 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCSC at SemEval-2025 Task 3: Context, Models and Prompt Optimization for Automated Hallucination Detection in LLM Output
May 05, 2025Hallucinations pose a significant challenge for large language models when answering knowledge-intensive queries. As LLMs become more widely adopted, it is crucial not only to detect if hallucinations occur but also to pinpoint exactly where in the LLM output they occur. SemEval 2025 Task 3, Mu-SHROOM: Multilingual Shared-task on Hallucinations and Related Observable Overgeneration Mistakes, is a recent effort in this direction. This paper describes the UCSC system submission to the shared Mu-SHROOM task. We introduce a framework that first retrieves relevant context, next identifies false content from the answer, and finally maps them back to spans in the LLM output. The process is further enhanced by automatically optimizing prompts. Our system achieves the highest overall performance, ranking #1 in average position across all languages. We release our code and experiment results.
WIDIn: Wording Image for Domain-Invariant Representation in Single-Source Domain Generalization
May 28, 2024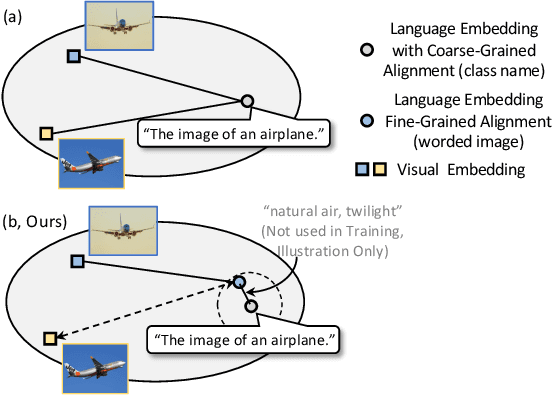
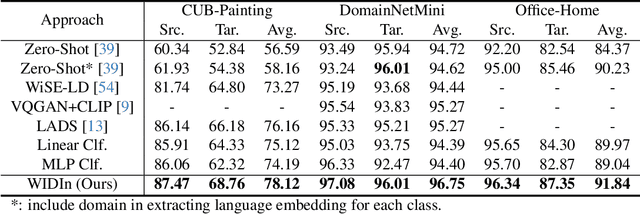
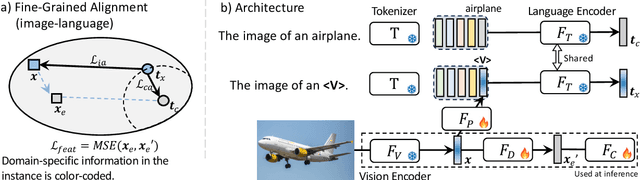
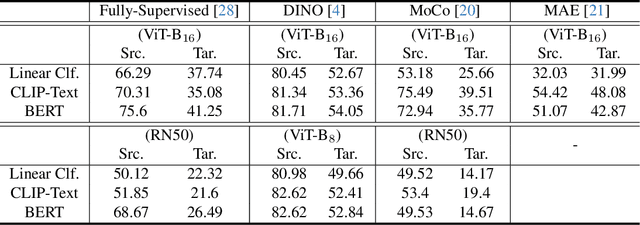
Language has been useful in extending the vision encoder to data from diverse distributions without empirical discovery in training domains. However, as the image description is mostly at coarse-grained level and ignores visual details, the resulted embeddings are still ineffective in overcoming complexity of domains at inference time. We present a self-supervision framework WIDIn, Wording Images for Domain-Invariant representation, to disentangle discriminative visual representation, by only leveraging data in a single domain and without any test prior. Specifically, for each image, we first estimate the language embedding with fine-grained alignment, which can be consequently used to adaptively identify and then remove domain-specific counterpart from the raw visual embedding. WIDIn can be applied to both pretrained vision-language models like CLIP, and separately trained uni-modal models like MoCo and BERT. Experimental studies on three domain generalization datasets demonstrate the effectiveness of our approach.
