 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNL2ASP: converting controlled natural language sentences into ASP
Nov 17, 2023



Answer Set Programming (ASP) is a popular declarative programming language for solving hard combinatorial problems. Although ASP has gained widespread acceptance in academic and industrial contexts, there are certain user groups who may find it more advantageous to employ a higher-level language that closely resembles natural language when specifying ASP programs. In this paper, we propose a novel tool, called CNL2ASP, for translating English sentences expressed in a controlled natural language (CNL) form into ASP. In particular, we first provide a definition of the type of sentences allowed by our CNL and their translation as ASP rules, and then exemplify the usage of the CNL for the specification of both synthetic and real-world combinatorial problems. Finally, we report the results of an experimental analysis conducted on the real-world problems to compare the performance of automatically generated encodings with the ones written by ASP practitioners, showing that our tool can obtain satisfactory performance on these benchmarks. Under consideration in Theory and Practice of Logic Programming (TPLP).
RoSmEEry: Robotic Simulated Environment for Evaluation and Benchmarking of Semantic Mapping Algorithms
May 17, 2021



Human-robot interaction requires a common understanding of the operational environment, which can be provided by a representation that blends geometric and symbolic knowledge: a semantic map. Through a semantic map the robot can interpret user commands by grounding them to its sensory observations. Semantic mapping is the process that builds such a representation. Despite being fundamental to enable cognition and high-level reasoning in robotics, semantic mapping is a challenging task due to generalization to different scenarios and sensory data types. In fact, it is difficult to obtain a rich and accurate semantic map of the environment and of the objects