 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-CRCL: Bidirectional Conservative-Radical Complementary Learning with Pre-trained Foundation Models for Class-incremental Medical Image Analysis
Mar 24, 2026Class-incremental learning (CIL) in medical image-guided diagnosis requires retaining prior diagnostic knowledge while adapting to newly emerging disease categories, which is critical for scalable clinical deployment. This problem is particularly challenging due to heterogeneous data and privacy constraints that prevent memory replay. Although pretrained foundation models (PFMs) have advanced general-domain CIL, their potential in medical imaging remains underexplored, where domain-specific adaptation is essential yet difficult due to anatomical complexity and inter-institutional heterogeneity. To address this gap, we conduct a systematic benchmark of recent PFM-based CIL methods and propose Bidirectional Conservative-Radical Complementary Learning (Bi-CRCL), a dual-learner framework inspired by complementary learning systems. Bi-CRCL integrates a conservative learner that preserves prior knowledge through stability-oriented updates and a radical learner that rapidly adapts to new categories via plasticity-oriented learning. A bidirectional interaction mechanism enables forward transfer and backward consolidation, allowing continual integration of new knowledge while mitigating catastrophic forgetting. During inference, outputs from both learners are adaptively fused for robust predictions. Experiments on five medical imaging datasets demonstrate consistent improvements over state-of-the-art methods under diverse settings, including cross-dataset shifts and varying task configurations.
O-Mem: Omni Memory System for Personalized, Long Horizon, Self-Evolving Agents
Nov 18, 2025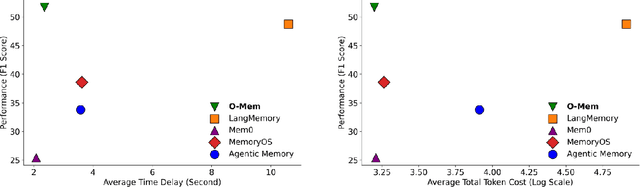
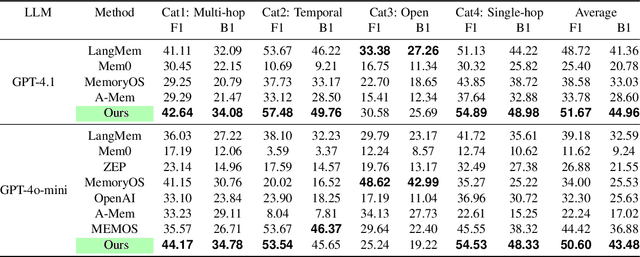
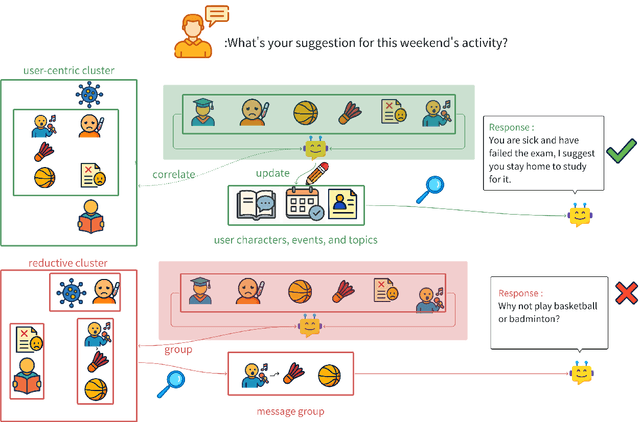

Recent advancements in LLM-powered agents have demonstrated significant potential in generating human-like responses; however, they continue to face challenges in maintaining long-term interactions within complex environments, primarily due to limitations in contextual consistency and dynamic personalization. Existing memory systems often depend on semantic grouping prior to retrieval, which can overlook semantically irrelevant yet critical user information and introduce retrieval noise. In this report, we propose the initial design of O-Mem, a novel memory framework based on active user profiling that dynamically extracts and updates user characteristics and event records from their proactive interactions with agents. O-Mem supports hierarchical retrieval of persona attributes and topic-related context, enabling more adaptive and coherent personalized responses. O-Mem achieves 51.67% on the public LoCoMo benchmark, a nearly 3% improvement upon LangMem,the previous state-of-the-art, and it achieves 62.99% on PERSONAMEM, a 3.5% improvement upon A-Mem,the previous state-of-the-art. O-Mem also boosts token and interaction response time efficiency compared to previous memory frameworks. Our work opens up promising directions for developing efficient and human-like personalized AI assistants in the future.