Characterizing Video Question Answering with Sparsified Inputs
Nov 27, 2023



In Video Question Answering, videos are often processed as a full-length sequence of frames to ensure minimal loss of information. Recent works have demonstrated evidence that sparse video inputs are sufficient to maintain high performance. However, they usually discuss the case of single frame selection. In our work, we extend the setting to multiple number of inputs and other modalities. We characterize the task with different input sparsity and provide a tool for doing that. Specifically, we use a Gumbel-based learnable selection module to adaptively select the best inputs for the final task. In this way, we experiment over public VideoQA benchmarks and provide analysis on how sparsified inputs affect the performance. From our experiments, we have observed only 5.2%-5.8% loss of performance with only 10% of video lengths, which corresponds to 2-4 frames selected from each video. Meanwhile, we also observed the complimentary behaviour between visual and textual inputs, even under highly sparsified settings, suggesting the potential of improving data efficiency for video-and-language tasks.
Can Large Language Models Explain Themselves? A Study of LLM-Generated Self-Explanations
Oct 17, 2023



Large language models (LLMs) such as ChatGPT have demonstrated superior performance on a variety of natural language processing (NLP) tasks including sentiment analysis, mathematical reasoning and summarization. Furthermore, since these models are instruction-tuned on human conversations to produce "helpful" responses, they can and often will produce explanations along with the response, which we call self-explanations. For example, when analyzing the sentiment of a movie review, the model may output not only the positivity of the sentiment, but also an explanation (e.g., by listing the sentiment-laden words such as "fantastic" and "memorable" in the review). How good are these automatically generated self-explanations? In this paper, we investigate this question on the task of sentiment analysis and for feature attribution explanation, one of the most commonly studied settings in the interpretability literature (for pre-ChatGPT models). Specifically, we study different ways to elicit the self-explanations, evaluate their faithfulness on a set of evaluation metrics, and compare them to traditional explanation methods such as occlusion or LIME saliency maps. Through an extensive set of experiments, we find that ChatGPT's self-explanations perform on par with traditional ones, but are quite different from them according to various agreement metrics, meanwhile being much cheaper to produce (as they are generated along with the prediction). In addition, we identified several interesting characteristics of them, which prompt us to rethink many current model interpretability practices in the era of ChatGPT(-like) LLMs.
Supervised Masked Knowledge Distillation for Few-Shot Transformers
Mar 29, 2023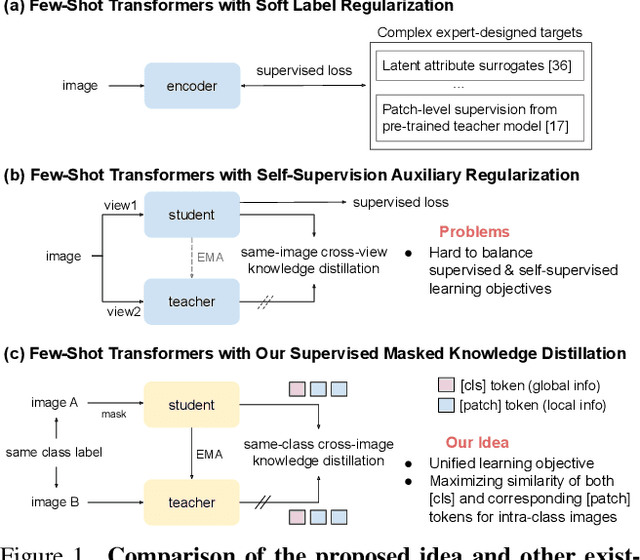
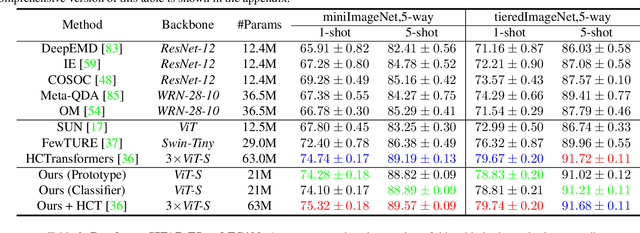
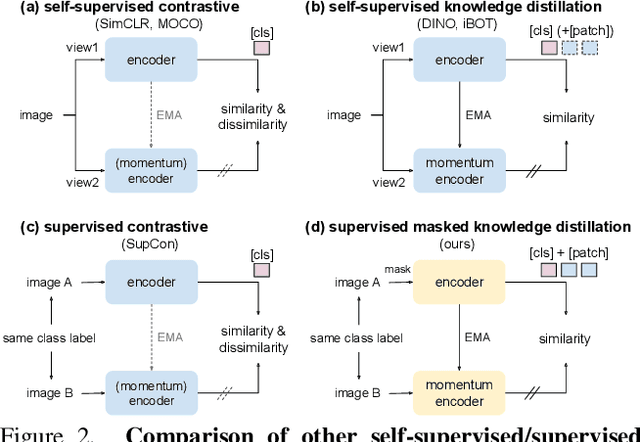
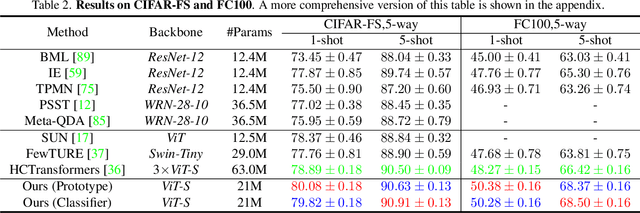
Vision Transformers (ViTs) emerge to achieve impressive performance on many data-abundant computer vision tasks by capturing long-range dependencies among local features. However, under few-shot learning (FSL) settings on small datasets with only a few labeled data, ViT tends to overfit and suffers from severe performance degradation due to its absence of CNN-alike inductive bias. Previous works in FSL avoid such problem either through the help of self-supervised auxiliary losses, or through the dextile uses of label information under supervised settings. But the gap between self-supervised and supervised few-shot Transformers is still unfilled. Inspired by recent