therein. Moreover, to date, there are no frameworks that allow for a comparison of the performance in building semantic maps for a given environment. To tackle these issues we design RoSmEEry, a novel framework based on the Gazebo simulator, where we introduce an accessible and ready-to-use methodology for a systematic evaluation of semantic mapping algorithms. We release our framework, as an open-source package, with multiple simulation environments with the aim to provide a general set-up to quantitatively measure the performances in acquiring semantic knowledge about the environment.
DOP: Deep Optimistic Planning with Approximate Value Function Evaluation
Mar 22, 2018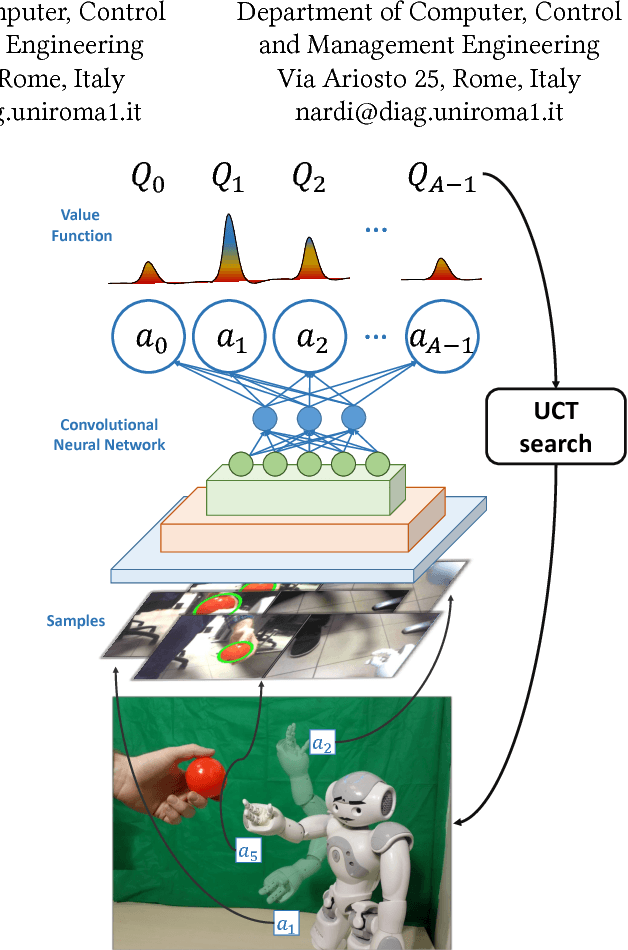
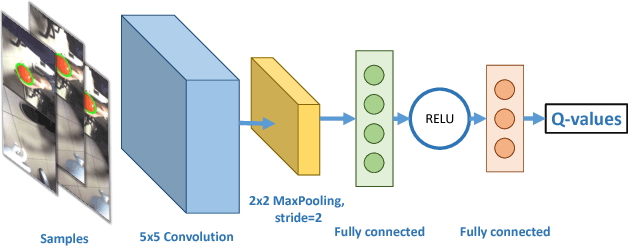

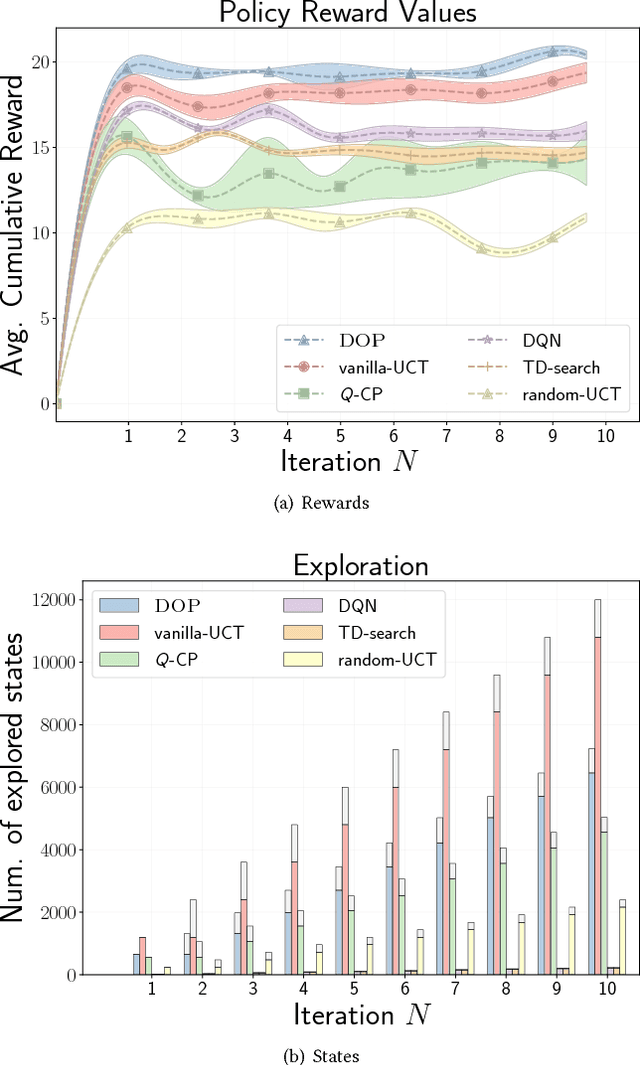
Research on reinforcement learning has demonstrated promising results in manifold applications and domains. Still, efficiently learning effective robot behaviors is very difficult, due to unstructured scenarios, high uncertainties, and large state dimensionality (e.g. multi-agent systems or hyper-redundant robots). To alleviate this problem, we present DOP, a deep model-based reinforcement learning algorithm, which exploits action values to both (1) guide the exploration of the state space and (2) plan effective policies. Specifically, we exploit deep neural networks to learn Q-functions that are used to attack the curse of dimensionality during a Monte-Carlo tree search. Our algorithm, in fact, constructs upper confidence bounds on the learned value function to select actions optimistically. We implement and evaluate DOP on different scenarios: (1) a cooperative navigation problem, (2) a fetching task for a 7-DOF KUKA robot, and (3) a human-robot handover with a humanoid robot (both in simulation and real). The obtained results show the effectiveness of DOP in the chosen applications, where action values drive the exploration and reduce the computational demand of the planning process while achieving good performance.
