by 20-70% while maintaining the same model accuracy, and which mimics well known resampling techniques under certain conditions.
Federated User Representation Learning
Sep 27, 2019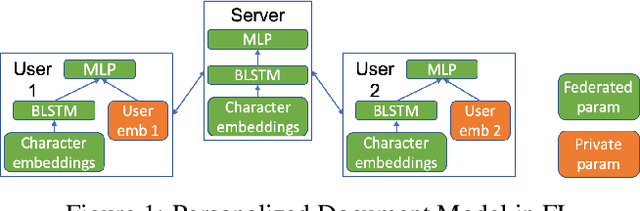

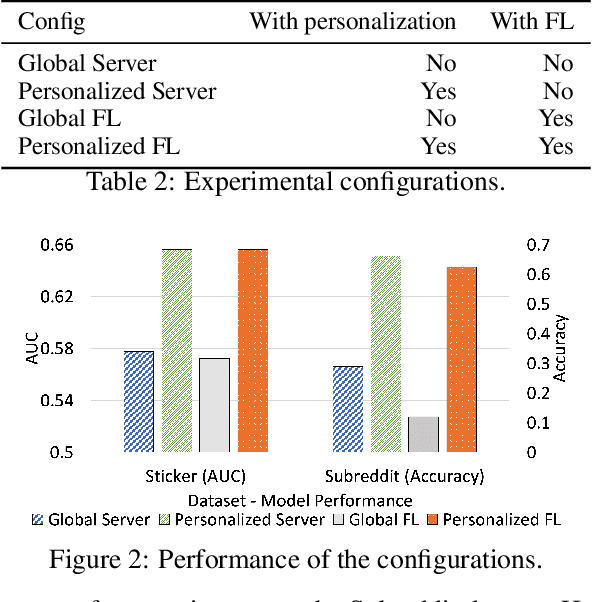
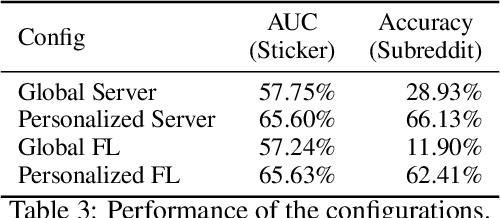
Collaborative personalization, such as through learned user representations (embeddings), can improve the prediction accuracy of neural-network-based models significantly. We propose Federated User Representation Learning (FURL), a simple, scalable, privacy-preserving and resource-efficient way to utilize existing neural personalization techniques in the Federated Learning (FL) setting. FURL divides model parameters into federated and private parameters. Private parameters, such as private user embeddings, are trained locally, but unlike federated parameters, they are not transferred to or averaged on the server. We show theoretically that this parameter split does not affect training for most model personalization approaches. Storing user embeddings locally not only preserves user privacy, but also improves memory locality of personalization compared to on-server training. We evaluate FURL on two datasets, demonstrating a significant improvement in model quality with 8% and 51% performance increases, and approximately the same level of performance as centralized training with only 0% and 4% reductions. Furthermore, we show that user embeddings learned in FL and the centralized setting have a very similar structure, indicating that FURL can learn collaboratively through the shared parameters while preserving user privacy.
Online Multiclass Boosting
Feb 25, 2018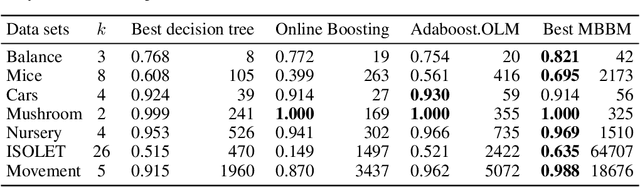
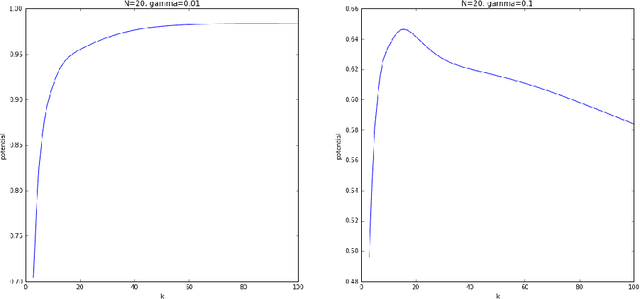
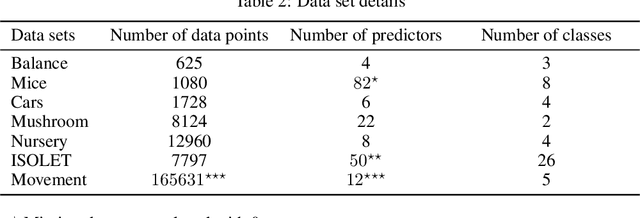
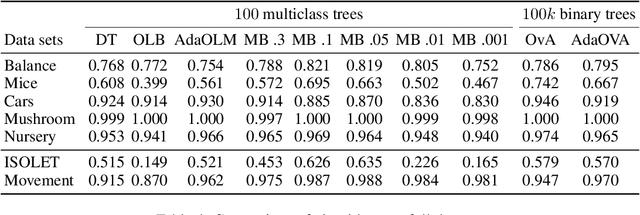
Recent work has extended the theoretical analysis of boosting algorithms to multiclass problems and to online settings. However, the multiclass extension is in the batch setting and the online extensions only consider binary classification. We fill this gap in the literature by defining, and justifying, a weak learning condition for online multiclass boosting. This condition leads to an optimal boosting algorithm that requires the minimal number of weak learners to achieve a certain accuracy. Additionally, we propose an adaptive algorithm which is near optimal and enjoys an excellent performance on real data due to its adaptive property.