 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Deep Neural Networks by Leveraging Intrinsic Methods
Jul 17, 2024Despite their impact on the society, deep neural networks are often regarded as black-box models due to their intricate structures and the absence of explanations for their decisions. This opacity poses a significant challenge to AI systems wider adoption and trustworthiness. This thesis addresses this issue by contributing to the field of eXplainable AI, focusing on enhancing the interpretability of deep neural networks. The core contributions lie in introducing novel techniques aimed at making these networks more interpretable by leveraging an analysis of their inner workings. Specifically, the contributions are threefold. Firstly, the thesis introduces designs for self-explanatory deep neural networks, such as the integration of external memory for interpretability purposes and the usage of prototype and constraint-based layers across several domains. Secondly, this research delves into novel investigations on neurons within trained deep neural networks, shedding light on overlooked phenomena related to their activation values. Lastly, the thesis conducts an analysis of the application of explanatory techniques in the field of visual analytics, exploring the maturity of their adoption and the potential of these systems to convey explanations to users effectively.
Towards a fuller understanding of neurons with Clustered Compositional Explanations
Oct 27, 2023Compositional Explanations is a method for identifying logical formulas of concepts that approximate the neurons' behavior. However, these explanations are linked to the small spectrum of neuron activations (i.e., the highest ones) used to check the alignment, thus lacking completeness. In this paper, we propose a generalization, called Clustered Compositional Explanations, that combines Compositional Explanations with clustering and a novel search heuristic to approximate a broader spectrum of the neurons' behavior. We define and address the problems connected to the application of these methods to multiple ranges of activations, analyze the insights retrievable by using our algorithm, and propose desiderata qualities that can be used to study the explanations returned by different algorithms.
Detection Accuracy for Evaluating Compositional Explanations of Units
Sep 16, 2021

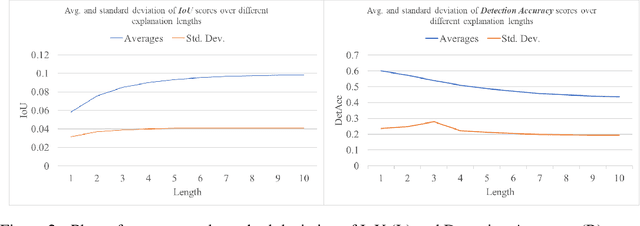
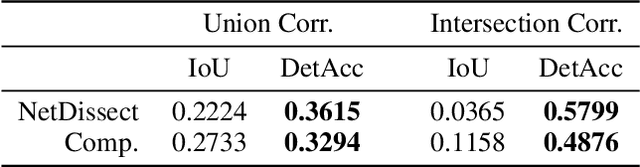
The recent success of deep learning models in solving complex problems and in different domains has increased interest in understanding what they learn. Therefore, different approaches have been employed to explain these models, one of which uses human-understandable concepts as explanations. Two examples of methods that use this approach are Network Dissection and Compositional explanations. The former explains units using atomic concepts, while the latter makes explanations more expressive, replacing atomic concepts with logical forms. While intuitively, logical forms are more informative than atomic concepts, it is not clear how to quantify this improvement, and their evaluation is often based on the same metric that is optimized during the search-process and on the usage of hyper-parameters to be tuned. In this paper, we propose to use as evaluation metric the Detection Accuracy, which measures units' consistency of detection of their assigned explanations. We show that this metric (1) evaluates explanations of different lengths effectively, (2) can be used as a stopping criterion for the compositional explanation search, eliminating the explanation length hyper-parameter, and (3) exposes new specialized units whose length 1 explanations are the perceptual abstractions of their longer explanations.
Memory Wrap: a Data-Efficient and Interpretable Extension to Image Classification Models
Jun 04, 2021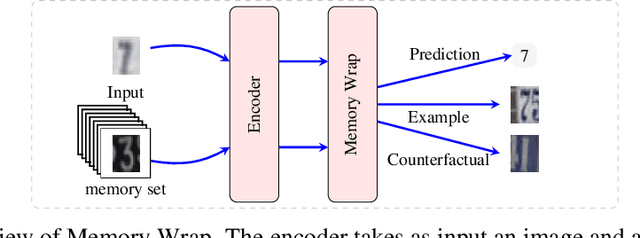
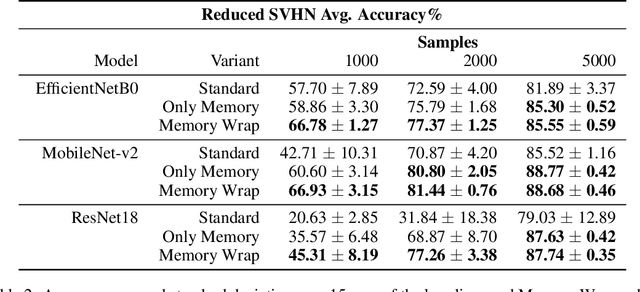
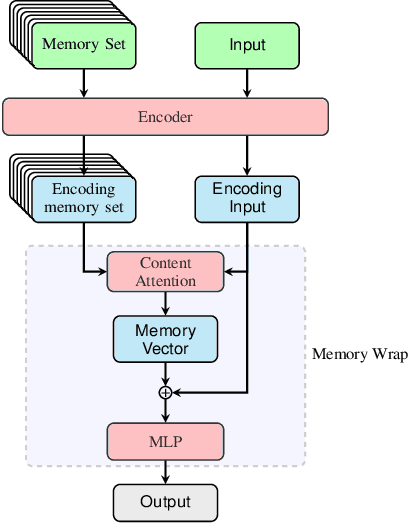
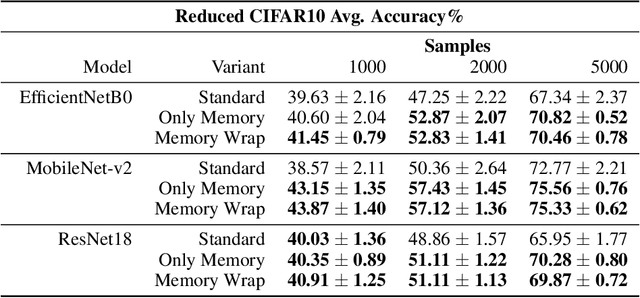
Due to their black-box and data-hungry nature, deep learning techniques are not yet widely adopted for real-world applications in critical domains, like healthcare and justice. This paper presents Memory Wrap, a plug-and-play extension to any image classification model. Memory Wrap improves both data-efficiency and model interpretability, adopting a content-attention mechanism between the input and some memories of past training samples. We show that Memory Wrap outperforms standard classifiers when it learns from a limited set of data, and it reaches comparable performance when it learns from the full dataset. We discuss how its structure and content-attention mechanisms make predictions interpretable, compared to standard classifiers. To this end, we both show a method to build explanations by examples and counterfactuals, based on the memory content, and how to exploit them to get insights about its decision process. We test our approach on image classification tasks using several architectures on three different datasets, namely CIFAR10, SVHN, and CINIC10.