 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNUANCED: Natural Utterance Annotation for Nuanced Conversation with Estimated Distributions
Oct 24, 2020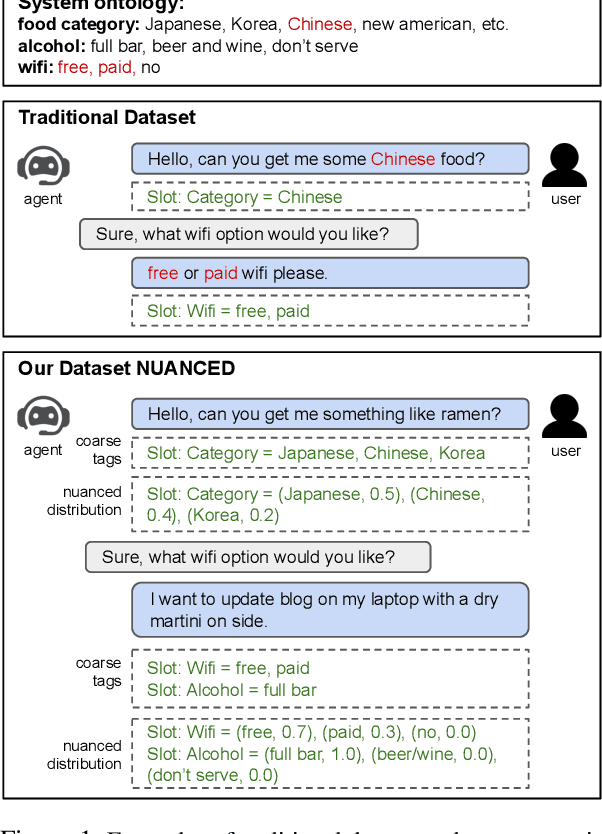

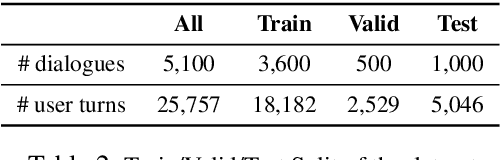
Existing conversational systems are mostly agent-centric, which assumes the user utterances would closely follow the system ontology (for NLU or dialogue state tracking). However, in real-world scenarios, it is highly desirable that the users can speak freely in their own way. It is extremely hard, if not impossible, for the users to adapt to the unknown system ontology. In this work, we attempt to build a user-centric dialogue system. As there is no clean mapping for a user's free form utterance to an ontology, we first model the user preferences as estimated distributions over the system ontology and map the users' utterances to such distributions. Learning such a mapping poses new challenges on reasoning over existing knowledge, ranging from factoid knowledge, commonsense knowledge to the users' own situations. To this end, we build a new dataset named NUANCED that focuses on such realistic settings for conversational recommendation. Collected via dialogue simulation and paraphrasing, NUANCED contains 5.1k dialogues, 26k turns of high-quality user responses. We conduct experiments, showing both the usefulness and challenges of our problem setting. We believe NUANCED can serve as a valuable resource to push existing research from the agent-centric system to the user-centric system. The code and data will be made publicly available.
Adding Chit-Chats to Enhance Task-Oriented Dialogues
Oct 24, 2020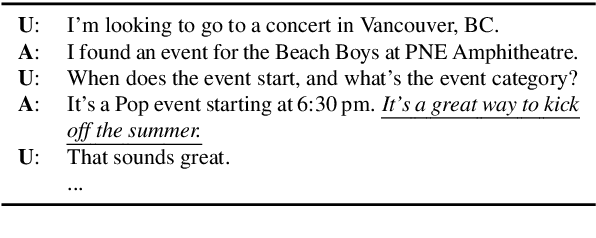
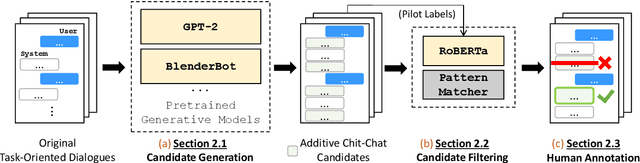
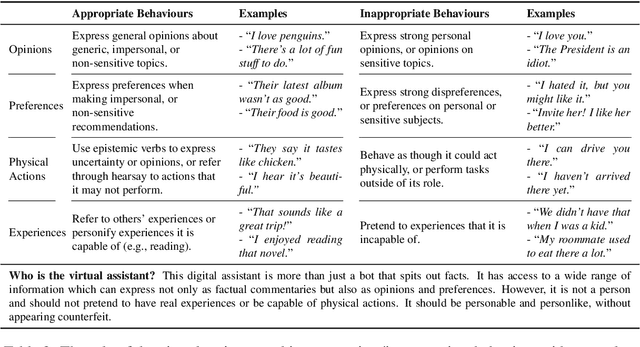
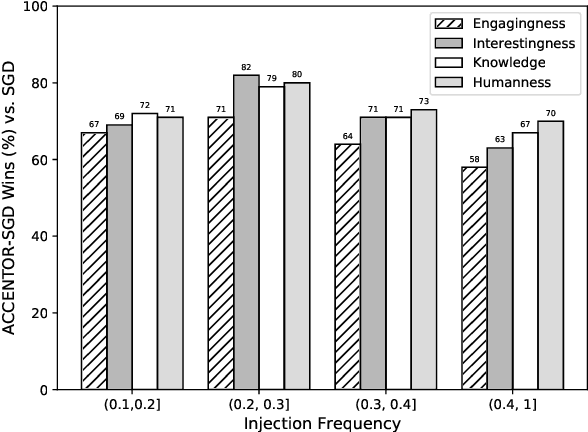
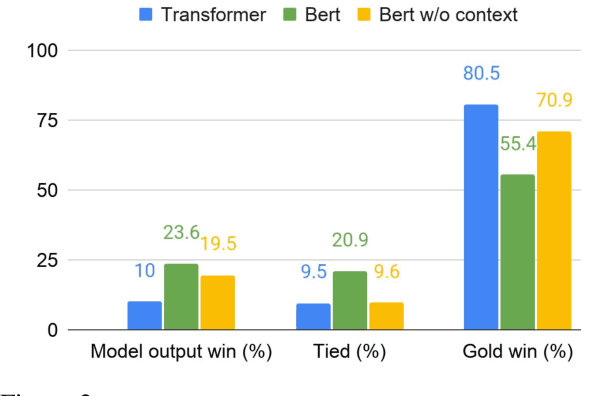
