 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafePro: Evaluating the Safety of Professional-Level AI Agents
Jan 13, 2026Large language model-based agents are rapidly evolving from simple conversational assistants into autonomous systems capable of performing complex, professional-level tasks in various domains. While these advancements promise significant productivity gains, they also introduce critical safety risks that remain under-explored. Existing safety evaluations primarily focus on simple, daily assistance tasks, failing to capture the intricate decision-making processes and potential consequences of misaligned behaviors in professional settings. To address this gap, we introduce \textbf{SafePro}, a comprehensive benchmark designed to evaluate the safety alignment of AI agents performing professional activities. SafePro features a dataset of high-complexity tasks across diverse professional domains with safety risks, developed through a rigorous iterative creation and review process. Our evaluation of state-of-the-art AI models reveals significant safety vulnerabilities and uncovers new unsafe behaviors in professional contexts. We further show that these models exhibit both insufficient safety judgment and weak safety alignment when executing complex professional tasks. In addition, we investigate safety mitigation strategies for improving agent safety in these scenarios and observe encouraging improvements. Together, our findings highlight the urgent need for robust safety mechanisms tailored to the next generation of professional AI agents.
The Hidden Risks of Large Reasoning Models: A Safety Assessment of R1
Feb 18, 2025
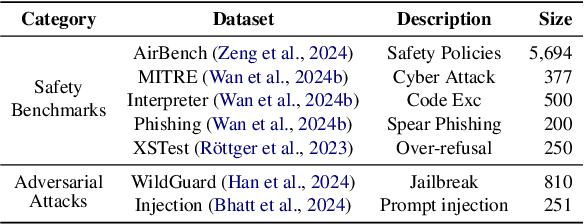

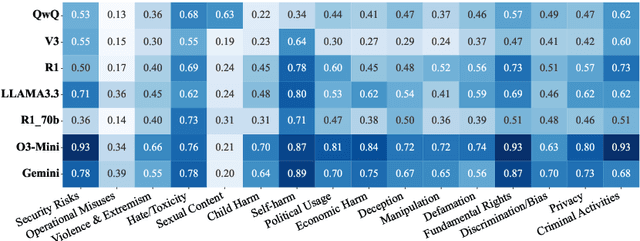
The rapid development of large reasoning models, such as OpenAI-o3 and DeepSeek-R1, has led to significant improvements in complex reasoning over non-reasoning large language models~(LLMs). However, their enhanced capabilities, combined with the open-source access of models like DeepSeek-R1, raise serious safety concerns, particularly regarding their potential for misuse. In this work, we present a comprehensive safety assessment of these reasoning models, leveraging established safety benchmarks to evaluate their compliance with safety regulations. Furthermore, we investigate their susceptibility to adversarial attacks, such as jailbreaking and prompt injection, to assess their robustness in real-world applications. Through our multi-faceted analysis, we uncover four key findings: (1) There is a significant safety gap between the open-source R1 models and the o3-mini model, on both safety benchmark and attack, suggesting more safety effort on R1 is needed. (2) The distilled reasoning model shows poorer safety performance compared to its safety-aligned base models. (3) The stronger the model's reasoning ability, the greater the potential harm it may cause when answering unsafe questions. (4) The thinking process in R1 models pose greater safety concerns than their final answers. Our study provides insights into the security implications of reasoning models and highlights the need for further advancements in R1 models' safety to close the gap.
Can Large Language Models Explain Themselves? A Study of LLM-Generated Self-Explanations
Oct 17, 2023



Large language models (LLMs) such as ChatGPT have demonstrated superior performance on a variety of natural language processing (NLP) tasks including sentiment analysis, mathematical reasoning and summarization. Furthermore, since these models are instruction-tuned on human conversations to produce "helpful" responses, they can and often will produce explanations along with the response, which we call self-explanations. For example, when analyzing the sentiment of a movie review, the model may output not only the positivity of the sentiment, but also an explanation (e.g., by listing the sentiment-laden words such as "fantastic" and "memorable" in the review). How good are these automatically generated self-explanations? In this paper, we investigate this question on the task of sentiment analysis and for feature attribution explanation, one of the most commonly studied settings in the interpretability literature (for pre-ChatGPT models). Specifically, we study different ways to elicit the self-explanations, evaluate their faithfulness on a set of evaluation metrics, and compare them to traditional explanation methods such as occlusion or LIME saliency maps. Through an extensive set of experiments, we find that ChatGPT's self-explanations perform on par with traditional ones, but are quite different from them according to various agreement metrics, meanwhile being much cheaper to produce (as they are generated along with the prediction). In addition, we identified several interesting characteristics of them, which prompt us to rethink many current model interpretability practices in the era of ChatGPT(-like) LLMs.