 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Monte Carlo Search With Data Aggregation to Improve Robot Soccer Policies
Paper and Code
Jun 01, 2016
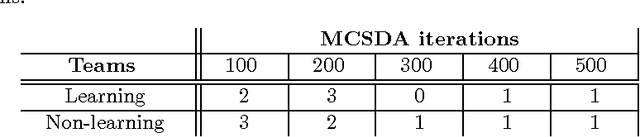

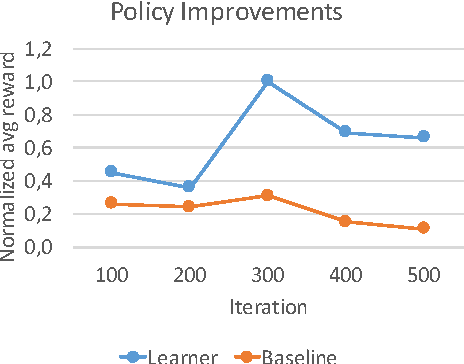
RoboCup soccer competitions are considered among the most challenging multi-robot adversarial environments, due to their high dynamism and the partial observability of the environment. In this paper we introduce a method based on a combination of Monte Carlo search and data aggregation (MCSDA) to adapt discrete-action soccer policies for a defender robot to the strategy of the opponent team. By exploiting a simple representation of the domain, a supervised learning algorithm is trained over an initial collection of data consisting of several simulations of human expert policies. Monte Carlo policy rollouts are then generated and aggregated to previous data to improve the learned policy over multiple epochs and games. The proposed approach has been extensively tested both on a soccer-dedicated simulator and on real robots. Using this method, our learning robot soccer team achieves an improvement in ball interceptions, as well as a reduction in the number of opponents' goals. Together with a better performance, an overall more efficient positioning of the whole team within the field is achieved.