 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOP: Deep Optimistic Planning with Approximate Value Function Evaluation
Paper and Code
Mar 22, 2018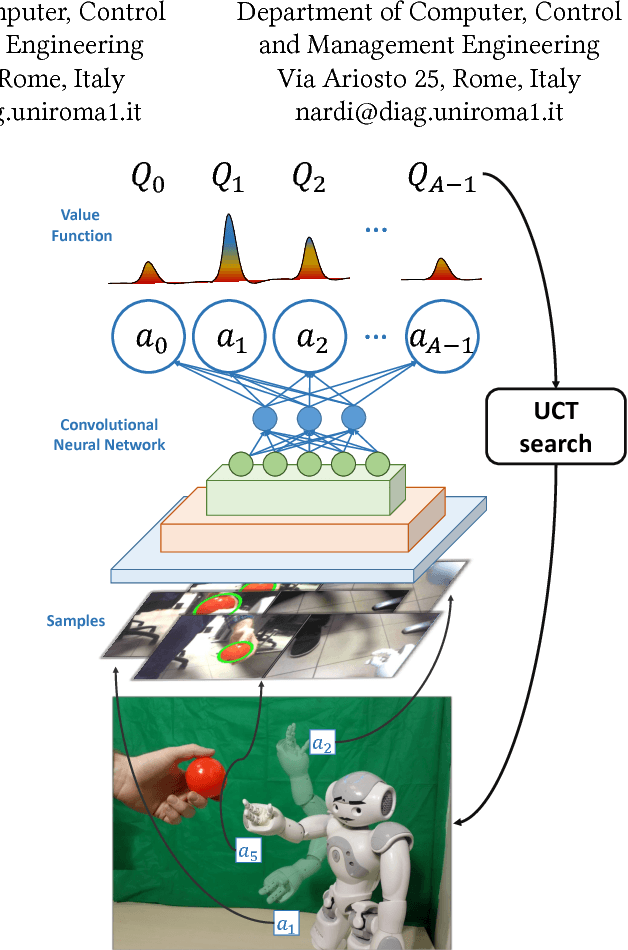
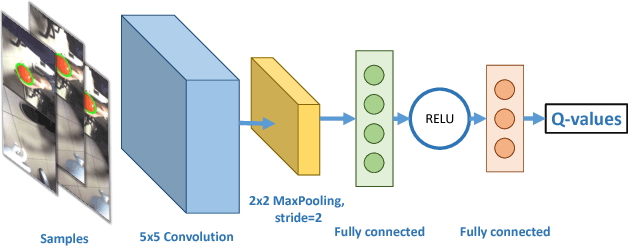

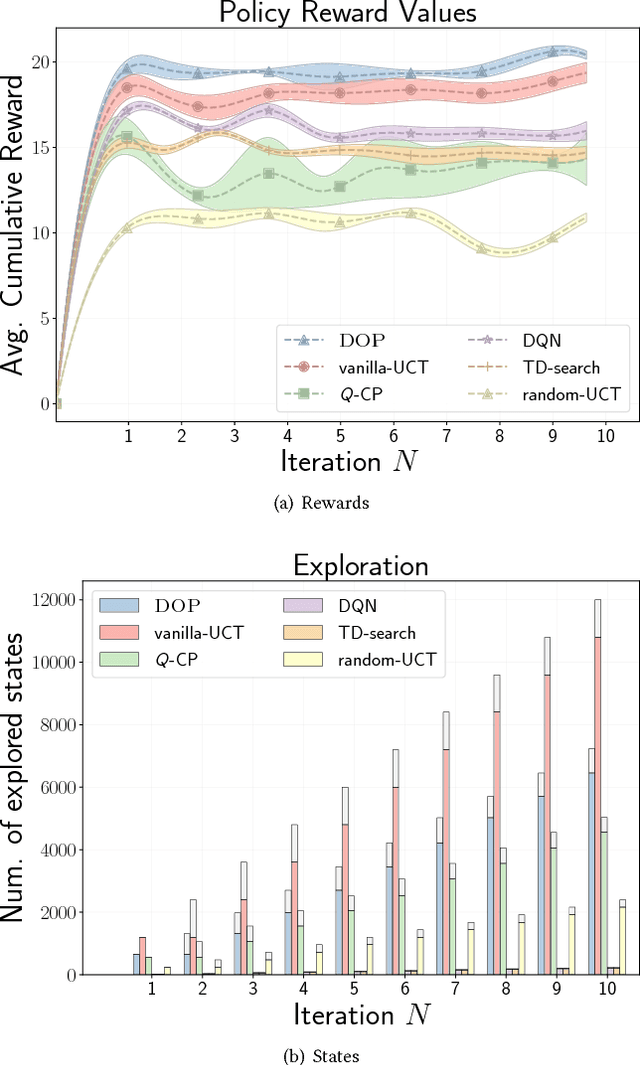
Research on reinforcement learning has demonstrated promising results in manifold applications and domains. Still, efficiently learning effective robot behaviors is very difficult, due to unstructured scenarios, high uncertainties, and large state dimensionality (e.g. multi-agent systems or hyper-redundant robots). To alleviate this problem, we present DOP, a deep model-based reinforcement learning algorithm, which exploits action values to both (1) guide the exploration of the state space and (2) plan effective policies. Specifically, we exploit deep neural networks to learn Q-functions that are used to attack the curse of dimensionality during a Monte-Carlo tree search. Our algorithm, in fact, constructs upper confidence bounds on the learned value function to select actions optimistically. We implement and evaluate DOP on different scenarios: (1) a cooperative navigation problem, (2) a fetching task for a 7-DOF KUKA robot, and (3) a human-robot handover with a humanoid robot (both in simulation and real). The obtained results show the effectiveness of DOP in the chosen applications, where action values drive the exploration and reduce the computational demand of the planning process while achieving good performance.