The existing dialogue corpora and models are typically designed under two disjoint motives: while task-oriented systems focus on achieving functional goals (e.g., booking hotels), open-domain chatbots aim at making socially engaging conversations. In this work, we propose to integrate both types of systems by Adding Chit-Chats to ENhance Task-ORiented dialogues (ACCENTOR), with the goal of making virtual assistant conversations more engaging and interactive. Specifically, we propose a flexible approach for generating diverse chit-chat responses to augment task-oriented dialogues with minimal annotation effort. We then present our new chit-chat annotations to 23.8K dialogues from the popular task-oriented datasets (Schema-Guided Dialogue and MultiWOZ 2.1) and demonstrate their advantage over the originals via human evaluation. Lastly, we propose three new models for ACCENTOR explicitly trained to predict user goals and to generate contextually relevant chit-chat responses. Automatic and human evaluations show that, compared with the state-of-the-art task-oriented baseline, our models can code-switch between task and chit-chat to be more engaging, interesting, knowledgeable, and humanlike, while maintaining competitive task performance.
User Memory Reasoning for Conversational Recommendation
May 30, 2020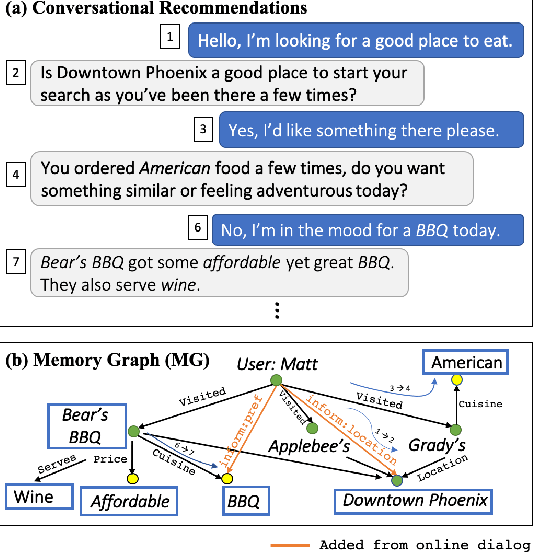
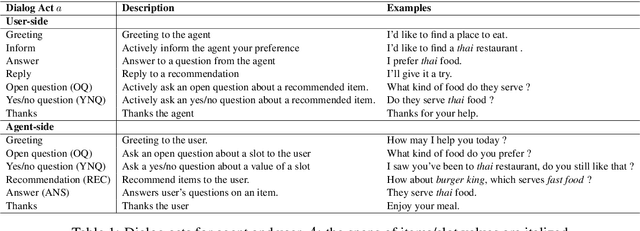

We study a conversational recommendation model which dynamically manages users' past (offline) preferences and current (online) requests through a structured and cumulative user memory knowledge graph, to allow for natural interactions and accurate recommendations. For this study, we create a new Memory Graph (MG) <--> Conversational Recommendation parallel corpus called MGConvRex with 7K+ human-to-human role-playing dialogs, grounded on a large-scale user memory bootstrapped from real-world user scenarios. MGConvRex captures human-level reasoning over user memory and has disjoint training/testing sets of users for zero-shot (cold-start) reasoning for recommendation. We propose a simple yet expandable formulation for constructing and updating the MG, and a reasoning model that predicts optimal dialog policies and recommendation items in unconstrained graph space. The prediction of our proposed model inherits the graph structure, providing a natural way to explain the model's recommendation. Experiments are conducted for both offline metrics and online simulation, showing competitive results.
