 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Reward Machines
Paper and Code
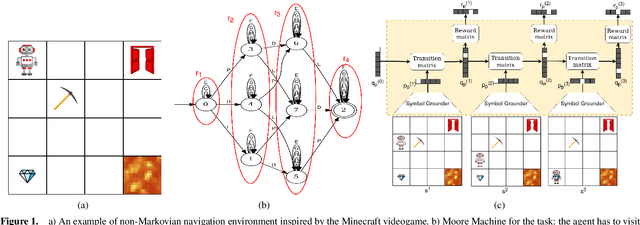
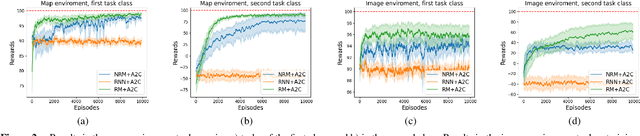

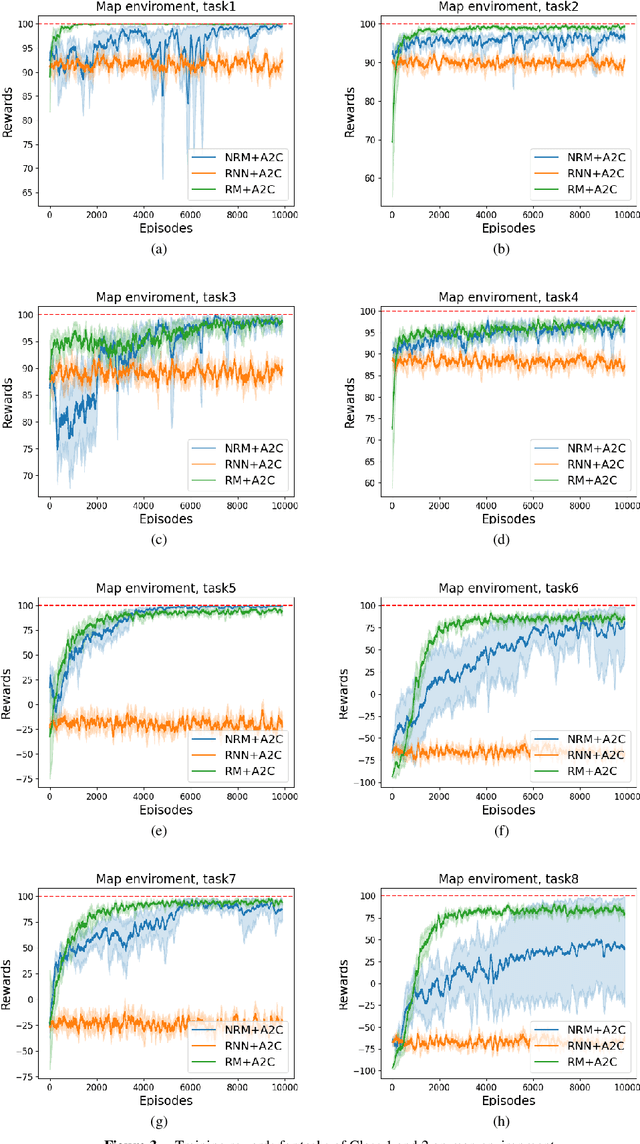
Non-markovian Reinforcement Learning (RL) tasks are very hard to solve, because agents must consider the entire history of state-action pairs to act rationally in the environment. Most works use symbolic formalisms (as Linear Temporal Logic or automata) to specify the temporally-extended task. These approaches only work in finite and discrete state environments or continuous problems for which a mapping between the raw state and a symbolic interpretation is known as a symbol grounding (SG) function. Here, we define Neural Reward Machines (NRM), an automata-based neurosymbolic framework that can be used for both reasoning and learning in non-symbolic non-markovian RL domains, which is based on the probabilistic relaxation of Moore Machines. We combine RL with semisupervised symbol grounding (SSSG) and we show that NRMs can exploit high-level symbolic knowledge in non-symbolic environments without any knowledge of the SG function, outperforming Deep RL methods which cannot incorporate prior knowledge. Moreover, we advance the research in SSSG, proposing an algorithm for analysing the groundability of temporal specifications, which is more efficient than baseline techniques of a factor $10^3$.