 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTA: Generating Long-Horizon Tasks for Web Agents at Scale
May 28, 2026Web agents, which couple language models with browsing and tool-use capabilities, show promise as open web assistants. Yet progress is increasingly limited by the lack of scalable, process-level supervision. Existing benchmarks are largely manually constructed, providing only coarse start-goal annotations without intermediate trajectories, while recent automatic generation efforts remain expensive, biased, and shallow. These limitations prevent reliable training and evaluation of agents that must generalize to realistic, multi-hop, cross-page tasks. We introduce a scalable framework, GTA, that integrates crawling, retrieval-based seeding, in-context generation, and automated quality control to produce realistic tasks paired with executable trajectories. This design decouples crawling from generation for greater efficiency, grounds tasks in the site graph to enforce compositionality, and ensures dense supervision through deterministic replays and systematic validation. We instantiate the pipeline on over 50 websites covering e-commerce, government, forums, and news, with multilingual and multi-hop coverage. The resulting benchmark reveals a significant human-agent performance gap and enables detailed diagnostics. Our contributions are three-fold: (i) formalizing multi-hop web-agent task generation, (ii) proposing an efficient and validated pipeline for automatic data creation, and (iii) releasing a dynamic benchmark with reproducible evaluation.
The Hidden Signal of Verifier Strictness: Controlling and Improving Step-Wise Verification via Selective Latent Steering
May 20, 2026Generative verifiers have emerged as a promising paradigm for step-wise verification, but their verification behavior is often poorly calibrated: they may be under-critical and miss erroneous steps, or over-critical and reject correct reasoning. We refer to this tendency to be overly lenient or overly critical as verifier strictness. In this work, we study whether verifier strictness can be controlled through hidden-state intervention. We uncover a verification-specific hidden-state signal: in step-wise verification, a verifier's tendency to accept or reject a solution step is encoded near the boundary of the corresponding verification paragraph. Exploiting this signal, we show that hidden-state steering can directly modulate verifier strictness without fine-tuning. However, uniform steering induces a trade-off between error detection and correctness certification. To address this, we propose VerifySteer, which exploits latent correctness signals for sample-level routing and selectively intervenes on paragraph boundaries. Experiments on ProcessBench and Hard2Verify show that VerifySteer outperforms prompt optimization and activation steering baselines, and is competitive with self-consistency while requiring 4-7x less inference compute. VerifySteer is also complementary to verification fine-tuning, providing further gains on top of fine-tuned verifiers. The code is available at https://github.com/YefanZhou/VerifySteer.
VIBEPASS: Can Vibe Coders Really Pass the Vibe Check?
Mar 16, 2026As Large Language Models shift the programming toward human-guided ''vibe coding'', agentic coding tools increasingly rely on models to self-diagnose and repair their own subtle faults -- a capability central to autonomous software engineering yet never systematically evaluated. We present \name{}, the first empirical decomposition that jointly evaluates two coupled tasks: \emph{Fault-Triggering Test Generation (FT-Test)} constructing a discriminative witness that exposes a latent bug, and \emph{Fault-targeted Program Repair (FPR)}, repairing it under varying diagnostic conditions. \name{} pairs competitive programming problems with LLM-generated solutions that pass partial test suites but fail on semantic edge cases, enabling controlled identification of where the diagnostic chain breaks down. Evaluating 12 frontier LLMs, we find that fault-targeted reasoning does not scale with general coding ability. Models produce syntactically valid test inputs at near-ceiling rates yet collapse on discriminative generation, with fault hypothesis generation -- not output validation -- as the dominant bottleneck. Test-guided repair reveals a complementary insight: when self-generated tests successfully witness a fault, the resulting repair matches or outperforms repair guided by externally provided tests, but tests that fail to witness the fault actively degrade repair below unguided baselines. Together, these results reframe the challenge of autonomous debugging: the binding bottleneck is not code synthesis or test validity but fault-target reasoning, a capability that remains deficient across all frontier models. As Large Language Models shift the programming toward human-guided ''vibe coding'', agentic coding tools increasingly rely on models to self-diagnose and repair their own subtle faults -- a capability central to autonomous software engineering yet never systematically evaluated.
