 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepDFA: Injecting Temporal Logic in Deep Learning for Sequential Subsymbolic Applications
Feb 03, 2026Integrating logical knowledge into deep neural network training is still a hard challenge, especially for sequential or temporally extended domains involving subsymbolic observations. To address this problem, we propose DeepDFA, a neurosymbolic framework that integrates high-level temporal logic - expressed as Deterministic Finite Automata (DFA) or Moore Machines - into neural architectures. DeepDFA models temporal rules as continuous, differentiable layers, enabling symbolic knowledge injection into subsymbolic domains. We demonstrate how DeepDFA can be used in two key settings: (i) static image sequence classification, and (ii) policy learning in interactive non-Markovian environments. Across extensive experiments, DeepDFA outperforms traditional deep learning models (e.g., LSTMs, GRUs, Transformers) and novel neuro-symbolic systems, achieving state-of-the-art results in temporal knowledge integration. These results highlight the potential of DeepDFA to bridge subsymbolic learning and symbolic reasoning in sequential tasks.
LOST-3DSG: Lightweight Open-Vocabulary 3D Scene Graphs with Semantic Tracking in Dynamic Environments
Jan 06, 2026Tracking objects that move within dynamic environments is a core challenge in robotics. Recent research has advanced this topic significantly; however, many existing approaches remain inefficient due to their reliance on heavy foundation models. To address this limitation, we propose LOST-3DSG, a lightweight open-vocabulary 3D scene graph designed to track dynamic objects in real-world environments. Our method adopts a semantic approach to entity tracking based on word2vec and sentence embeddings, enabling an open-vocabulary representation while avoiding the necessity of storing dense CLIP visual features. As a result, LOST-3DSG achieves superior performance compared to approaches that rely on high-dimensional visual embeddings. We evaluate our method through qualitative and quantitative experiments conducted in a real 3D environment using a TIAGo robot. The results demonstrate the effectiveness and efficiency of LOST-3DSG in dynamic object tracking. Code and supplementary material are publicly available on the project website at https://lab-rococo-sapienza.github.io/lost-3dsg/.
Defining and Monitoring Complex Robot Activities via LLMs and Symbolic Reasoning
Sep 19, 2025Recent years have witnessed a growing interest in automating labor-intensive and complex activities, i.e., those consisting of multiple atomic tasks, by deploying robots in dynamic and unpredictable environments such as industrial and agricultural settings. A key characteristic of these contexts is that activities are not predefined: while they involve a limited set of possible tasks, their combinations may vary depending on the situation. Moreover, despite recent advances in robotics, the ability for humans to monitor the progress of high-level activities - in terms of past, present, and future actions - remains fundamental to ensure the correct execution of safety-critical processes. In this paper, we introduce a general architecture that integrates Large Language Models (LLMs) with automated planning, enabling humans to specify high-level activities (also referred to as processes) using natural language, and to monitor their execution by querying a robot. We also present an implementation of this architecture using state-of-the-art components and quantitatively evaluate the approach in a real-world precision agriculture scenario.
EMPOWER: Embodied Multi-role Open-vocabulary Planning with Online Grounding and Execution
Aug 30, 2024Task planning for robots in real-life settings presents significant challenges. These challenges stem from three primary issues: the difficulty in identifying grounded sequences of steps to achieve a goal; the lack of a standardized mapping between high-level actions and low-level commands; and the challenge of maintaining low computational overhead given the limited resources of robotic hardware. We introduce EMPOWER, a framework designed for open-vocabulary online grounding and planning for embodied agents aimed at addressing these issues. By leveraging efficient pre-trained foundation models and a multi-role mechanism, EMPOWER demonstrates notable improvements in grounded planning and execution. Quantitative results highlight the effectiveness of our approach, achieving an average success rate of 0.73 across six different real-life scenarios using a TIAGo robot.