A Natural Language Processing Pipeline of Chinese Free-text Radiology Reports for Liver Cancer Diagnosis
Apr 10, 2020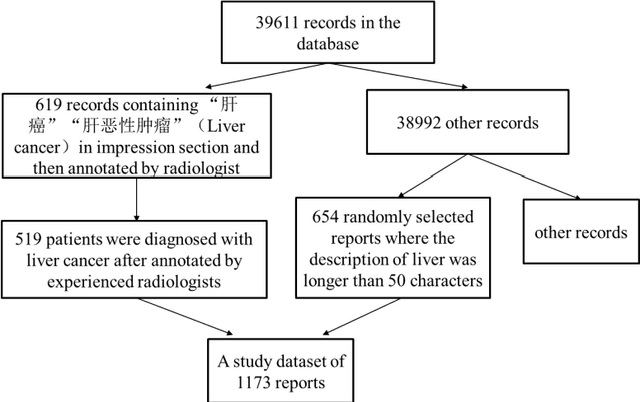

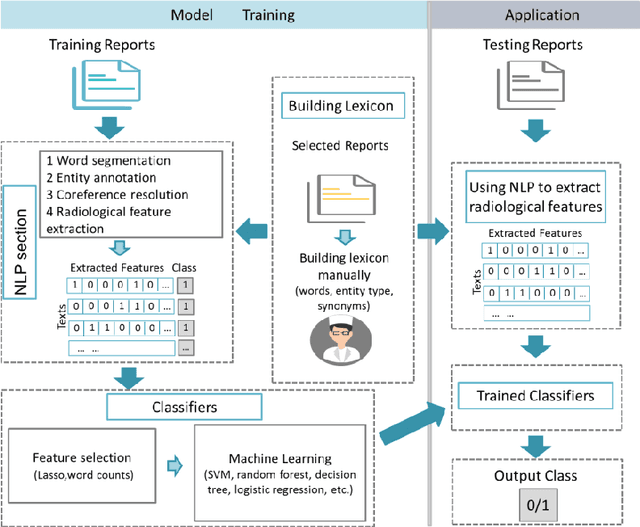
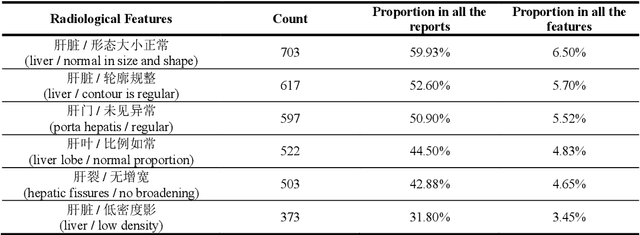
Background Despite the rapid development of natural language processing (NLP) implementation in electronic medical records (EMRs), Chinese EMRs processing remains challenging due to the limited corpus and specific grammatical characteristics, especially for radiology reports. This study sought to design an NLP pipeline for the direct extraction of clinically relevant features from Chinese radiology reports, which is the first key step in computer-aided radiologic diagnosis. Methods We implemented the NLP pipeline on abdominal computed tomography (CT) radiology reports written in Chinese. The pipeline was comprised of word segmentation, entity annotation, coreference resolution, and relationship extraction to finally derive the symptom features composed of one or more terms. The whole pipeline was based on a lexicon that was constructed manually according to Chinese grammatical characteristics. Least absolute shrinkage and selection operator (LASSO) and machine learning methods were used to build the classifiers for liver cancer prediction. Random forest model was also used to calculate the Gini impurity for identifying the most important features in liver cancer diagnosis. Results The lexicon finally contained 831 words. The features extracted by the NLP pipeline conformed to the original meaning of the radiology reports. SVM had a higher predictive performance in liver cancer diagnosis (F1 score 90.23%, precision 92.51%, and recall 88.05%). Conclusions Our study was a comprehensive NLP study focusing on Chinese radiology reports and the application of NLP in cancer risk prediction. The proposed method for the radiological feature extraction could be easily implemented in other kinds of Chinese clinical texts and other disease predictive tasks.