MMPersuade: A Dataset and Evaluation Framework for Multimodal Persuasion
Oct 26, 2025As Large Vision-Language Models (LVLMs) are increasingly deployed in domains such as shopping, health, and news, they are exposed to pervasive persuasive content. A critical question is how these models function as persuadees-how and why they can be influenced by persuasive multimodal inputs. Understanding both their susceptibility to persuasion and the effectiveness of different persuasive strategies is crucial, as overly persuadable models may adopt misleading beliefs, override user preferences, or generate unethical or unsafe outputs when exposed to manipulative messages. We introduce MMPersuade, a unified framework for systematically studying multimodal persuasion dynamics in LVLMs. MMPersuade contributes (i) a comprehensive multimodal dataset that pairs images and videos with established persuasion principles across commercial, subjective and behavioral, and adversarial contexts, and (ii) an evaluation framework that quantifies both persuasion effectiveness and model susceptibility via third-party agreement scoring and self-estimated token probabilities on conversation histories. Our study of six leading LVLMs as persuadees yields three key insights: (i) multimodal inputs substantially increase persuasion effectiveness-and model susceptibility-compared to text alone, especially in misinformation scenarios; (ii) stated prior preferences decrease susceptibility, yet multimodal information maintains its persuasive advantage; and (iii) different strategies vary in effectiveness across contexts, with reciprocity being most potent in commercial and subjective contexts, and credibility and logic prevailing in adversarial contexts. By jointly analyzing persuasion effectiveness and susceptibility, MMPersuade provides a principled foundation for developing models that are robust, preference-consistent, and ethically aligned when engaging with persuasive multimodal content.
All for One: LLMs Solve Mental Math at the Last Token With Information Transferred From Other Tokens
Sep 11, 2025Large language models (LLMs) demonstrate proficiency across numerous computational tasks, yet their inner workings remain unclear. In theory, the combination of causal self-attention and multilayer perceptron layers allows every token to access and compute information based on all preceding tokens. In practice, to what extent are such operations present? In this paper, on mental math tasks (i.e., direct math calculation via next-token prediction without explicit reasoning), we investigate this question in three steps: inhibiting input-specific token computations in the initial layers, restricting the routes of information transfer across token positions in the next few layers, and forcing all computation to happen at the last token in the remaining layers. With two proposed techniques, Context-Aware Mean Ablation (CAMA) and Attention-Based Peeking (ABP), we identify an All-for-One subgraph (AF1) with high accuracy on a wide variety of mental math tasks, where meaningful computation occurs very late (in terms of layer depth) and only at the last token, which receives information of other tokens in few specific middle layers. Experiments on a variety of models and arithmetic expressions show that this subgraph is sufficient and necessary for high model performance, transfers across different models, and works on a variety of input styles. Ablations on different CAMA and ABP alternatives reveal their unique advantages over other methods, which may be of independent interest.
J4R: Learning to Judge with Equivalent Initial State Group Relative Preference Optimization
May 19, 2025To keep pace with the increasing pace of large language models (LLM) development, model output evaluation has transitioned away from time-consuming human evaluation to automatic evaluation, where LLMs themselves are tasked with assessing and critiquing other model outputs. LLM-as-judge models are a class of generative evaluators that excel in evaluating relatively simple domains, like chat quality, but struggle in reasoning intensive domains where model responses contain more substantive and challenging content. To remedy existing judge shortcomings, we explore training judges with reinforcement learning (RL). We make three key contributions: (1) We propose the Equivalent Initial State Group Relative Policy Optimization (EIS-GRPO) algorithm, which allows us to train our judge to be robust to positional biases that arise in more complex evaluation settings. (2) We introduce ReasoningJudgeBench, a benchmark that evaluates judges in diverse reasoning settings not covered by prior work. (3) We train Judge for Reasoning (J4R), a 7B judge trained with EIS-GRPO that outperforms GPT-4o and the next best small judge by 6.7% and 9%, matching or exceeding the performance of larger GRPO-trained judges on both JudgeBench and ReasoningJudgeBench.
Evaluating Judges as Evaluators: The JETTS Benchmark of LLM-as-Judges as Test-Time Scaling Evaluators
Apr 21, 2025Scaling test-time computation, or affording a generator large language model (LLM) extra compute during inference, typically employs the help of external non-generative evaluators (i.e., reward models). Concurrently, LLM-judges, models trained to generate evaluations and critiques (explanations) in natural language, are becoming increasingly popular in automatic evaluation. Despite judge empirical successes, their effectiveness as evaluators in test-time scaling settings is largely unknown. In this paper, we introduce the Judge Evaluation for Test-Time Scaling (JETTS) benchmark, which evaluates judge performance in three domains (math reasoning, code generation, and instruction following) under three task settings: response reranking, step-level beam search, and critique-based response refinement. We evaluate 10 different judge models (7B-70B parameters) for 8 different base generator models (6.7B-72B parameters). Our benchmark shows that while judges are competitive with outcome reward models in reranking, they are consistently worse than process reward models in beam search procedures. Furthermore, though unique to LLM-judges, their natural language critiques are currently ineffective in guiding the generator towards better responses.