Stroke Modeling Enables Vectorized Character Generation with Large Vectorized Glyph Model
Nov 14, 2025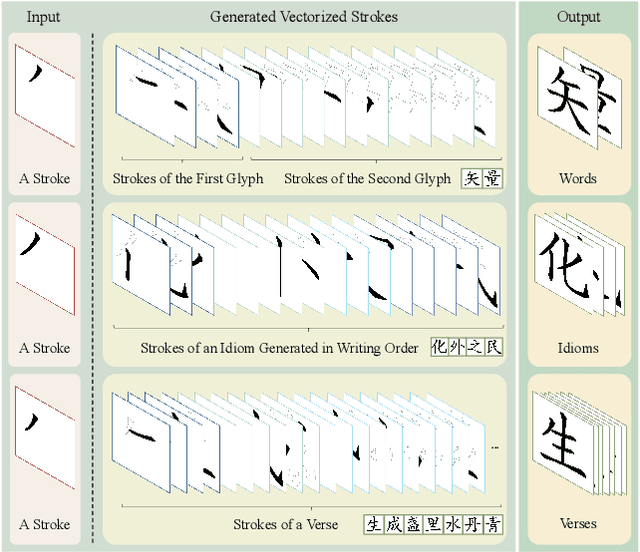
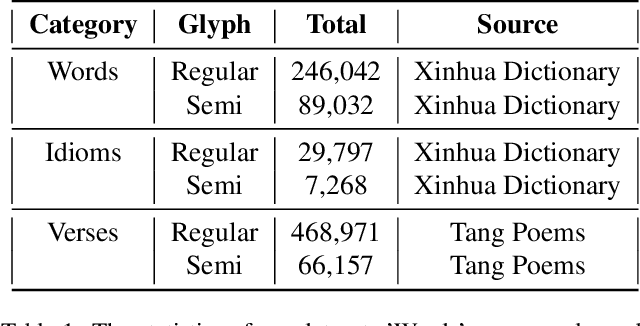
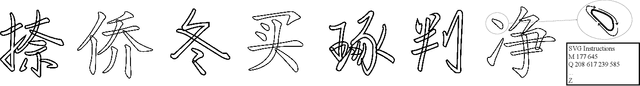
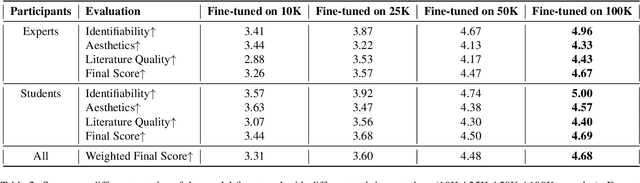
Vectorized glyphs are widely used in poster design, network animation, art display, and various other fields due to their scalability and flexibility. In typography, they are often seen as special sequences composed of ordered strokes. This concept extends to the token sequence prediction abilities of large language models (LLMs), enabling vectorized character generation through stroke modeling. In this paper, we propose a novel Large Vectorized Glyph Model (LVGM) designed to generate vectorized Chinese glyphs by predicting the next stroke. Initially, we encode strokes into discrete latent variables called stroke embeddings. Subsequently, we train our LVGM via fine-tuning DeepSeek LLM by predicting the next stroke embedding. With limited strokes given, it can generate complete characters, semantically elegant words, and even unseen verses in vectorized form. Moreover, we release a new large-scale Chinese SVG dataset containing 907,267 samples based on strokes for dynamically vectorized glyph generation. Experimental results show that our model has scaling behaviors on data scales. Our generated vectorized glyphs have been validated by experts and relevant individuals.
How to Use Diffusion Priors under Sparse Views?
