 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding LTL Tasks in Sub-Symbolic RL Environments for Zero-Shot Generalization
Feb 10, 2026In this work we address the problem of training a Reinforcement Learning agent to follow multiple temporally-extended instructions expressed in Linear Temporal Logic in sub-symbolic environments. Previous multi-task work has mostly relied on knowledge of the mapping between raw observations and symbols appearing in the formulae. We drop this unrealistic assumption by jointly training a multi-task policy and a symbol grounder with the same experience. The symbol grounder is trained only from raw observations and sparse rewards via Neural Reward Machines in a semi-supervised fashion. Experiments on vision-based environments show that our method achieves performance comparable to using the true symbol grounding and significantly outperforms state-of-the-art methods for sub-symbolic environments.
DeepDFA: Injecting Temporal Logic in Deep Learning for Sequential Subsymbolic Applications
Feb 03, 2026Integrating logical knowledge into deep neural network training is still a hard challenge, especially for sequential or temporally extended domains involving subsymbolic observations. To address this problem, we propose DeepDFA, a neurosymbolic framework that integrates high-level temporal logic - expressed as Deterministic Finite Automata (DFA) or Moore Machines - into neural architectures. DeepDFA models temporal rules as continuous, differentiable layers, enabling symbolic knowledge injection into subsymbolic domains. We demonstrate how DeepDFA can be used in two key settings: (i) static image sequence classification, and (ii) policy learning in interactive non-Markovian environments. Across extensive experiments, DeepDFA outperforms traditional deep learning models (e.g., LSTMs, GRUs, Transformers) and novel neuro-symbolic systems, achieving state-of-the-art results in temporal knowledge integration. These results highlight the potential of DeepDFA to bridge subsymbolic learning and symbolic reasoning in sequential tasks.
CIP-Net: Continual Interpretable Prototype-based Network
Dec 08, 2025Continual learning constrains models to learn new tasks over time without forgetting what they have already learned. A key challenge in this setting is catastrophic forgetting, where learning new information causes the model to lose its performance on previous tasks. Recently, explainable AI has been proposed as a promising way to better understand and reduce forgetting. In particular, self-explainable models are useful because they generate explanations during prediction, which can help preserve knowledge. However, most existing explainable approaches use post-hoc explanations or require additional memory for each new task, resulting in limited scalability. In this work, we introduce CIP-Net, an exemplar-free self-explainable prototype-based model designed for continual learning. CIP-Net avoids storing past examples and maintains a simple architecture, while still providing useful explanations and strong performance. We demonstrate that CIPNet achieves state-of-the-art performances compared to previous exemplar-free and self-explainable methods in both task- and class-incremental settings, while bearing significantly lower memory-related overhead. This makes it a practical and interpretable solution for continual learning.
Fine-grained Analysis of Brain-LLM Alignment through Input Attribution
Oct 14, 2025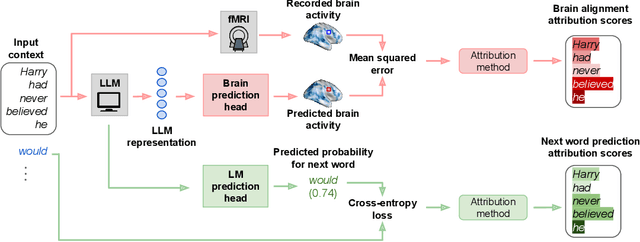

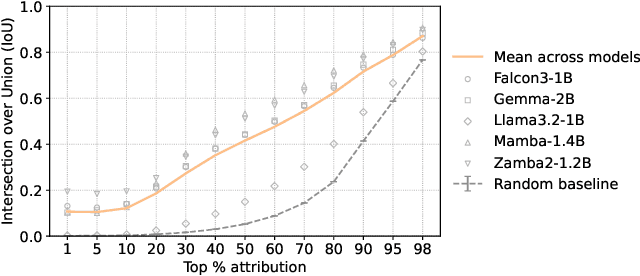
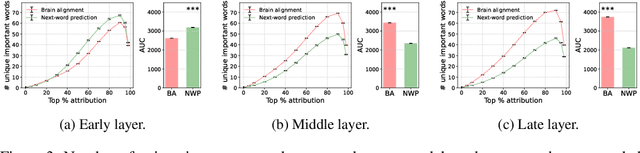
Understanding the alignment between large language models (LLMs) and human brain activity can reveal computational principles underlying language processing. We introduce a fine-grained input attribution method to identify the specific words most important for brain-LLM alignment, and leverage it to study a contentious research question about brain-LLM alignment: the relationship between brain alignment (BA) and next-word prediction (NWP). Our findings reveal that BA and NWP rely on largely distinct word subsets: NWP exhibits recency and primacy biases with a focus on syntax, while BA prioritizes semantic and discourse-level information with a more targeted recency effect. This work advances our understanding of how LLMs relate to human language processing and highlights differences in feature reliance between BA and NWP. Beyond this study, our attribution method can be broadly applied to explore the cognitive relevance of model predictions in diverse language processing tasks.