Q-CP: Learning Action Values for Cooperative Planning
Mar 01, 2018
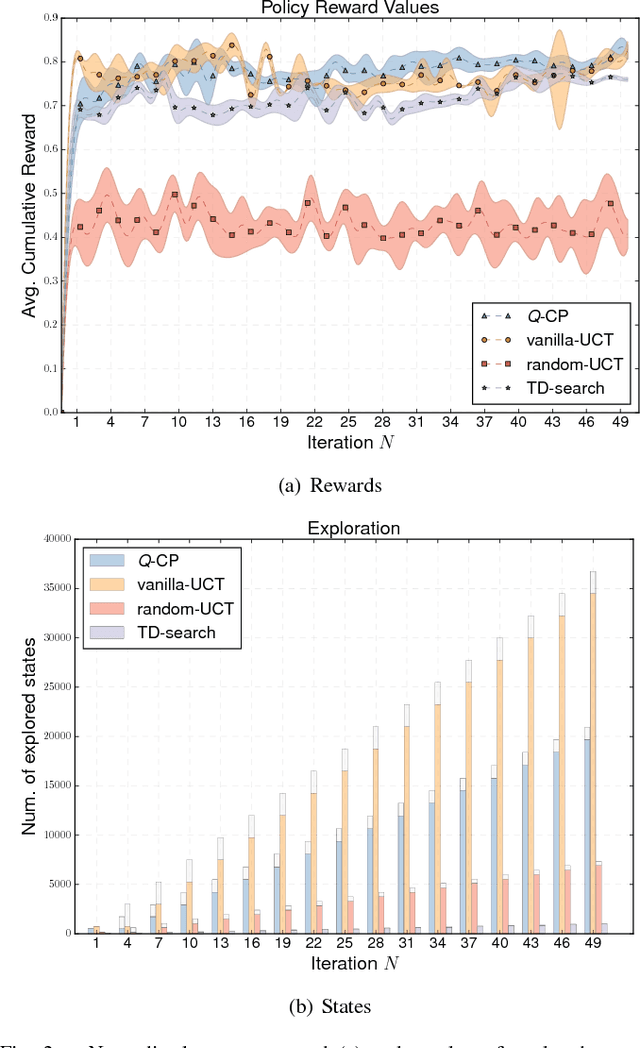
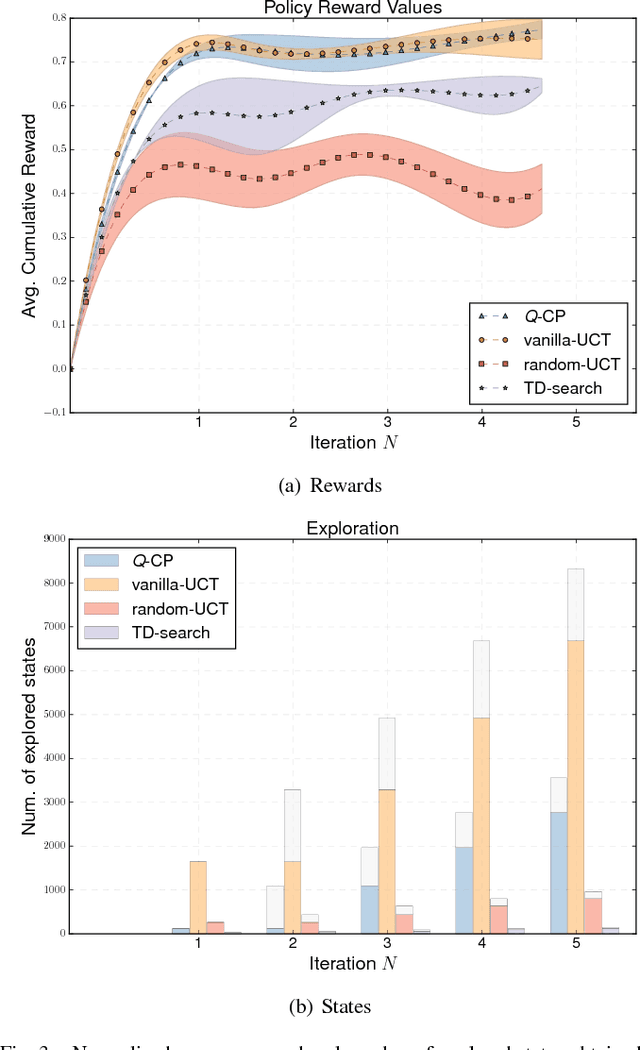
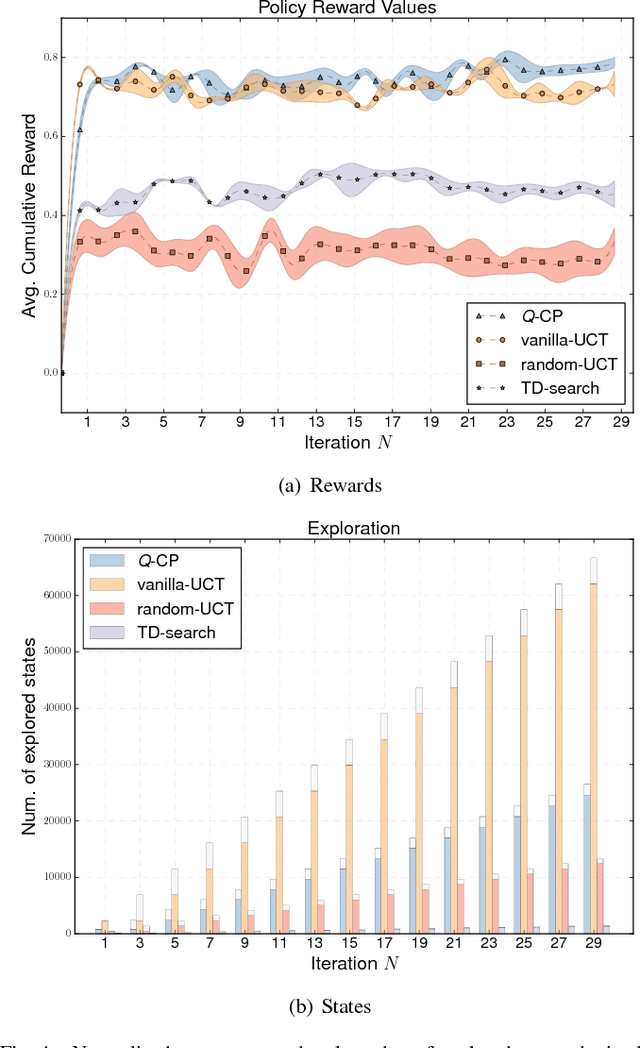
Research on multi-robot systems has demonstrated promising results in manifold applications and domains. Still, efficiently learning an effective robot behaviors is very difficult, due to unstructured scenarios, high uncertainties, and large state dimensionality (e.g. hyper-redundant and groups of robot). To alleviate this problem, we present Q-CP a cooperative model-based reinforcement learning algorithm, which exploits action values to both (1) guide the exploration of the state space and (2) generate effective policies. Specifically, we exploit Q-learning to attack the curse-of-dimensionality in the iterations of a Monte-Carlo Tree Search. We implement and evaluate Q-CP on different stochastic cooperative (general-sum) games: (1) a simple cooperative navigation problem among 3 robots, (2) a cooperation scenario between a pair of KUKA YouBots performing hand-overs, and (3) a coordination task between two mobile robots entering a door. The obtained results show the effectiveness of Q-CP in the chosen applications, where action values drive the exploration and reduce the computational demand of the planning process while achieving good performance.