advances in self-supervised knowledge distillation and masked image modeling (MIM), we propose a novel Supervised Masked Knowledge Distillation model (SMKD) for few-shot Transformers which incorporates label information into self-distillation frameworks. Compared with previous self-supervised methods, we allow intra-class knowledge distillation on both class and patch tokens, and introduce the challenging task of masked patch tokens reconstruction across intra-class images. Experimental results on four few-shot classification benchmark datasets show that our method with simple design outperforms previous methods by a large margin and achieves a new start-of-the-art. Detailed ablation studies confirm the effectiveness of each component of our model. Code for this paper is available here: https://github.com/HL-hanlin/SMKD.
DiGeo: Discriminative Geometry-Aware Learning for Generalized Few-Shot Object Detection
Mar 16, 2023



Generalized few-shot object detection aims to achieve precise detection on both base classes with abundant annotations and novel classes with limited training data. Existing approaches enhance few-shot generalization with the sacrifice of base-class performance, or maintain high precision in base-class detection with limited improvement in novel-class adaptation. In this paper, we point out the reason is insufficient Discriminative feature learning for all of the classes. As such, we propose a new training framework, DiGeo, to learn Geometry-aware features of inter-class separation and intra-class compactness. To guide the separation of feature clusters, we derive an offline simplex equiangular tight frame (ETF) classifier whose weights serve as class centers and are maximally and equally separated. To tighten the cluster for each class, we include adaptive class-specific margins into the classification loss and encourage the features close to the class centers. Experimental studies on two few-shot benchmark datasets (VOC, COCO) and one long-tail dataset (LVIS) demonstrate that, with a single model, our method can effectively improve generalization on novel classes without hurting the detection of base classes.
TempCLR: Temporal Alignment Representation with Contrastive Learning
Dec 28, 2022Video representation learning has been successful in video-text pre-training for zero-shot transfer, where each sentence is trained to be close to the paired video clips in a common feature space. For long videos, given a paragraph of description where the sentences describe different segments of the video, by matching all sentence-clip pairs, the paragraph and the full video are aligned implicitly. However, such unit-level similarity measure may ignore the global temporal context over a long time span, which inevitably limits the generalization ability. In this paper, we propose a contrastive learning framework TempCLR to compare the full video and the paragraph explicitly. As the video/paragraph is formulated as a sequence of clips/sentences, under the constraint of their temporal order, we use dynamic time warping to compute the minimum cumulative cost over sentence-clip pairs as the sequence-level distance. To explore the temporal dynamics, we break the consistency of temporal order by shuffling the video clips or sentences according to the temporal granularity. In this way, we obtain the representations for clips/sentences, which perceive the temporal information and thus facilitate the sequence alignment. In addition to pre-training on the video and paragraph, our approach can also generalize on the matching between different video instances. We evaluate our approach on video retrieval, action step localization, and few-shot action recognition, and achieve consistent performance gain over all three tasks. Detailed ablation studies are provided to justify the approach design.
