 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
VideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice
Jan 08, 2026Chain-of-thought (CoT) reasoning has emerged as a powerful tool for multimodal large language models on video understanding tasks. However, its necessity and advantages over direct answering remain underexplored. In this paper, we first demonstrate that for RL-trained video models, direct answering often matches or even surpasses CoT performance, despite CoT producing step-by-step analyses at a higher computational cost. Motivated by this, we propose VideoAuto-R1, a video understanding framework that adopts a reason-when-necessary strategy. During training, our approach follows a Thinking Once, Answering Twice paradigm: the model first generates an initial answer, then performs reasoning, and finally outputs a reviewed answer. Both answers are supervised via verifiable rewards. During inference, the model uses the confidence score of the initial answer to determine whether to proceed with reasoning. Across video QA and grounding benchmarks, VideoAuto-R1 achieves state-of-the-art accuracy with significantly improved efficiency, reducing the average response length by ~3.3x, e.g., from 149 to just 44 tokens. Moreover, we observe a low rate of thinking-mode activation on perception-oriented tasks, but a higher rate on reasoning-intensive tasks. This suggests that explicit language-based reasoning is generally beneficial but not always necessary.
In Pursuit of Pixel Supervision for Visual Pre-training
Dec 17, 2025At the most basic level, pixels are the source of the visual information through which we perceive the world. Pixels contain information at all levels, ranging from low-level attributes to high-level concepts. Autoencoders represent a classical and long-standing paradigm for learning representations from pixels or other raw inputs. In this work, we demonstrate that autoencoder-based self-supervised learning remains competitive today and can produce strong representations for downstream tasks, while remaining simple, stable, and efficient. Our model, codenamed "Pixio", is an enhanced masked autoencoder (MAE) with more challenging pre-training tasks and more capable architectures. The model is trained on 2B web-crawled images with a self-curation strategy with minimal human curation. Pixio performs competitively across a wide range of downstream tasks in the wild, including monocular depth estimation (e.g., Depth Anything), feed-forward 3D reconstruction (i.e., MapAnything), semantic segmentation, and robot learning, outperforming or matching DINOv3 trained at similar scales. Our results suggest that pixel-space self-supervised learning can serve as a promising alternative and a complement to latent-space approaches.
MetaCLIP 2: A Worldwide Scaling Recipe
Jul 29, 2025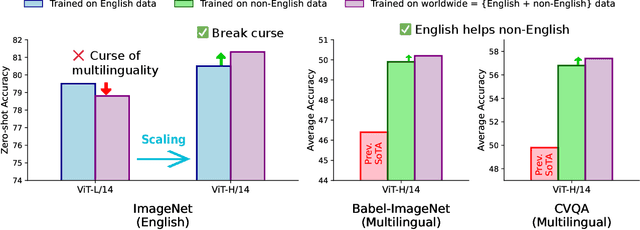
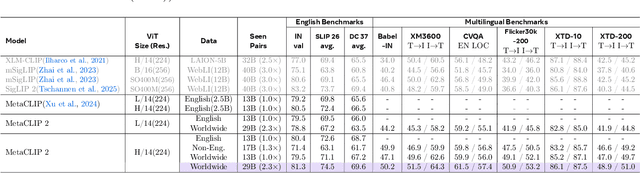
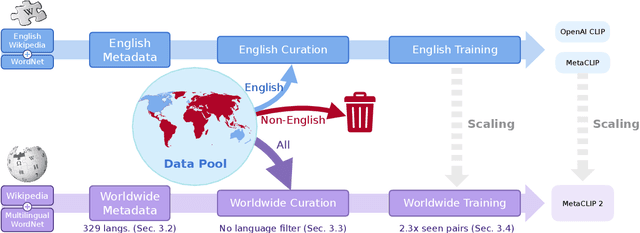