Learning Human-Robot Handovers Through $π$-STAM: Policy Improvement With Spatio-Temporal Affordance Maps
Oct 15, 2016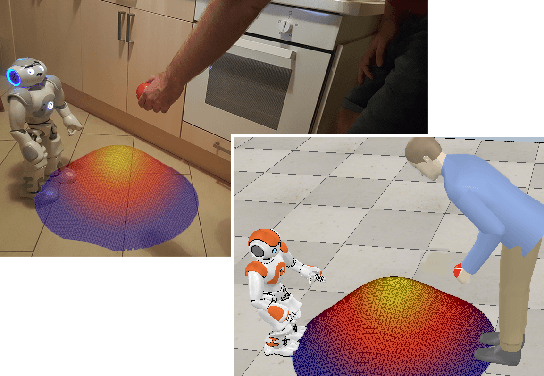
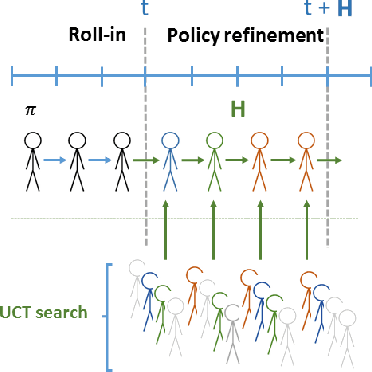
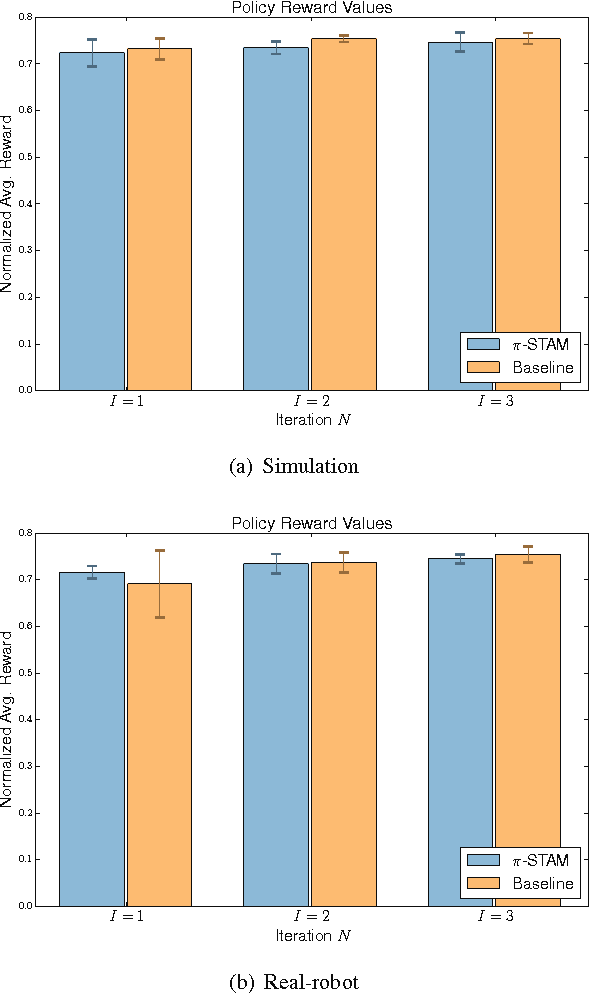
Human-robot handovers are characterized by high uncertainty and poor structure of the problem that make them difficult tasks. While machine learning methods have shown promising results, their application to problems with large state dimensionality, such as in the case of humanoid robots, is still limited. Additionally, by using these methods and during the interaction with the human operator, no guarantees can be obtained on the correct interpretation of spatial constraints (e.g., from social rules). In this paper, we present Policy Improvement with Spatio-Temporal Affordance Maps -- $\pi$-STAM, a novel iterative algorithm to learn spatial affordances and generate robot behaviors. Our goal consists in generating a policy that adapts to the unknown action semantics by using affordances. In this way, while learning to perform a human-robot handover task, we can (1) efficiently generate good policies with few training episodes, and (2) easily encode action semantics and, if available, enforce prior knowledge in it. We experimentally validate our approach both in simulation and on a real NAO robot whose task consists in taking an object from the hands of a human. The obtained results show that our algorithm obtains a good policy while reducing the computational load and time duration of the learning process.