DeepDFA: Automata Learning through Neural Probabilistic Relaxations
Aug 16, 2024In this work, we introduce DeepDFA, a novel approach to identifying Deterministic Finite Automata (DFAs) from traces, harnessing a differentiable yet discrete model. Inspired by both the probabilistic relaxation of DFAs and Recurrent Neural Networks (RNNs), our model offers interpretability post-training, alongside reduced complexity and enhanced training efficiency compared to traditional RNNs. Moreover, by leveraging gradient-based optimization, our method surpasses combinatorial approaches in both scalability and noise resilience. Validation experiments conducted on target regular languages of varying size and complexity demonstrate that our approach is accurate, fast, and robust to noise in both the input symbols and the output labels of training data, integrating the strengths of both logical grammar induction and deep learning.
Neural Reward Machines
Aug 16, 2024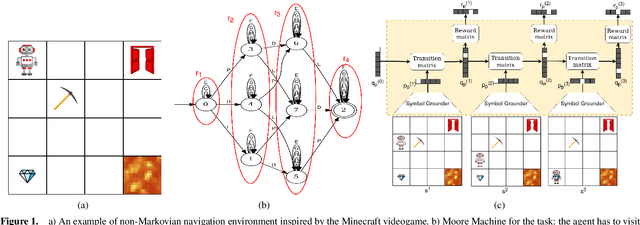
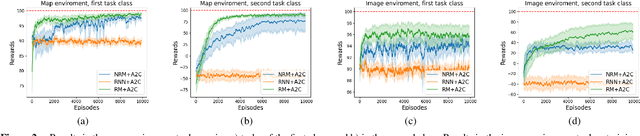

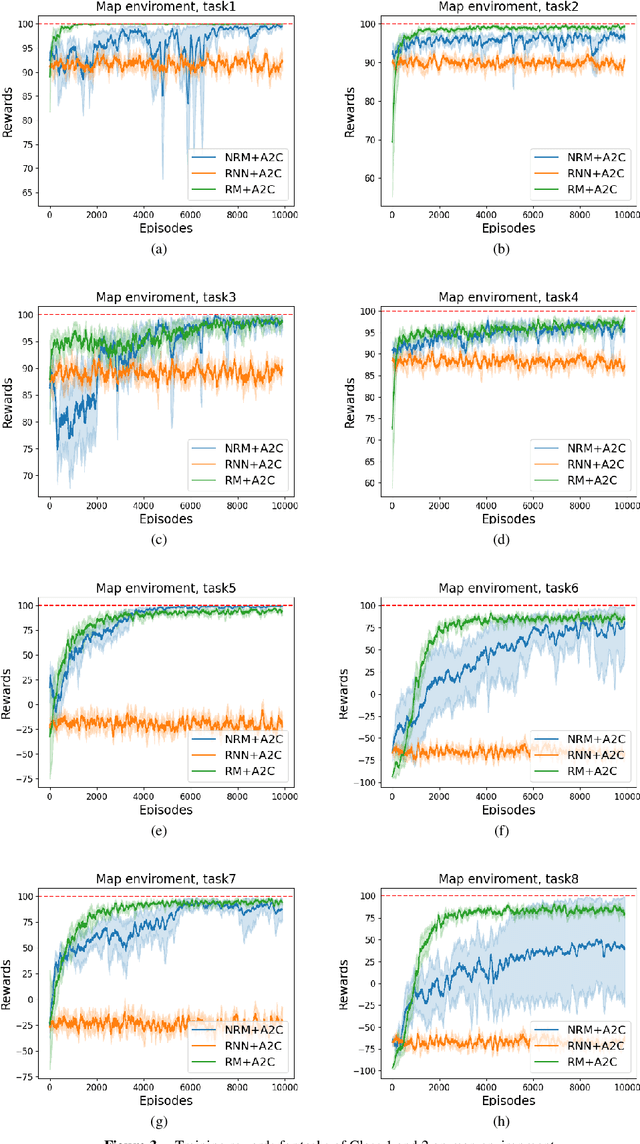
Non-markovian Reinforcement Learning (RL) tasks are very hard to solve, because agents must consider the entire history of state-action pairs to act rationally in the environment. Most works use symbolic formalisms (as Linear Temporal Logic or automata) to specify the temporally-extended task. These approaches only work in finite and discrete state environments or continuous problems for which a mapping between the raw state and a symbolic interpretation is known as a symbol grounding (SG) function. Here, we define Neural Reward Machines (NRM), an automata-based neurosymbolic framework that can be used for both reasoning and learning in non-symbolic non-markovian RL domains, which is based on the probabilistic relaxation of Moore Machines. We combine RL with semisupervised symbol grounding (SSSG) and we show that NRMs can exploit high-level symbolic knowledge in non-symbolic environments without any knowledge of the SG function, outperforming Deep RL methods which cannot incorporate prior knowledge. Moreover, we advance the research in SSSG, proposing an algorithm for analysing the groundability of temporal specifications, which is more efficient than baseline techniques of a factor $10^3$.
Towards a fuller understanding of neurons with Clustered Compositional Explanations
