 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Human-Robot Handovers Through $π$-STAM: Policy Improvement With Spatio-Temporal Affordance Maps
Paper and Code
Oct 15, 2016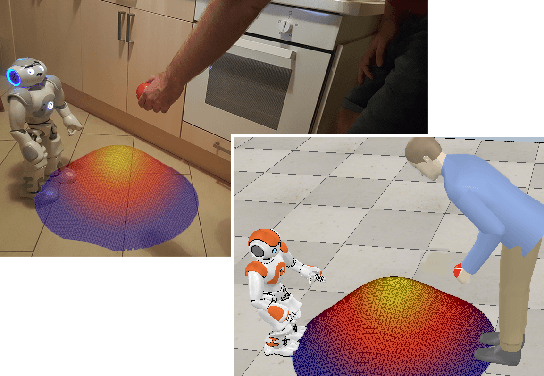
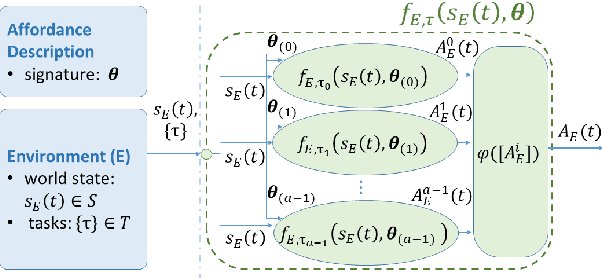
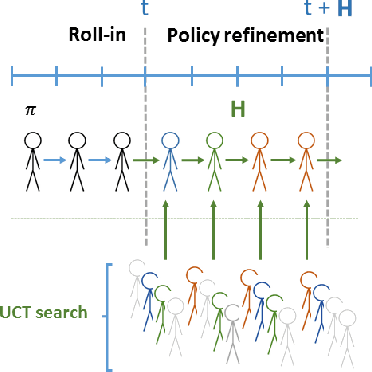
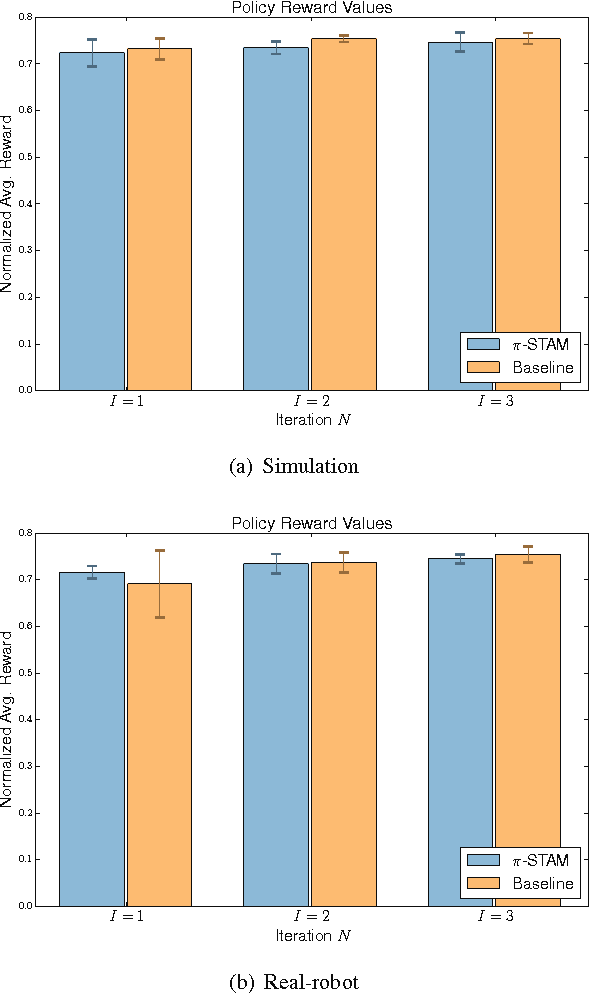
Human-robot handovers are characterized by high uncertainty and poor structure of the problem that make them difficult tasks. While machine learning methods have shown promising results, their application to problems with large state dimensionality, such as in the case of humanoid robots, is still limited. Additionally, by using these methods and during the interaction with the human operator, no guarantees can be obtained on the correct interpretation of spatial constraints (e.g., from social rules). In this paper, we present Policy Improvement with Spatio-Temporal Affordance Maps -- $\pi$-STAM, a novel iterative algorithm to learn spatial affordances and generate robot behaviors. Our goal consists in generating a policy that adapts to the unknown action semantics by using affordances. In this way, while learning to perform a human-robot handover task, we can (1) efficiently generate good policies with few training episodes, and (2) easily encode action semantics and, if available, enforce prior knowledge in it. We experimentally validate our approach both in simulation and on a real NAO robot whose task consists in taking an object from the hands of a human. The obtained results show that our algorithm obtains a good policy while reducing the computational load and time duration of the learning process.