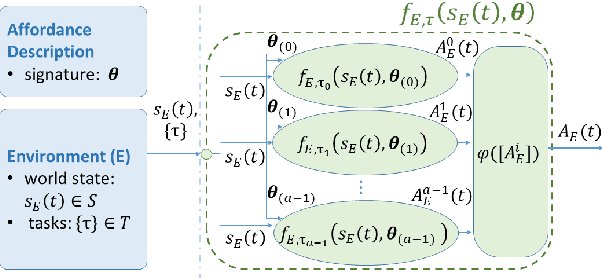
STAM: A Framework for Spatio-Temporal Affordance Maps
Jul 01, 2016

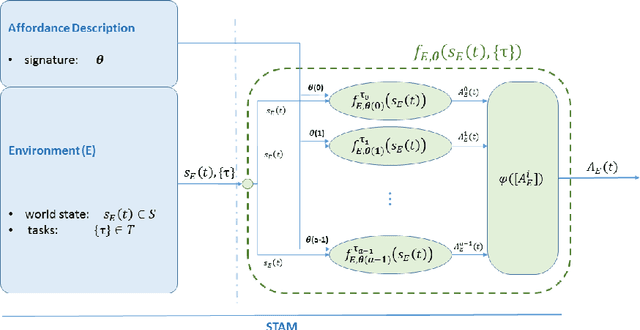

Affordances have been introduced in literature as action opportunities that objects offer, and used in robotics to semantically represent their interconnection. However, when considering an environment instead of an object, the problem becomes more complex due to the dynamism of its state. To tackle this issue, we introduce the concept of Spatio-Temporal Affordances (STA) and Spatio-Temporal Affordance Map (STAM). Using this formalism, we encode action semantics related to the environment to improve task execution capabilities of an autonomous robot. We experimentally validate our approach to support the execution of robot tasks by showing that affordances encode accurate semantics of the environment.
Using Monte Carlo Search With Data Aggregation to Improve Robot Soccer Policies
Jun 01, 2016
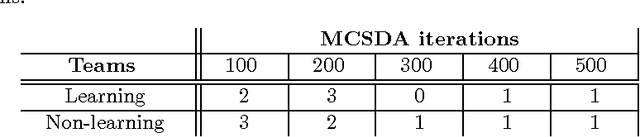

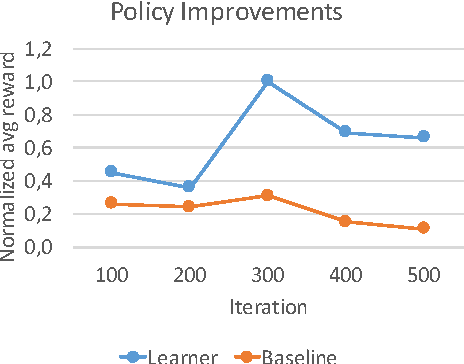
RoboCup soccer competitions are considered among the most challenging multi-robot adversarial environments, due to their high dynamism and the partial observability of the environment. In this paper we introduce a method based on a combination of Monte Carlo search and data aggregation (MCSDA) to adapt discrete-action soccer policies for a defender robot to the strategy of the opponent team. By exploiting a simple representation of the domain, a supervised learning algorithm is trained over an initial collection of data consisting of several simulations of human expert policies. Monte Carlo policy rollouts are then generated and aggregated to previous data to improve the learned policy over multiple epochs and games. The proposed approach has been extensively tested both on a soccer-dedicated simulator and on real robots. Using this method, our learning robot soccer team achieves an improvement in ball interceptions, as well as a reduction in the number of opponents' goals. Together with a better performance, an overall more efficient positioning of the whole team within the field is achieved.