Oct 27, 2023
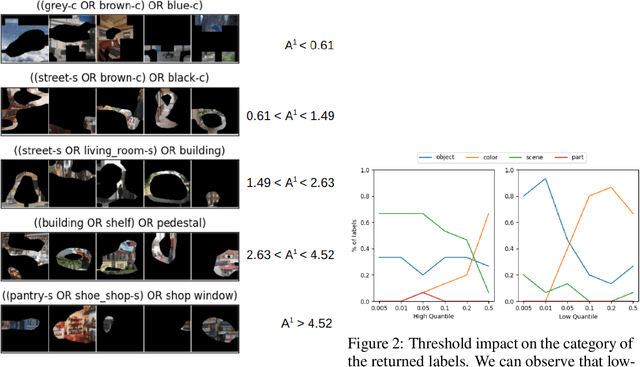

Compositional Explanations is a method for identifying logical formulas of concepts that approximate the neurons' behavior. However, these explanations are linked to the small spectrum of neuron activations (i.e., the highest ones) used to check the alignment, thus lacking completeness. In this paper, we propose a generalization, called Clustered Compositional Explanations, that combines Compositional Explanations with clustering and a novel search heuristic to approximate a broader spectrum of the neurons' behavior. We define and address the problems connected to the application of these methods to multiple ranges of activations, analyze the insights retrievable by using our algorithm, and propose desiderata qualities that can be used to study the explanations returned by different algorithms.
Detection Accuracy for Evaluating Compositional Explanations of Units
Sep 16, 2021

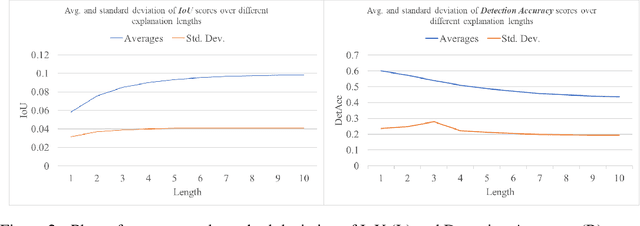
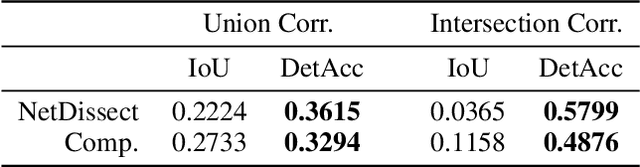
The recent success of deep learning models in solving complex problems and in different domains has increased interest in understanding what they learn. Therefore, different approaches have been employed to explain these models, one of which uses human-understandable concepts as explanations. Two examples of methods that use this approach are Network Dissection and Compositional explanations. The former explains units using atomic concepts, while the latter makes explanations more expressive, replacing atomic concepts with logical forms. While intuitively, logical forms are more informative than atomic concepts, it is not clear how to quantify this improvement, and their evaluation is often based on the same metric that is optimized during the search-process and on the usage of hyper-parameters to be tuned. In this paper, we propose to use as evaluation metric the Detection Accuracy, which measures units' consistency of detection of their assigned explanations. We show that this metric (1) evaluates explanations of different lengths effectively, (2) can be used as a stopping criterion for the compositional explanation search, eliminating the explanation length hyper-parameter, and (3) exposes new specialized units whose length 1 explanations are the perceptual abstractions of their longer explanations.