Contrastive Language-Image Pretraining (CLIP) is a popular foundation model, supporting from zero-shot classification, retrieval to encoders for multimodal large language models (MLLMs). Although CLIP is successfully trained on billion-scale image-text pairs from the English world, scaling CLIP's training further to learning from the worldwide web data is still challenging: (1) no curation method is available to handle data points from non-English world; (2) the English performance from existing multilingual CLIP is worse than its English-only counterpart, i.e., "curse of multilinguality" that is common in LLMs. Here, we present MetaCLIP 2, the first recipe training CLIP from scratch on worldwide web-scale image-text pairs. To generalize our findings, we conduct rigorous ablations with minimal changes that are necessary to address the above challenges and present a recipe enabling mutual benefits from English and non-English world data. In zero-shot ImageNet classification, MetaCLIP 2 ViT-H/14 surpasses its English-only counterpart by 0.8% and mSigLIP by 0.7%, and surprisingly sets new state-of-the-art without system-level confounding factors (e.g., translation, bespoke architecture changes) on multilingual benchmarks, such as CVQA with 57.4%, Babel-ImageNet with 50.2% and XM3600 with 64.3% on image-to-text retrieval.
GM-LDM: Latent Diffusion Model for Brain Biomarker Identification through Functional Data-Driven Gray Matter Synthesis
Jun 15, 2025Generative models based on deep learning have shown significant potential in medical imaging, particularly for modality transformation and multimodal fusion in MRI-based brain imaging. This study introduces GM-LDM, a novel framework that leverages the latent diffusion model (LDM) to enhance the efficiency and precision of MRI generation tasks. GM-LDM integrates a 3D autoencoder, pre-trained on the large-scale ABCD MRI dataset, achieving statistical consistency through KL divergence loss. We employ a Vision Transformer (ViT)-based encoder-decoder as the denoising network to optimize generation quality. The framework flexibly incorporates conditional data, such as functional network connectivity (FNC) data, enabling personalized brain imaging, biomarker identification, and functional-to-structural information translation for brain diseases like schizophrenia.
Perception Encoder: The best visual embeddings are not at the output of the network
Apr 17, 2025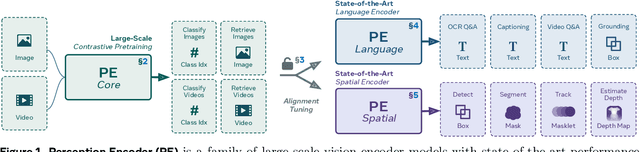

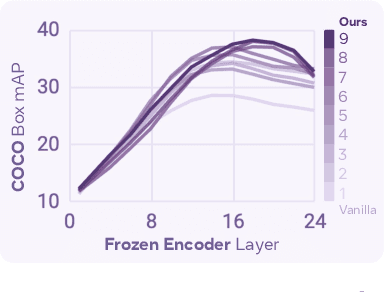
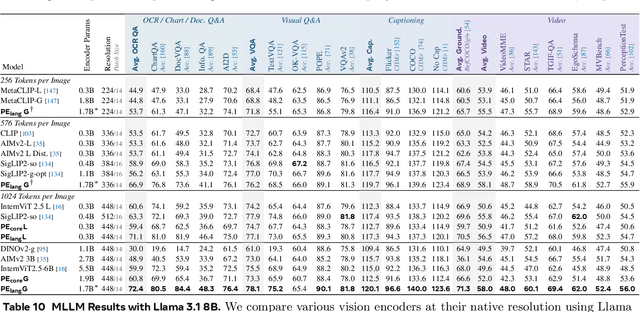
We introduce Perception Encoder (PE), a state-of-the-art encoder for image and video understanding trained via simple vision-language learning. Traditionally, vision encoders have relied on a variety of pretraining objectives, each tailored to specific downstream tasks such as classification, captioning, or localization. Surprisingly, after scaling our carefully tuned image pretraining recipe and refining with our robust video data engine, we find that contrastive vision-language training alone can produce strong, general embeddings for all of these downstream tasks. There is only one caveat: these embeddings are hidden within the intermediate layers of the network. To draw them out, we introduce two alignment methods, language alignment for multimodal language modeling, and spatial alignment for dense prediction. Together with the core contrastive checkpoint, our PE family of models achieves state-of-the-art performance on a wide variety of tasks, including zero-shot image and video classification and retrieval; document, image, and video Q&A; and spatial tasks such as detection, depth estimation, and tracking. To foster further research, we are releasing our models, code, and a novel dataset of synthetically and human-annotated videos.
SelfCite: Self-Supervised Alignment for Context Attribution in Large Language Models
Feb 13, 2025