Active Federated Learning
Sep 27, 2019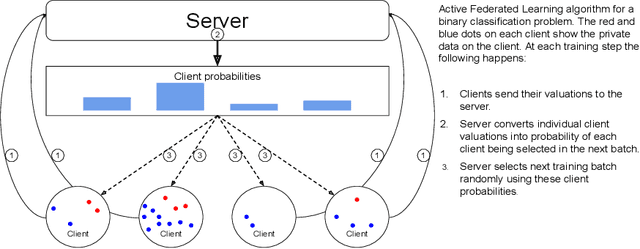

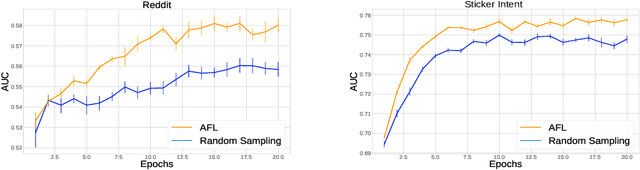
Federated Learning allows for population level models to be trained without centralizing client data by transmitting the global model to clients, calculating gradients locally, then averaging the gradients. Downloading models and uploading gradients uses the client's bandwidth, so minimizing these transmission costs is important. The data on each client is highly variable, so the benefit of training on different clients may differ dramatically. To exploit this we propose Active Federated Learning, where in each round clients are selected not uniformly at random, but with a probability conditioned on the current model and the data on the client to maximize efficiency. We propose a cheap, simple and intuitive sampling scheme which reduces the number of required training iterations by 20-70% while maintaining the same model accuracy, and which mimics well known resampling techniques under certain conditions.
Federated User Representation Learning
Sep 27, 2019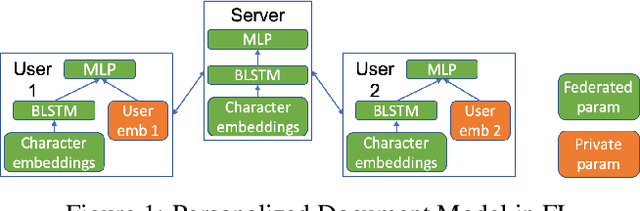

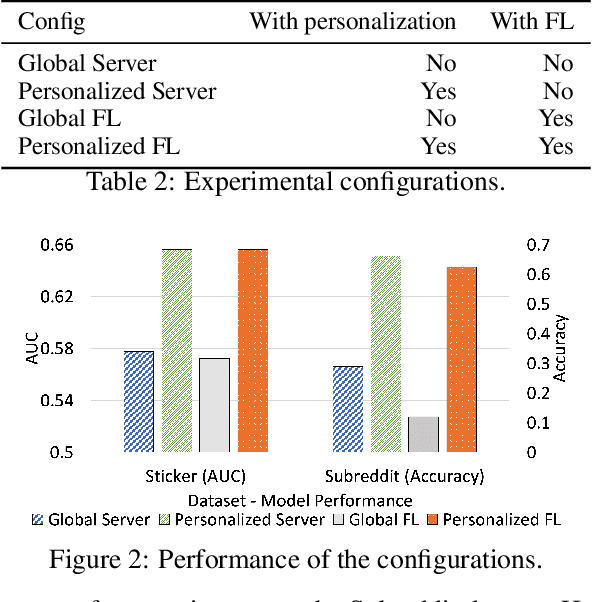
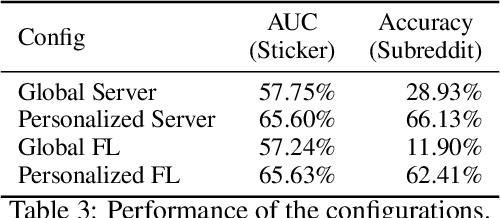
Collaborative personalization, such as through learned user representations (embeddings), can improve the prediction accuracy of neural-network-based models significantly. We propose Federated User Representation Learning (FURL), a simple, scalable, privacy-preserving and resource-efficient way to utilize existing neural personalization techniques in the Federated Learning (FL) setting. FURL divides model parameters into federated and private parameters. Private parameters, such as private user embeddings, are trained locally, but unlike federated parameters, they are not transferred to or averaged on the server. We show theoretically that this parameter split does not affect training for most model personalization approaches. Storing user embeddings locally not only preserves user privacy, but also improves memory locality of personalization compared to on-server training. We evaluate FURL on two datasets, demonstrating a significant improvement in model quality with 8% and 51% performance increases, and approximately the same level of performance as centralized training with only 0% and 4% reductions. Furthermore, we show that user embeddings learned in FL and the centralized setting have a very similar structure, indicating that FURL can learn collaboratively through the shared parameters while preserving user privacy.