Dec 03, 2024Novel view synthesis under sparse views has been a long-term important challenge in 3D reconstruction. Existing works mainly rely on introducing external semantic or depth priors to supervise the optimization of 3D representations. However, the diffusion model, as an external prior that can directly provide visual supervision, has always underperformed in sparse-view 3D reconstruction using Score Distillation Sampling (SDS) due to the low information entropy of sparse views compared to text, leading to optimization challenges caused by mode deviation. To this end, we present a thorough analysis of SDS from the mode-seeking perspective and propose Inline Prior Guided Score Matching (IPSM), which leverages visual inline priors provided by pose relationships between viewpoints to rectify the rendered image distribution and decomposes the original optimization objective of SDS, thereby offering effective diffusion visual guidance without any fine-tuning or pre-training. Furthermore, we propose the IPSM-Gaussian pipeline, which adopts 3D Gaussian Splatting as the backbone and supplements depth and geometry consistency regularization based on IPSM to further improve inline priors and rectified distribution. Experimental results on different public datasets show that our method achieves state-of-the-art reconstruction quality. The code is released at https://github.com/iCVTEAM/IPSM.
WIDIn: Wording Image for Domain-Invariant Representation in Single-Source Domain Generalization
May 28, 2024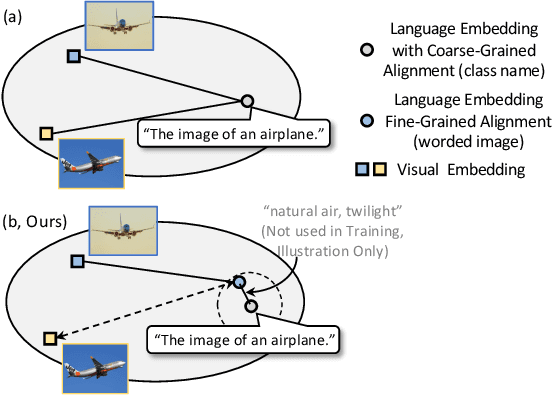
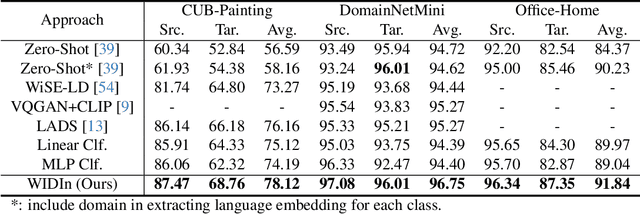
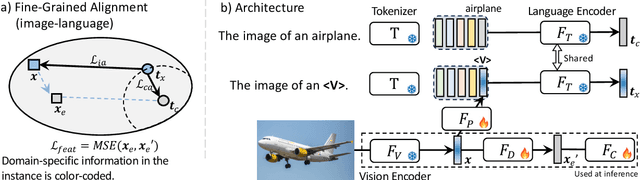
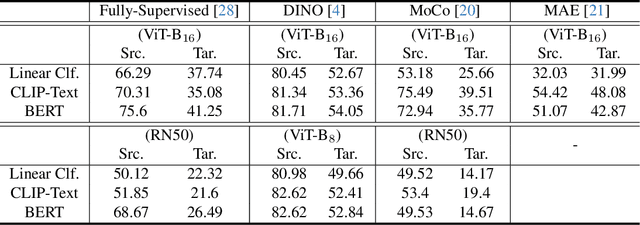
Language has been useful in extending the vision encoder to data from diverse distributions without empirical discovery in training domains. However, as the image description is mostly at coarse-grained level and ignores visual details, the resulted embeddings are still ineffective in overcoming complexity of domains at inference time. We present a self-supervision framework WIDIn, Wording Images for Domain-Invariant representation, to disentangle discriminative visual representation, by only leveraging data in a single domain and without any test prior. Specifically, for each image, we first estimate the language embedding with fine-grained alignment, which can be consequently used to adaptively identify and then remove domain-specific counterpart from the raw visual embedding. WIDIn can be applied to both pretrained vision-language models like CLIP, and separately trained uni-modal models like MoCo and BERT. Experimental studies on three domain generalization datasets demonstrate the effectiveness of our approach.