Neural Reward Machines
Aug 16, 2024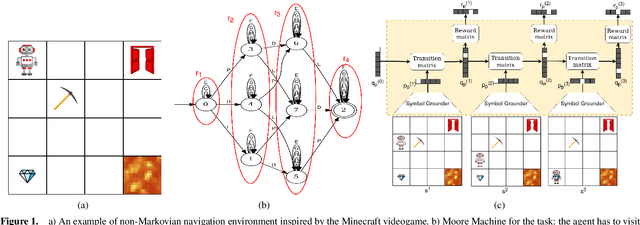
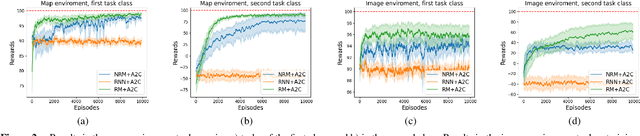

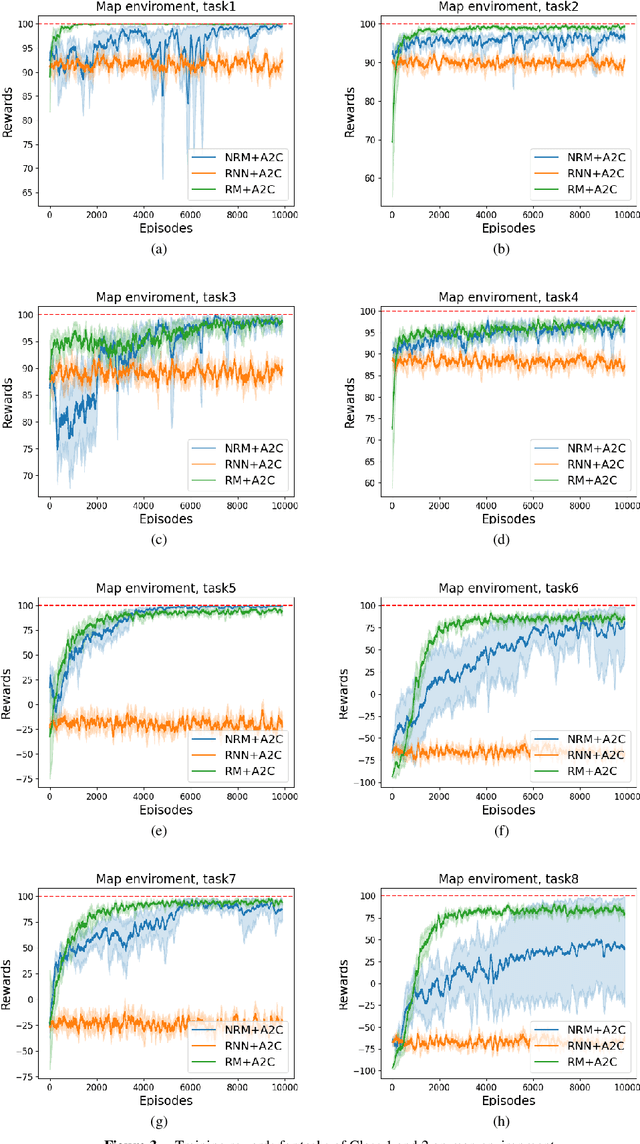
Non-markovian Reinforcement Learning (RL) tasks are very hard to solve, because agents must consider the entire history of state-action pairs to act rationally in the environment. Most works use symbolic formalisms (as Linear Temporal Logic or automata) to specify the temporally-extended task. These approaches only work in finite and discrete state environments or continuous problems for which a mapping between the raw state and a symbolic interpretation is known as a symbol grounding (SG) function. Here, we define Neural Reward Machines (NRM), an automata-based neurosymbolic framework that can be used for both reasoning and learning in non-symbolic non-markovian RL domains, which is based on the probabilistic relaxation of Moore Machines. We combine RL with semisupervised symbol grounding (SSSG) and we show that NRMs can exploit high-level symbolic knowledge in non-symbolic environments without any knowledge of the SG function, outperforming Deep RL methods which cannot incorporate prior knowledge. Moreover, we advance the research in SSSG, proposing an algorithm for analysing the groundability of temporal specifications, which is more efficient than baseline techniques of a factor $10^3$.
