 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Information Metrics for Improving AI Model Training Efficiency
Jan 02, 2025



To address the growing size of AI model training data and the lack of a universal data selection methodology-factors that significantly drive up training costs -- this paper presents the General Information Metrics Evaluation (GIME) method. GIME leverages general information metrics from Objective Information Theory (OIT), including volume, delay, scope, granularity, variety, duration, sampling rate, aggregation, coverage, distortion, and mismatch to optimize dataset selection for training purposes. Comprehensive experiments conducted across diverse domains, such as CTR Prediction, Civil Case Prediction, and Weather Forecasting, demonstrate that GIME effectively preserves model performance while substantially reducing both training time and costs. Additionally, applying GIME within the Judicial AI Program led to a remarkable 39.56% reduction in total model training expenses, underscoring its potential to support efficient and sustainable AI development.
PagPassGPT: Pattern Guided Password Guessing via Generative Pretrained Transformer
Apr 07, 2024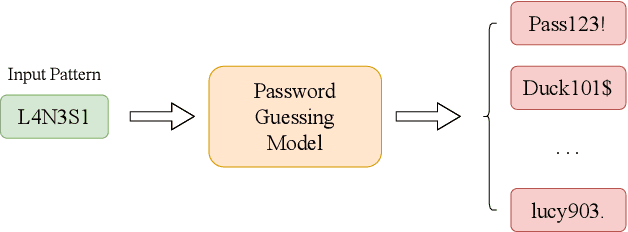
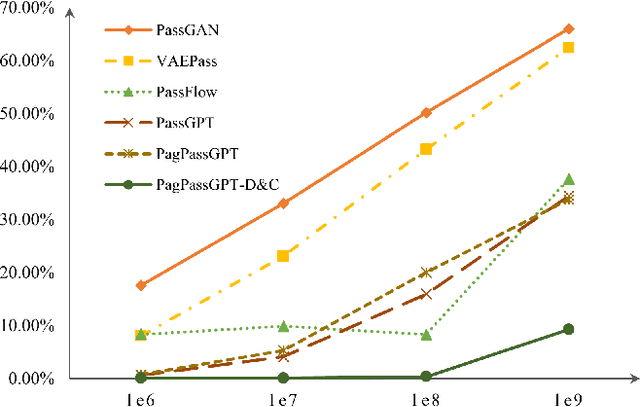
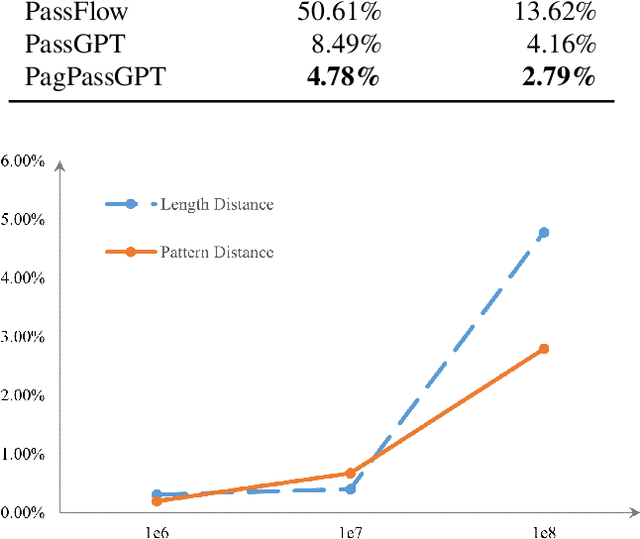
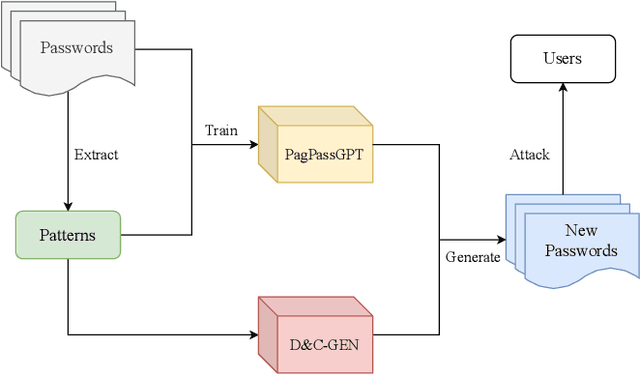
Amidst the surge in deep learning-based password guessing models, challenges of generating high-quality passwords and reducing duplicate passwords persist. To address these challenges, we present PagPassGPT, a password guessing model constructed on Generative Pretrained Transformer (GPT). It can perform pattern guided guessing by incorporating pattern structure information as background knowledge, resulting in a significant increase in the hit rate. Furthermore, we propose D&C-GEN to reduce the repeat rate of generated passwords, which adopts the concept of a divide-and-conquer approach. The primary task of guessing passwords is recursively divided into non-overlapping subtasks. Each subtask inherits the knowledge from the parent task and predicts succeeding tokens. In comparison to the state-of-the-art model, our proposed scheme exhibits the capability to correctly guess 12% more passwords while producing 25% fewer duplicates.
Goldfish: An Efficient Federated Unlearning Framework
Apr 04, 2024With recent legislation on the right to be forgotten, machine unlearning has emerged as a crucial research area. It facilitates the removal of a user's data from federated trained machine learning models without the necessity for retraining from scratch. However, current machine unlearning algorithms are confronted with challenges of efficiency and validity.To address the above issues, we propose a new framework, named Goldfish. It comprises four modules: basic model, loss function, optimization, and extension. To address the challenge of low validity in existing machine unlearning algorithms, we propose a novel loss function. It takes into account the loss arising from the discrepancy between predictions and actual labels in the remaining dataset. Simultaneously, it takes into consideration the bias of predicted results on the removed dataset. Moreover, it accounts for the confidence level of predicted results. Additionally, to enhance efficiency, we adopt knowledge distillation technique in basic model and introduce an optimization module that encompasses the early termination mechanism guided by empirical risk and the data partition mechanism. Furthermore, to bolster the robustness of the aggregated model, we propose an extension module that incorporates a mechanism using adaptive distillation temperature to address the heterogeneity of user local data and a mechanism using adaptive weight to handle the variety in the quality of uploaded models. Finally, we conduct comprehensive experiments to illustrate the effectiveness of proposed approach.