We introduce SelfCite, a novel self-supervised approach that aligns LLMs to generate high-quality, fine-grained, sentence-level citations for the statements in their generated responses. Instead of only relying on costly and labor-intensive annotations, SelfCite leverages a reward signal provided by the LLM itself through context ablation: If a citation is necessary, removing the cited text from the context should prevent the same response; if sufficient, retaining the cited text alone should preserve the same response. This reward can guide the inference-time best-of-N sampling strategy to improve citation quality significantly, as well as be used in preference optimization to directly fine-tune the models for generating better citations. The effectiveness of SelfCite is demonstrated by increasing citation F1 up to 5.3 points on the LongBench-Cite benchmark across five long-form question answering tasks.
General Information Metrics for Improving AI Model Training Efficiency
Jan 02, 2025



To address the growing size of AI model training data and the lack of a universal data selection methodology-factors that significantly drive up training costs -- this paper presents the General Information Metrics Evaluation (GIME) method. GIME leverages general information metrics from Objective Information Theory (OIT), including volume, delay, scope, granularity, variety, duration, sampling rate, aggregation, coverage, distortion, and mismatch to optimize dataset selection for training purposes. Comprehensive experiments conducted across diverse domains, such as CTR Prediction, Civil Case Prediction, and Weather Forecasting, demonstrate that GIME effectively preserves model performance while substantially reducing both training time and costs. Additionally, applying GIME within the Judicial AI Program led to a remarkable 39.56% reduction in total model training expenses, underscoring its potential to support efficient and sustainable AI development.
DINOv2 Meets Text: A Unified Framework for Image- and Pixel-Level Vision-Language Alignment
Dec 20, 2024



Self-supervised visual foundation models produce powerful embeddings that achieve remarkable performance on a wide range of downstream tasks. However, unlike vision-language models such as CLIP, self-supervised visual features are not readily aligned with language, hindering their adoption in open-vocabulary tasks. Our method, named dino.txt, unlocks this new ability for DINOv2, a widely used self-supervised visual encoder. We build upon the LiT training strategy, which trains a text encoder to align with a frozen vision model but leads to unsatisfactory results on dense tasks. We propose several key ingredients to improve performance on both global and dense tasks, such as concatenating the [CLS] token with the patch average to train the alignment and curating data using both text and image modalities. With these, we successfully train a CLIP-like model with only a fraction of the computational cost compared to CLIP while achieving state-of-the-art results in zero-shot classification and open-vocabulary semantic segmentation.
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Oct 22, 2024



Multimodal Large Language Models (MLLMs) have shown promising progress in understanding and analyzing video content. However, processing long videos remains a significant challenge constrained by LLM's context size. To address this limitation, we propose LongVU, a spatiotemporal adaptive compression mechanism thats reduces the number of video tokens while preserving visual details of long videos. Our idea is based on leveraging cross-modal query and inter-frame dependencies to adaptively reduce temporal and spatial redundancy in videos. Specifically, we leverage DINOv2 features to remove redundant frames that exhibit high similarity. Then we utilize text-guided cross-modal query for selective frame feature reduction. Further, we perform spatial token reduction across frames based on their temporal dependencies. Our adaptive compression strategy effectively processes a large number of frames with little visual information loss within given context length. Our LongVU consistently surpass existing methods across a variety of video understanding benchmarks, especially on hour-long video understanding tasks such as VideoMME and MLVU. Given a light-weight LLM, our LongVU also scales effectively into a smaller size with state-of-the-art video understanding performance.