MoDE: CLIP Data Experts via Clustering
Apr 24, 2024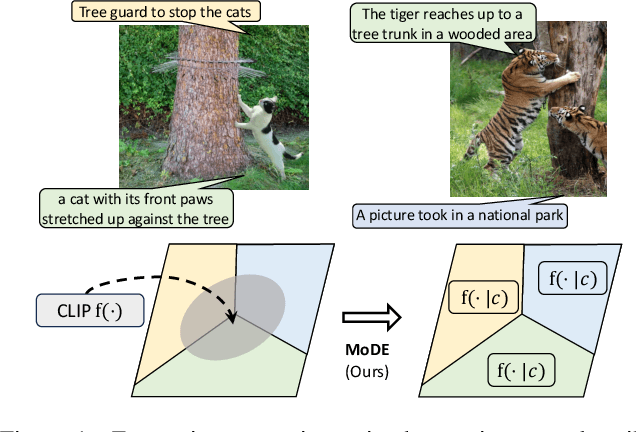
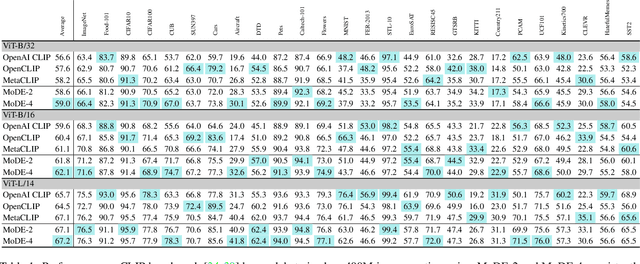

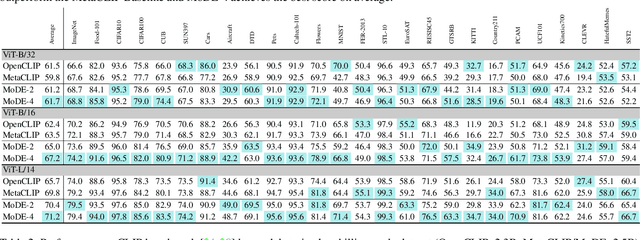
The success of contrastive language-image pretraining (CLIP) relies on the supervision from the pairing between images and captions, which tends to be noisy in web-crawled data. We present Mixture of Data Experts (MoDE) and learn a system of CLIP data experts via clustering. Each data expert is trained on one data cluster, being less sensitive to false negative noises in other clusters. At inference time, we ensemble their outputs by applying weights determined through the correlation between task metadata and cluster conditions. To estimate the correlation precisely, the samples in one cluster should be semantically similar, but the number of data experts should still be reasonable for training and inference. As such, we consider the ontology in human language and propose to use fine-grained cluster centers to represent each data expert at a coarse-grained level. Experimental studies show that four CLIP data experts on ViT-B/16 outperform the ViT-L/14 by OpenAI CLIP and OpenCLIP on zero-shot image classification but with less ($<$35\%) training cost. Meanwhile, MoDE can train all data expert asynchronously and can flexibly include new data experts. The code is available at https://github.com/facebookresearch/MetaCLIP/tree/main/mode.