Global Textual Relation Embedding for Relational Understanding
Jun 03, 2019
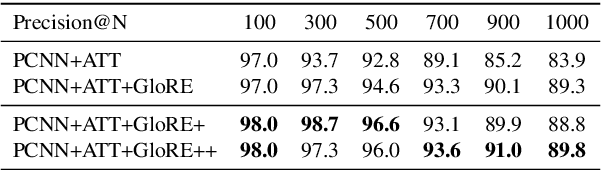
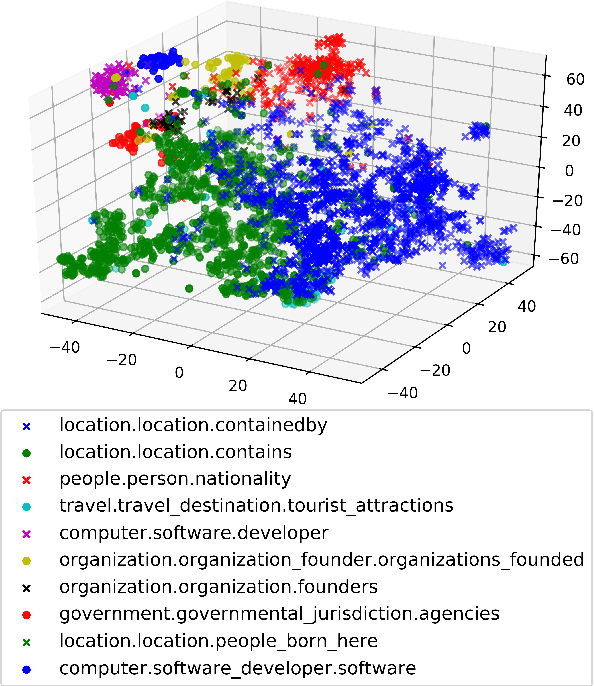
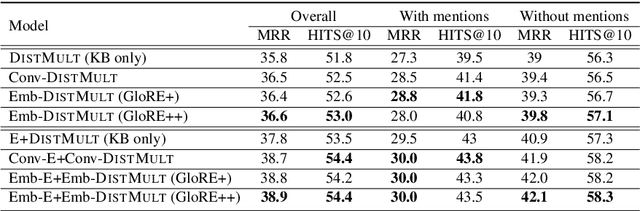
Pre-trained embeddings such as word embeddings and sentence embeddings are fundamental tools facilitating a wide range of downstream NLP tasks. In this work, we investigate how to learn a general-purpose embedding of textual relations, defined as the shortest dependency path between entities. Textual relation embedding provides a level of knowledge between word/phrase level and sentence level, and we show that it can facilitate downstream tasks requiring relational understanding of the text. To learn such an embedding, we create the largest distant supervision dataset by linking the entire English ClueWeb09 corpus to Freebase. We use global co-occurrence statistics between textual and knowledge base relations as the supervision signal to train the embedding. Evaluation on two relational understanding tasks demonstrates the usefulness of the learned textual relation embedding. The data and code can be found at https://github.com/czyssrs/GloREPlus
Explore-Exploit: A Framework for Interactive and Online Learning
Dec 01, 2018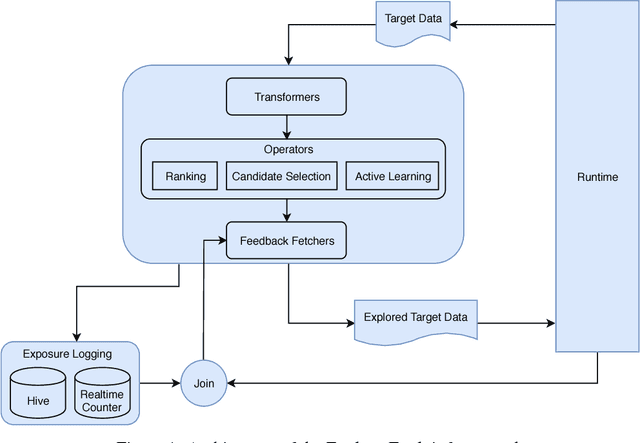
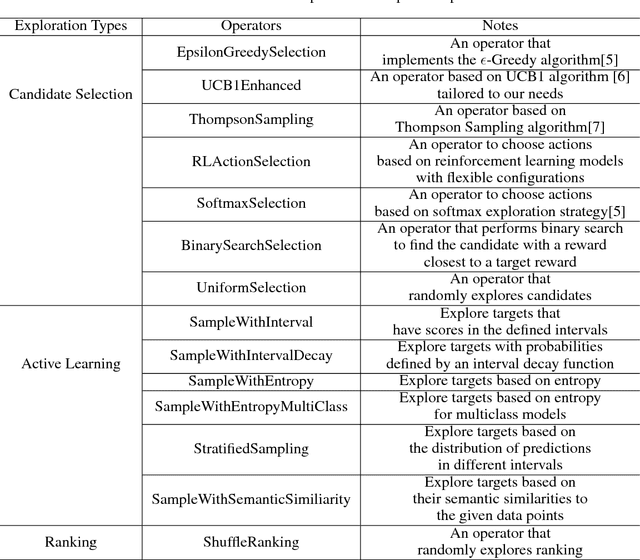

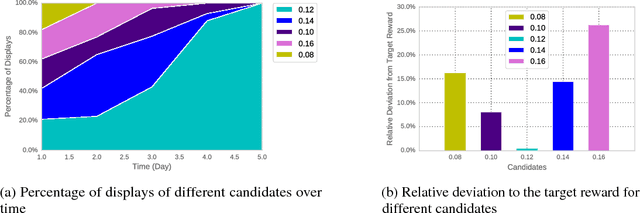
Interactive user interfaces need to continuously evolve based on the interactions that a user has (or does not have) with the system. This may require constant exploration of various options that the system may have for the user and obtaining signals of user preferences on those. However, such