 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRight this way: Can VLMs Guide Us to See More to Answer Questions?
Nov 01, 2024



In question-answering scenarios, humans can assess whether the available information is sufficient and seek additional information if necessary, rather than providing a forced answer. In contrast, Vision Language Models (VLMs) typically generate direct, one-shot responses without evaluating the sufficiency of the information. To investigate this gap, we identify a critical and challenging task in the Visual Question Answering (VQA) scenario: can VLMs indicate how to adjust an image when the visual information is insufficient to answer a question? This capability is especially valuable for assisting visually impaired individuals who often need guidance to capture images correctly. To evaluate this capability of current VLMs, we introduce a human-labeled dataset as a benchmark for this task. Additionally, we present an automated framework that generates synthetic training data by simulating ``where to know'' scenarios. Our empirical results show significant performance improvements in mainstream VLMs when fine-tuned with this synthetic data. This study demonstrates the potential to narrow the gap between information assessment and acquisition in VLMs, bringing their performance closer to humans.
Towards a fuller understanding of neurons with Clustered Compositional Explanations
Oct 27, 2023
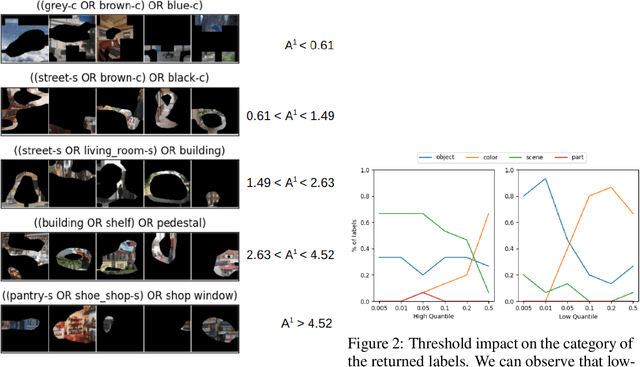

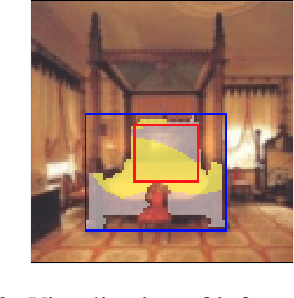
Compositional Explanations is a method for identifying logical formulas of concepts that approximate the neurons' behavior. However, these explanations are linked to the small spectrum of neuron activations (i.e., the highest ones) used to check the alignment, thus lacking completeness. In this paper, we propose a generalization, called Clustered Compositional Explanations, that combines Compositional Explanations with clustering and a novel search heuristic to approximate a broader spectrum of the neurons' behavior. We define and address the problems connected to the application of these methods to multiple ranges of activations, analyze the insights retrievable by using our algorithm, and propose desiderata qualities that can be used to study the explanations returned by different algorithms.
Can Large Language Models Explain Themselves? A Study of LLM-Generated Self-Explanations
Oct 17, 2023



Large language models (LLMs) such as ChatGPT have demonstrated superior performance on a variety of natural language processing (NLP) tasks including sentiment analysis, mathematical reasoning and summarization. Furthermore, since these models are instruction-tuned on human conversations to produce "helpful" responses, they can and often will produce explanations along with the response, which we call self-explanations. For example, when analyzing the sentiment of a movie review, the model may output not only the positivity of the sentiment, but also an explanation (e.g., by listing the sentiment-laden words such as "fantastic" and "memorable" in the review). How good are these automatically generated self-explanations? In this paper, we investigate this question on the task of sentiment analysis and for feature attribution explanation, one of the most commonly studied settings in the interpretability literature (for pre-ChatGPT models). Specifically, we study different ways to elicit the self-explanations, evaluate their faithfulness on a set of evaluation metrics, and compare them to traditional explanation methods such as occlusion or LIME saliency maps. Through an extensive set of experiments, we find that ChatGPT's self-explanations perform on par with traditional ones, but are quite different from them according to various agreement metrics, meanwhile being much cheaper to produce (as they are generated along with the prediction). In addition, we identified several interesting characteristics of them, which prompt us to rethink many current model interpretability practices in the era of ChatGPT(-like) LLMs.
Convolutional Neural Network Model for Diabetic Retinopathy Feature Extraction and Classification
Oct 16, 2023