Supervised Masked Knowledge Distillation for Few-Shot Transformers
Mar 29, 2023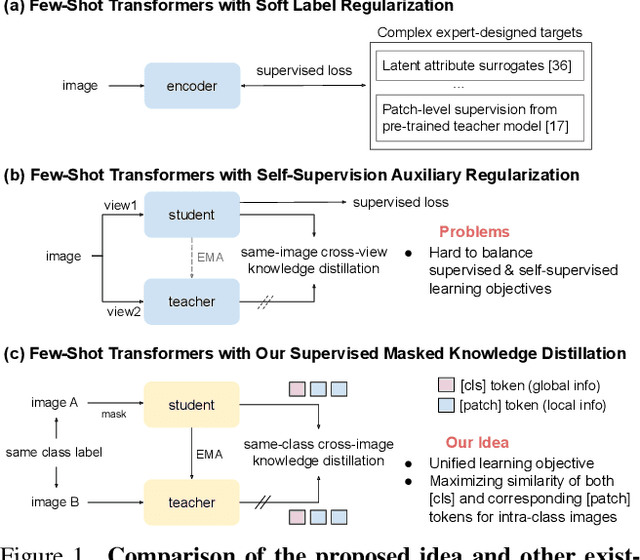
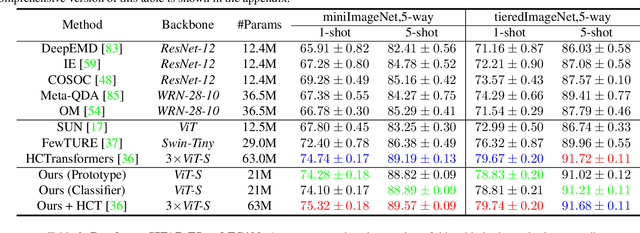
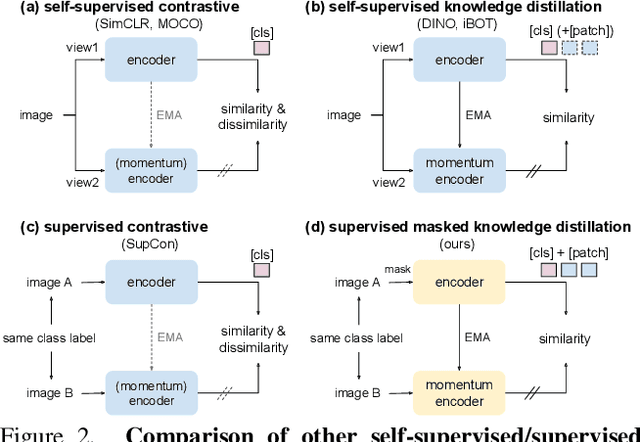
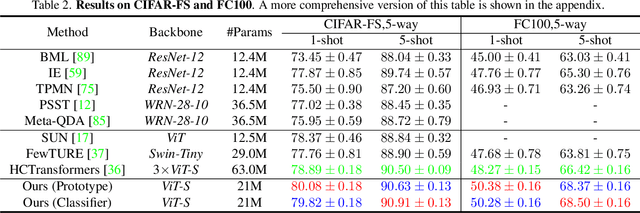
Vision Transformers (ViTs) emerge to achieve impressive performance on many data-abundant computer vision tasks by capturing long-range dependencies among local features. However, under few-shot learning (FSL) settings on small datasets with only a few labeled data, ViT tends to overfit and suffers from severe performance degradation due to its absence of CNN-alike inductive bias. Previous works in FSL avoid such problem either through the help of self-supervised auxiliary losses, or through the dextile uses of label information under supervised settings. But the gap between self-supervised and supervised few-shot Transformers is still unfilled. Inspired by recent advances in self-supervised knowledge distillation and masked image modeling (MIM), we propose a novel Supervised Masked Knowledge Distillation model (SMKD) for few-shot Transformers which incorporates label information into self-distillation frameworks. Compared with previous self-supervised methods, we allow intra-class knowledge distillation on both class and patch tokens, and introduce the challenging task of masked patch tokens reconstruction across intra-class images. Experimental results on four few-shot classification benchmark datasets show that our method with simple design outperforms previous methods by a large margin and achieves a new start-of-the-art. Detailed ablation studies confirm the effectiveness of each component of our model. Code for this paper is available here: https://github.com/HL-hanlin/SMKD.
DiGeo: Discriminative Geometry-Aware Learning for Generalized Few-Shot Object Detection
Mar 16, 2023



Generalized few-shot object detection aims to achieve precise detection on both base classes with abundant annotations and novel classes with limited training data. Existing approaches enhance few-shot generalization with the sacrifice of base-class performance, or maintain high precision in base-class detection with limited improvement in novel-class adaptation. In this paper, we point out the reason is insufficient Discriminative feature learning for all of the classes. As such, we propose a new training framework, DiGeo, to learn Geometry-aware features of inter-class separation and intra-class compactness. To guide the separation of feature clusters, we derive an offline simplex equiangular tight frame (ETF) classifier whose weights serve as class centers and are maximally and equally separated. To tighten the cluster for each class, we include adaptive class-specific margins into the classification loss and encourage the features close to the class centers. Experimental studies on two few-shot benchmark datasets (VOC, COCO) and one long-tail dataset (LVIS) demonstrate that, with a single model, our method can effectively improve generalization on novel classes without hurting the detection of base classes.