Memory Wrap: a Data-Efficient and Interpretable Extension to Image Classification Models
Jun 04, 2021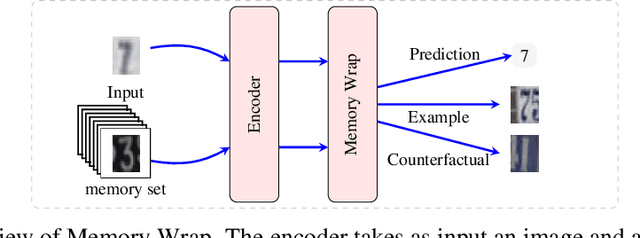
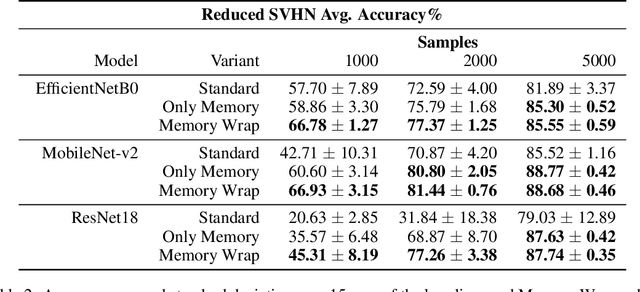
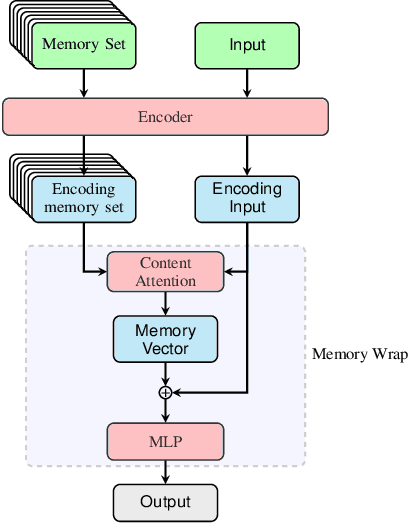
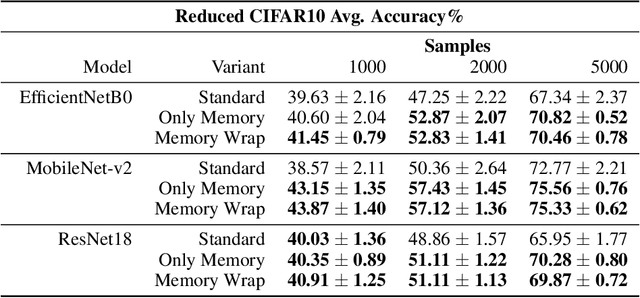
Due to their black-box and data-hungry nature, deep learning techniques are not yet widely adopted for real-world applications in critical domains, like healthcare and justice. This paper presents Memory Wrap, a plug-and-play extension to any image classification model. Memory Wrap improves both data-efficiency and model interpretability, adopting a content-attention mechanism between the input and some memories of past training samples. We show that Memory Wrap outperforms standard classifiers when it learns from a limited set of data, and it reaches comparable performance when it learns from the full dataset. We discuss how its structure and content-attention mechanisms make predictions interpretable, compared to standard classifiers. To this end, we both show a method to build explanations by examples and counterfactuals, based on the memory content, and how to exploit them to get insights about its decision process. We test our approach on image classification tasks using several architectures on three different datasets, namely CIFAR10, SVHN, and CINIC10.