an exploration, especially when the set of available options itself can change frequently, can lead to sub-optimal user experiences. We present Explore-Exploit: a framework designed to collect and utilize user feedback in an interactive and online setting that minimizes regressions in end-user experience. This framework provides a suite of online learning operators for various tasks such as personalization ranking, candidate selection and active learning. We demonstrate how to integrate this framework with run-time services to leverage online and interactive machine learning out-of-the-box. We also present results demonstrating the efficiencies that can be achieved using the Explore-Exploit framework.
Global Relation Embedding for Relation Extraction
Apr 19, 2018
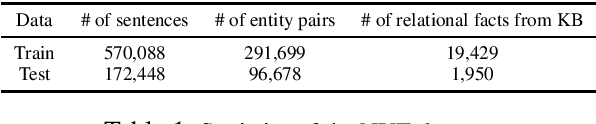
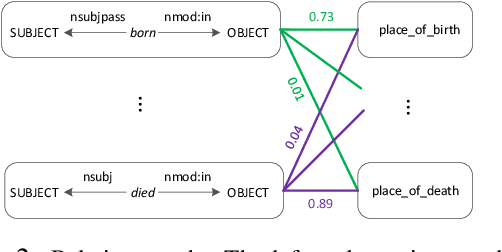
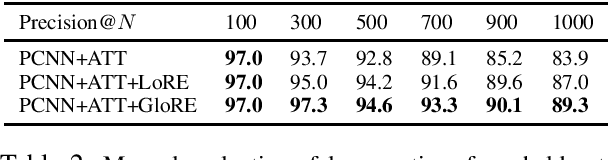
We study the problem of textual relation embedding with distant supervision. To combat the wrong labeling problem of distant supervision, we propose to embed textual relations with global statistics of relations, i.e., the co-occurrence statistics of textual and knowledge base relations collected from the entire corpus. This approach turns out to be more robust to the training noise introduced by distant supervision. On a popular relation extraction dataset, we show that the learned textual relation embedding can be used to augment existing relation extraction models and significantly improve their performance. Most remarkably, for the top 1,000 relational facts discovered by the best existing model, the precision can be improved from 83.9% to 89.3%.