The application of Artificial Intelligence in the medical market brings up increasing concerns but aids in more timely diagnosis of silent progressing diseases like Diabetic Retinopathy. In order to diagnose Diabetic Retinopathy (DR), ophthalmologists use color fundus images, or pictures of the back of the retina, to identify small distinct features through a difficult and time-consuming process. Our work creates a novel CNN model and identifies the severity of DR through fundus image input. We classified 4 known DR features, including micro-aneurysms, cotton wools, exudates, and hemorrhages, through convolutional layers and were able to provide an accurate diagnostic without additional user input. The proposed model is more interpretable and robust to overfitting. We present initial results with a sensitivity of 97% and an accuracy of 71%. Our contribution is an interpretable model with similar accuracy to more complex models. With that, our model advances the field of DR detection and proves to be a key step towards AI-focused medical diagnosis.
Anticipatory Thinking Challenges in Open Worlds: Risk Management
Jun 22, 2023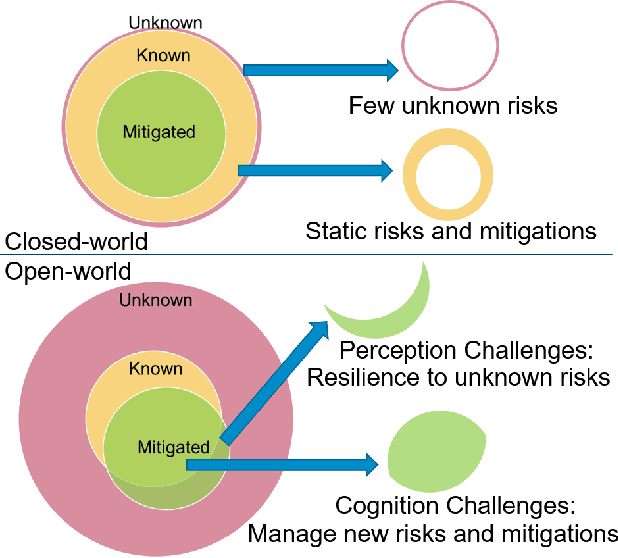
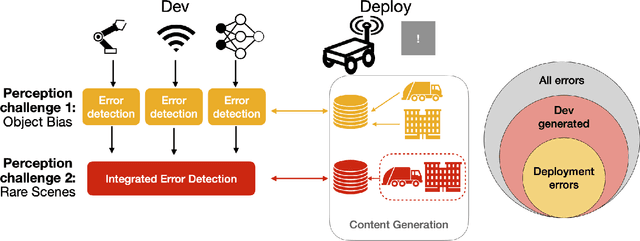
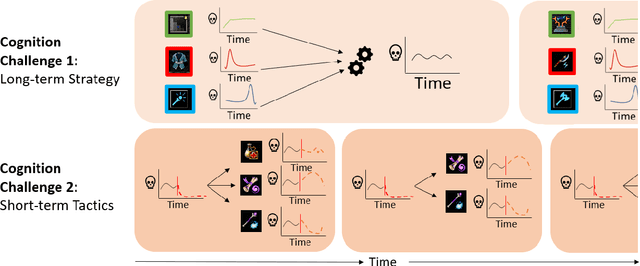
Anticipatory thinking drives our ability to manage risk - identification and mitigation - in everyday life, from bringing an umbrella when it might rain to buying car insurance. As AI systems become part of everyday life, they too have begun to manage risk. Autonomous vehicles log millions of miles, StarCraft and Go agents have similar capabilities to humans, implicitly managing risks presented by their opponents. To further increase performance in these tasks, out-of-distribution evaluation can characterize a model's bias, what we view as a type of risk management. However, learning to identify and mitigate low-frequency, high-impact risks is at odds with the observational bias required to train machine learning models. StarCraft and Go are closed-world domains whose risks are known and mitigations well documented, ideal for learning through repetition. Adversarial filtering datasets provide difficult examples but are laborious to curate and static, both barriers to real-world risk management. Adversarial robustness focuses on model poisoning under the assumption there is an adversary with malicious intent, without considering naturally occurring adversarial examples. These methods are all important steps towards improving risk management but do so without considering open-worlds. We unify these open-world risk management challenges with two contributions. The first is our perception challenges, designed for agents with imperfect perceptions of their environment whose consequences have a high impact. Our second contribution are cognition challenges, designed for agents that must dynamically adjust their risk exposure as they identify new risks and learn new mitigations. Our goal with these challenges is to spur research into solutions that assess and improve the anticipatory thinking required by AI agents to manage risk in open-worlds and ultimately the real-world.
"Explanation" is Not a Technical Term: The Problem of Ambiguity in XAI
Jun 27, 2022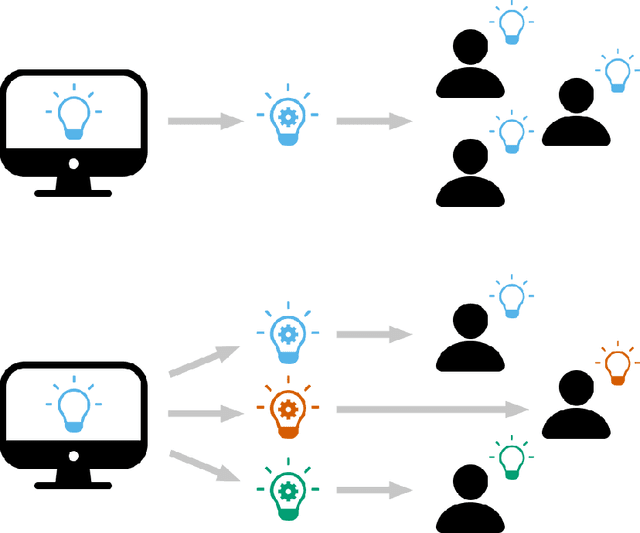
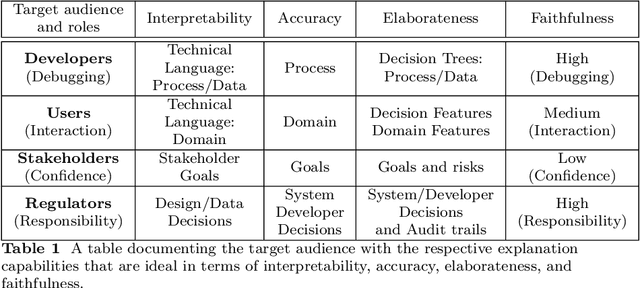
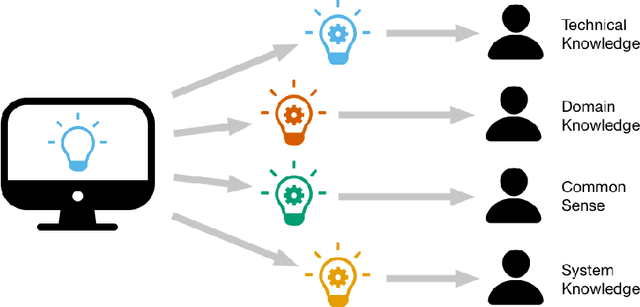