Video in 10 Bits: Few-Bit VideoQA for Efficiency and Privacy
Oct 18, 2022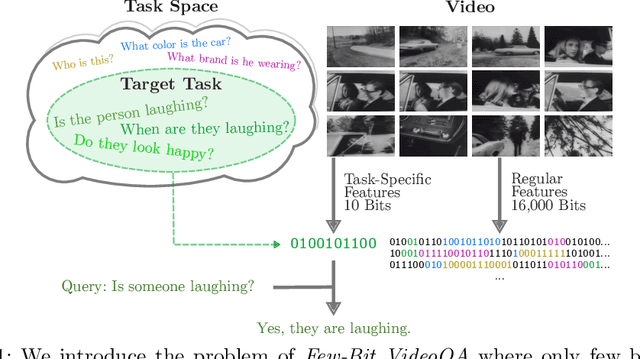

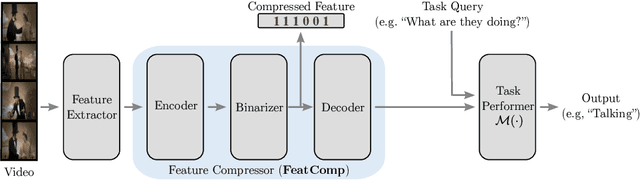
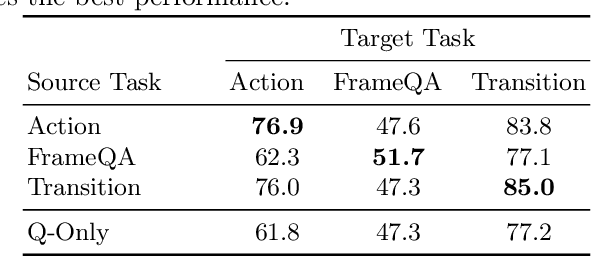
In Video Question Answering (VideoQA), answering general questions about a video requires its visual information. Yet, video often contains redundant information irrelevant to the VideoQA task. For example, if the task is only to answer questions similar to "Is someone laughing in the video?", then all other information can be discarded. This paper investigates how many bits are really needed from the video in order to do VideoQA by introducing a novel Few-Bit VideoQA problem, where the goal is to accomplish VideoQA with few bits of video information (e.g., 10 bits). We propose a simple yet effective task-specific feature compression approach to solve this problem. Specifically, we insert a lightweight Feature Compression Module (FeatComp) into a VideoQA model which learns to extract task-specific tiny features as little as 10 bits, which are optimal for answering certain types of questions. We demonstrate more than 100,000-fold storage efficiency over MPEG4-encoded videos and 1,000-fold over regular floating point features, with just 2.0-6.6% absolute loss in accuracy, which is a surprising and novel finding. Finally, we analyze what the learned tiny features capture and demonstrate that they have eliminated most of the non-task-specific information, and introduce a Bit Activation Map to visualize what information is being stored. This decreases the privacy risk of data by providing k-anonymity and robustness to feature-inversion techniques, which can influence the machine learning community, allowing us to store data with privacy guarantees while still performing the task effectively.
Towards Fast Adaptation of Pretrained Contrastive Models for Multi-channel Video-Language Retrieval
Jun 05, 2022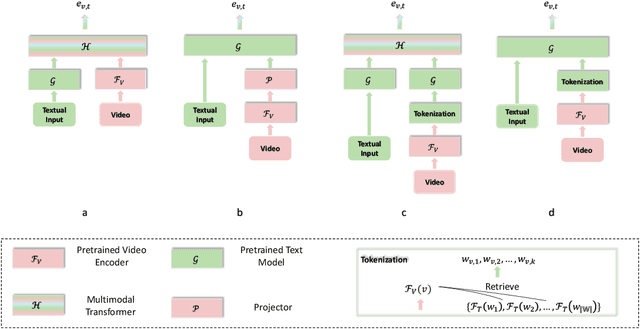

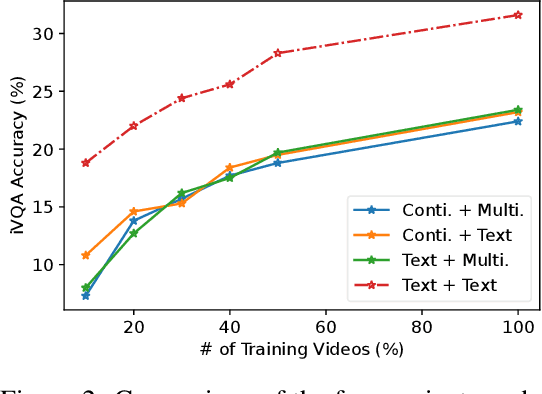
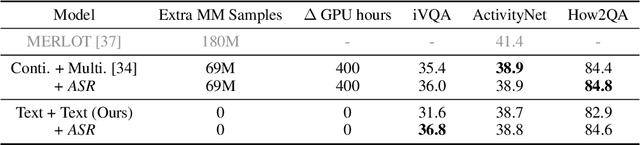
Multi-channel video-language retrieval require models to understand information from different modalities (e.g. video+question, video+speech) and real-world knowledge to correctly link a video with a textual response or query. Fortunately, multimodal contrastive models have been shown to be highly effective at aligning entities in images/videos and text, e.g., CLIP; text contrastive models have been extensively studied recently for their strong ability of producing discriminative sentence embeddings, e.g., SimCSE. Their abilities are exactly needed by multi-channel video-language retrieval. However, it is not clear how to quickly adapt these two lines of models to multi-channel video-language retrieval-style tasks. In this paper, we identify a principled model design space with two axes: how