TempCLR: Temporal Alignment Representation with Contrastive Learning
Dec 28, 2022Video representation learning has been successful in video-text pre-training for zero-shot transfer, where each sentence is trained to be close to the paired video clips in a common feature space. For long videos, given a paragraph of description where the sentences describe different segments of the video, by matching all sentence-clip pairs, the paragraph and the full video are aligned implicitly. However, such unit-level similarity measure may ignore the global temporal context over a long time span, which inevitably limits the generalization ability. In this paper, we propose a contrastive learning framework TempCLR to compare the full video and the paragraph explicitly. As the video/paragraph is formulated as a sequence of clips/sentences, under the constraint of their temporal order, we use dynamic time warping to compute the minimum cumulative cost over sentence-clip pairs as the sequence-level distance. To explore the temporal dynamics, we break the consistency of temporal order by shuffling the video clips or sentences according to the temporal granularity. In this way, we obtain the representations for clips/sentences, which perceive the temporal information and thus facilitate the sequence alignment. In addition to pre-training on the video and paragraph, our approach can also generalize on the matching between different video instances. We evaluate our approach on video retrieval, action step localization, and few-shot action recognition, and achieve consistent performance gain over all three tasks. Detailed ablation studies are provided to justify the approach design.
Multimodal Few-Shot Object Detection with Meta-Learning Based Cross-Modal Prompting
Apr 16, 2022
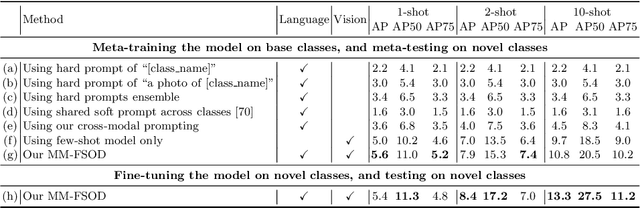
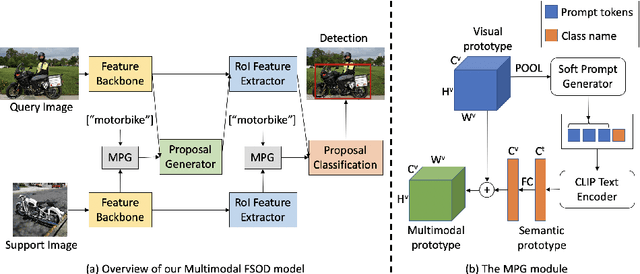
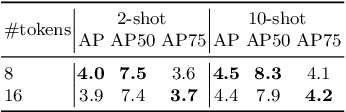
We study multimodal few-shot object detection (FSOD) in this paper, using both few-shot visual examples and class semantic information for detection. Most of previous works focus on either few-shot or zero-shot object detection, ignoring the complementarity of visual and semantic information. We first show that meta-learning and prompt-based learning, the most commonly-used methods for few-shot learning and zero-shot transferring from pre-trained vision-language models to downstream tasks, are conceptually similar. They both reformulate the objective of downstream tasks the same as the pre-training tasks, and mostly without tuning the parameters of pre-trained models. Based on this observation, we propose to combine meta-learning with prompt-based learning for multimodal FSOD without fine-tuning, by learning transferable class-agnostic multimodal FSOD models over many-shot base classes. Specifically, to better exploit the pre-trained vision-language models, the meta-learning based cross-modal prompting is proposed to generate soft prompts and further used to extract the semantic prototype, conditioned on the few-shot visual examples. Then, the extracted semantic prototype and few-shot visual prototype are fused to generate the multimodal prototype for detection. Our models can efficiently fuse the visual and semantic information at both token-level and feature-level. We comprehensively evaluate the proposed multimodal FSOD models on multiple few-shot object detection benchmarks, achieving promising results.