 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Graph Representation of the Environment through Local and Cloud Computation
Paper and Code
Sep 22, 2023

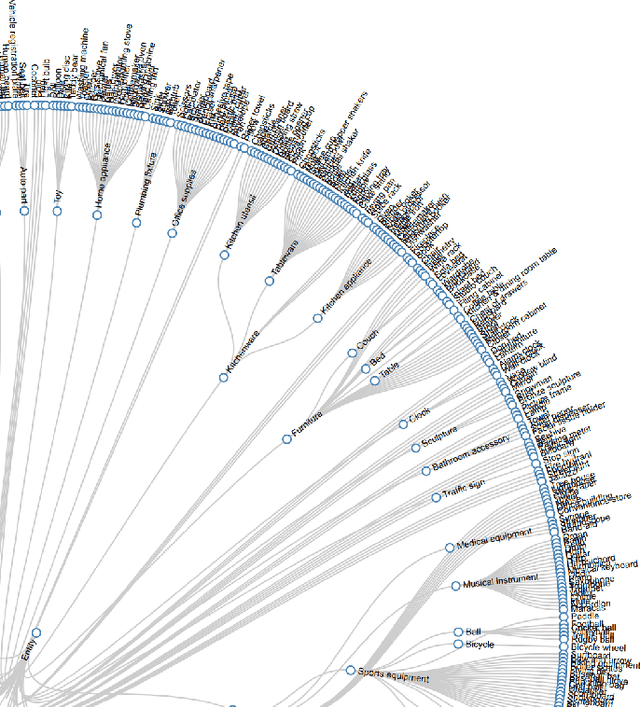

Enriching the robot representation of the operational environment is a challenging task that aims at bridging the gap between low-level sensor readings and high-level semantic understanding. Having a rich representation often requires computationally demanding architectures and pure point cloud based detection systems that struggle when dealing with everyday objects that have to be handled by the robot. To overcome these issues, we propose a graph-based representation that addresses this gap by providing a semantic representation of robot environments from multiple sources. In fact, to acquire information from the environment, the framework combines classical computer vision tools with modern computer vision cloud services, ensuring computational feasibility on onboard hardware. By incorporating an ontology hierarchy with over 800 object classes, the framework achieves cross-domain adaptability, eliminating the need for environment-specific tools. The proposed approach allows us to handle also small objects and integrate them into the semantic representation of the environment. The approach is implemented in the Robot Operating System (ROS) using the RViz visualizer for environment representation. This work is a first step towards the development of a general-purpose framework, to facilitate intuitive interaction and navigation across different domains.