BingoGuard: LLM Content Moderation Tools with Risk Levels
Mar 09, 2025Malicious content generated by large language models (LLMs) can pose varying degrees of harm. Although existing LLM-based moderators can detect harmful content, they struggle to assess risk levels and may miss lower-risk outputs. Accurate risk assessment allows platforms with different safety thresholds to tailor content filtering and rejection. In this paper, we introduce per-topic severity rubrics for 11 harmful topics and build BingoGuard, an LLM-based moderation system designed to predict both binary safety labels and severity levels. To address the lack of annotations on levels of severity, we propose a scalable generate-then-filter framework that first generates responses across different severity levels and then filters out low-quality responses. Using this framework, we create BingoGuardTrain, a training dataset with 54,897 examples covering a variety of topics, response severity, styles, and BingoGuardTest, a test set with 988 examples explicitly labeled based on our severity rubrics that enables fine-grained analysis on model behaviors on different severity levels. Our BingoGuard-8B, trained on BingoGuardTrain, achieves the state-of-the-art performance on several moderation benchmarks, including WildGuardTest and HarmBench, as well as BingoGuardTest, outperforming best public models, WildGuard, by 4.3\%. Our analysis demonstrates that incorporating severity levels into training significantly enhances detection performance and enables the model to effectively gauge the severity of harmful responses.
Direct Judgement Preference Optimization
Sep 23, 2024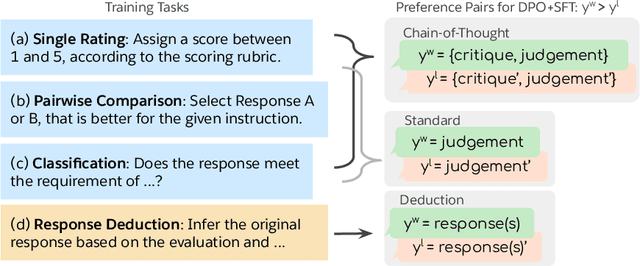

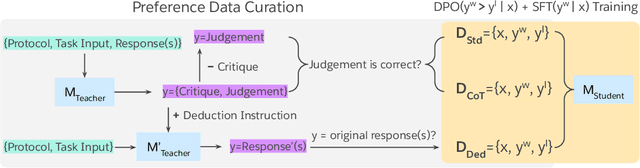

Auto-evaluation is crucial for assessing response quality and offering feedback for model development. Recent studies have explored training large language models (LLMs) as generative judges to evaluate and critique other models' outputs. In this work, we investigate the idea of learning from both positive and negative data with preference optimization to enhance the evaluation capabilities of LLM judges across an array of different use cases. We achieve this by employing three approaches to collect the preference pairs for different use cases, each aimed at improving our generative judge from a different perspective. Our comprehensive study over a wide range of benchmarks demonstrates the effectiveness of our method. In particular, our generative judge achieves the best performance on 10 out of 13 benchmarks, outperforming strong baselines like GPT-4o and specialized judge models. Further analysis show that our judge model robustly counters inherent biases such as position and length bias, flexibly adapts to any evaluation protocol specified by practitioners, and provides helpful language feedback for improving downstream generator models.
Shared Imagination: LLMs Hallucinate Alike
Jul 23, 2024



Despite the recent proliferation of large language models (LLMs), their training recipes -- model architecture, pre-training data and optimization algorithm -- are often very similar. This naturally raises the question of the similarity among the resulting models. In this paper, we propose a novel setting, imaginary question answering (IQA), to better understand model similarity. In IQA, we ask one model to generate purely imaginary questions (e.g., on completely made-up concepts in physics) and prompt another model to answer. Surprisingly, despite the total fictionality of these questions, all models can answer each other's questions with remarkable success, suggesting a "shared imagination space" in which these models operate during such hallucinations. We conduct a series of investigations into this phenomenon and discuss implications on model homogeneity, hallucination, and computational creativity.