There is broad agreement that Artificial Intelligence (AI) systems, particularly those using Machine Learning (ML), should be able to "explain" their behavior. Unfortunately, there is little agreement as to what constitutes an "explanation." This has caused a disconnect between the explanations that systems produce in service of explainable Artificial Intelligence (XAI) and those explanations that users and other audiences actually need, which should be defined by the full spectrum of functional roles, audiences, and capabilities for explanation. In this paper, we explore the features of explanations and how to use those features in evaluating their utility. We focus on the requirements for explanations defined by their functional role, the knowledge states of users who are trying to understand them, and the availability of the information needed to generate them. Further, we discuss the risk of XAI enabling trust in systems without establishing their trustworthiness and define a critical next step for the field of XAI to establish metrics to guide and ground the utility of system-generated explanations.
Explaining Explanations to Society
Jan 19, 2019
There is a disconnect between explanatory artificial intelligence (XAI) methods and the types of explanations that are useful for and demanded by society (policy makers, government officials, etc.) Questions that experts in artificial intelligence (AI) ask opaque systems provide inside explanations, focused on debugging, reliability, and validation. These are different from those that society will ask of these systems to build trust and confidence in their decisions. Although explanatory AI systems can answer many questions that experts desire, they often don't explain why they made decisions in a way that is precise (true to the model) and understandable to humans. These outside explanations can be used to build trust, comply with regulatory and policy changes, and act as external validation. In this paper, we focus on XAI methods for deep neural networks (DNNs) because of DNNs' use in decision-making and inherent opacity. We explore the types of questions that explanatory DNN systems can answer and discuss challenges in building explanatory systems that provide outside explanations for societal requirements and benefit.
Explaining Explanations: An Approach to Evaluating Interpretability of Machine Learning
Jun 04, 2018

There has recently been a surge of work in explanatory artificial intelligence (XAI). This research area tackles the important problem that complex machines and algorithms often cannot provide insights into their behavior and thought processes. XAI allows users and parts of the internal system to be more transparent, providing explanations of their decisions in some level of detail. These explanations are important to ensure algorithmic fairness, identify potential bias/problems in the training data, and to ensure that the algorithms perform as expected. However, explanations produced by these systems is neither standardized nor systematically assessed. In an effort to create best practices and identify open challenges, we provide our definition of explainability and show how it can be used to classify existing literature. We discuss why current approaches to explanatory methods especially for deep neural networks are insufficient. Finally, based on our survey, we conclude with suggested future research directions for explanatory artificial intelligence.