Multi-agent Planning using Visual Language Models
Aug 10, 2024Large Language Models (LLMs) and Visual Language Models (VLMs) are attracting increasing interest due to their improving performance and applications across various domains and tasks. However, LLMs and VLMs can produce erroneous results, especially when a deep understanding of the problem domain is required. For instance, when planning and perception are needed simultaneously, these models often struggle because of difficulties in merging multi-modal information. To address this issue, fine-tuned models are typically employed and trained on specialized data structures representing the environment. This approach has limited effectiveness, as it can overly complicate the context for processing. In this paper, we propose a multi-agent architecture for embodied task planning that operates without the need for specific data structures as input. Instead, it uses a single image of the environment, handling free-form domains by leveraging commonsense knowledge. We also introduce a novel, fully automatic evaluation procedure, PG2S, designed to better assess the quality of a plan. We validated our approach using the widely recognized ALFRED dataset, comparing PG2S to the existing KAS metric to further evaluate the quality of the generated plans.
Enhancing Graph Representation of the Environment through Local and Cloud Computation
Sep 22, 2023

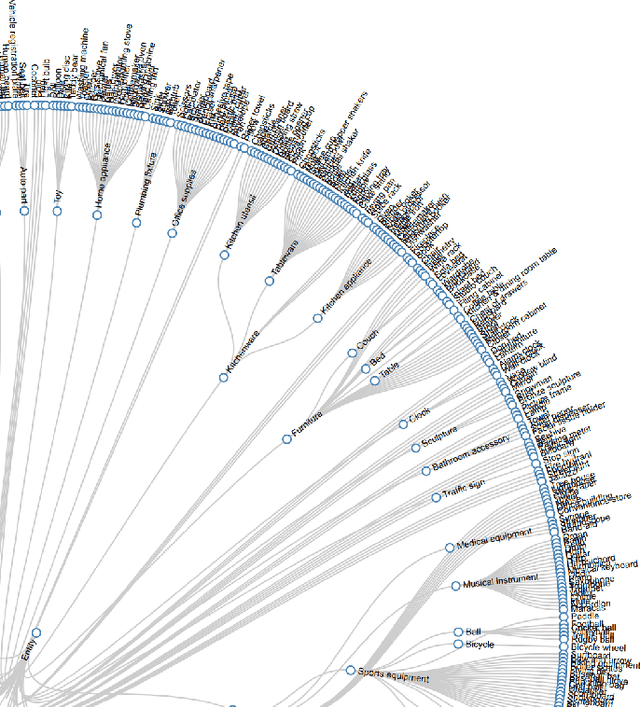

Enriching the robot representation of the operational environment is a challenging task that aims at bridging the gap between low-level sensor readings and high-level semantic understanding. Having a rich representation often requires computationally demanding architectures and pure point cloud based detection systems that struggle when dealing with everyday objects that have to be handled by the robot. To overcome these issues, we propose a graph-based representation that addresses this gap by providing a semantic representation of robot environments from multiple sources. In fact, to acquire information from the environment, the framework combines classical computer vision tools with modern computer vision cloud services, ensuring computational feasibility on onboard hardware. By incorporating an ontology hierarchy with over 800 object classes, the framework achieves cross-domain adaptability, eliminating the need for environment-specific tools. The proposed approach allows us to handle also small objects and integrate them into the semantic representation of the environment. The approach is implemented in the Robot Operating System (ROS) using the RViz visualizer for environment representation. This work is a first step towards the development of a general-purpose framework, to facilitate intuitive interaction and navigation across different domains.