Reinforcement Learning for Optimization of COVID-19 Mitigation policies
Oct 20, 2020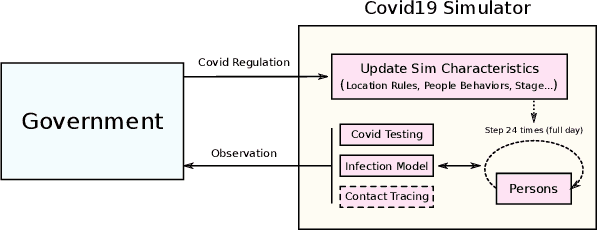
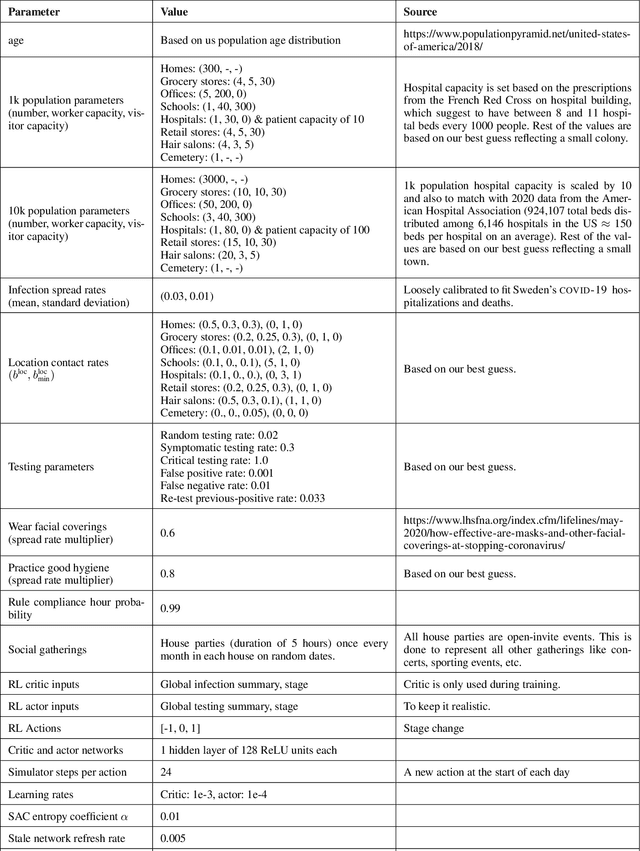
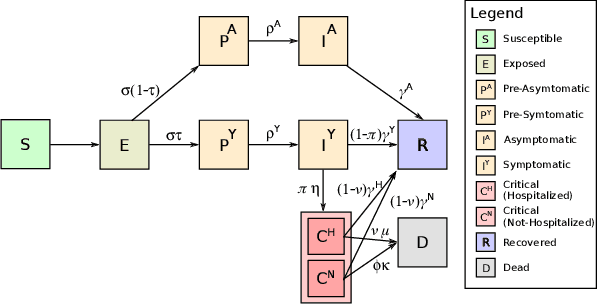
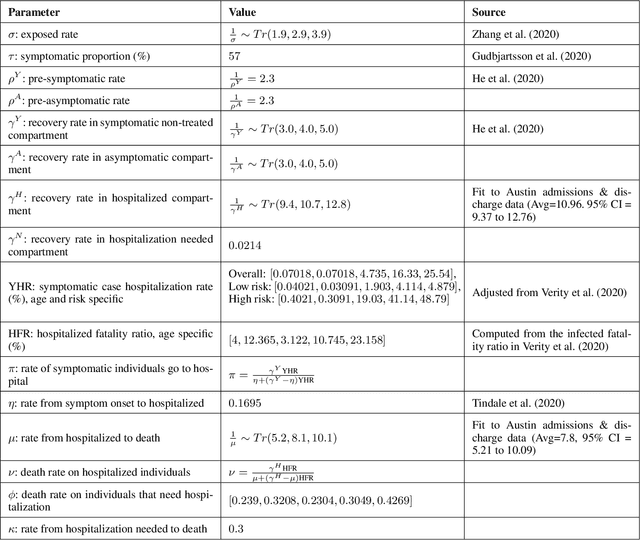
The year 2020 has seen the COVID-19 virus lead to one of the worst global pandemics in history. As a result, governments around the world are faced with the challenge of protecting public health, while keeping the economy running to the greatest extent possible. Epidemiological models provide insight into the spread of these types of diseases and predict the effects of possible intervention policies. However, to date,the even the most data-driven intervention policies rely on heuristics. In this paper, we study how reinforcement learning (RL) can be used to optimize mitigation policies that minimize the economic impact without overwhelming the hospital capacity. Our main contributions are (1) a novel agent-based pandemic simulator which, unlike traditional models, is able to model fine-grained interactions among people at specific locations in a community; and (2) an RL-based methodology for optimizing fine-grained mitigation policies within this simulator. Our results validate both the overall simulator behavior and the learned policies under realistic conditions.