to represent videos and how to fuse video and text information. Based on categorization of recent methods, we investigate the options of representing videos using continuous feature vectors or discrete text tokens; for the fusion method, we explore a multimodal transformer or a pretrained contrastive text model. We extensively evaluate the four combinations on five video-language datasets. We surprisingly find that discrete text tokens coupled with a pretrained contrastive text model yields the best performance. This combination can even outperform state-of-the-art on the iVQA dataset without the additional training on millions of video-language data. Further analysis shows that this is because representing videos as text tokens captures the key visual information with text tokens that are naturally aligned with text models and the text models obtained rich knowledge during contrastive pretraining process. All the empirical analysis we obtain for the four variants establishes a solid foundation for future research on leveraging the rich knowledge of pretrained contrastive models.
Multimodal Few-Shot Object Detection with Meta-Learning Based Cross-Modal Prompting
Apr 16, 2022
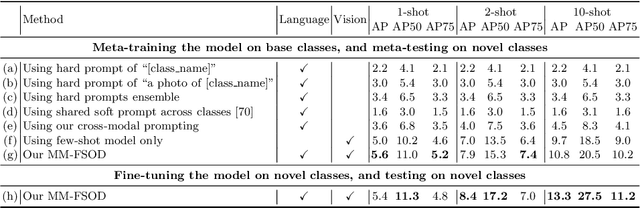
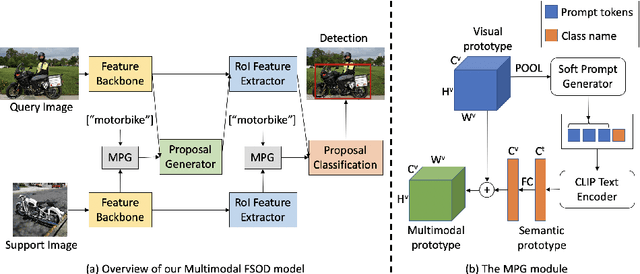
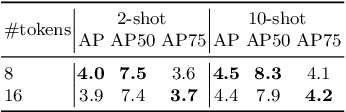
We study multimodal few-shot object detection (FSOD) in this paper, using both few-shot visual examples and class semantic information for detection. Most of previous works focus on either few-shot or zero-shot object detection, ignoring the complementarity of visual and semantic information. We first show that meta-learning and prompt-based learning, the most commonly-used methods for few-shot learning and zero-shot transferring from pre-trained vision-language models to downstream tasks, are conceptually similar. They both reformulate the objective of downstream tasks the same as the pre-training tasks, and mostly without tuning the parameters of pre-trained models. Based on this observation, we propose to combine meta-learning with prompt-based learning for multimodal FSOD without fine-tuning, by learning transferable class-agnostic multimodal FSOD models over many-shot base classes. Specifically, to better exploit the pre-trained vision-language models, the meta-learning based cross-modal prompting is proposed to generate soft prompts and further used to extract the semantic prototype, conditioned on the few-shot visual examples. Then, the extracted semantic prototype and few-shot visual prototype are fused to generate the multimodal prototype for detection. Our models can efficiently fuse the visual and semantic information at both token-level and feature-level. We comprehensively evaluate the proposed multimodal FSOD models on multiple few-shot object detection benchmarks, achieving promising results.