 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2F: Repurposing Ray Frontiers for LLM-free Object Navigation
Mar 09, 2026Zero-shot open-vocabulary object navigation has progressed rapidly with the emergence of large Vision-Language Models (VLMs) and Large Language Models (LLMs), now widely used as high-level decision-makers instead of end-to-end policies. Although effective, such systems often rely on iterative large-model queries at inference time, introducing latency and computational overhead that limit real-time deployment. To address this problem, we repurpose ray frontiers (R2F), a recently proposed frontier-based exploration paradigm, to develop an LLM-free framework for indoor open-vocabulary object navigation. While ray frontiers were originally used to bias exploration using semantic cues carried along rays, we reinterpret frontier regions as explicit, direction-conditioned semantic hypotheses that serve as navigation goals. Language-aligned features accumulated along out-of-range rays are stored sparsely at frontiers, where each region maintains multiple directional embeddings encoding plausible unseen content. In this way, navigation then reduces to embedding-based frontier scoring and goal tracking within a classical mapping and planning pipeline, eliminating iterative large-model reasoning. We further introduce R2F-VLN, a lightweight extension for free-form language instructions using syntactic parsing and relational verification without additional VLM or LLM components. Experiments in Habitat-sim and on a real robotic platform demonstrate competitive state-of-the-art zero-shot performance with real-time execution, achieving up to 6 times faster runtime than VLM-based alternatives.
LOST-3DSG: Lightweight Open-Vocabulary 3D Scene Graphs with Semantic Tracking in Dynamic Environments
Jan 06, 2026Tracking objects that move within dynamic environments is a core challenge in robotics. Recent research has advanced this topic significantly; however, many existing approaches remain inefficient due to their reliance on heavy foundation models. To address this limitation, we propose LOST-3DSG, a lightweight open-vocabulary 3D scene graph designed to track dynamic objects in real-world environments. Our method adopts a semantic approach to entity tracking based on word2vec and sentence embeddings, enabling an open-vocabulary representation while avoiding the necessity of storing dense CLIP visual features. As a result, LOST-3DSG achieves superior performance compared to approaches that rely on high-dimensional visual embeddings. We evaluate our method through qualitative and quantitative experiments conducted in a real 3D environment using a TIAGo robot. The results demonstrate the effectiveness and efficiency of LOST-3DSG in dynamic object tracking. Code and supplementary material are publicly available on the project website at https://lab-rococo-sapienza.github.io/lost-3dsg/.
Real-Time Multimodal Signal Processing for HRI in RoboCup: Understanding a Human Referee
Nov 26, 2024


Advancing human-robot communication is crucial for autonomous systems operating in dynamic environments, where accurate real-time interpretation of human signals is essential. RoboCup provides a compelling scenario for testing these capabilities, requiring robots to understand referee gestures and whistle with minimal network reliance. Using the NAO robot platform, this study implements a two-stage pipeline for gesture recognition through keypoint extraction and classification, alongside continuous convolutional neural networks (CCNNs) for efficient whistle detection. The proposed approach enhances real-time human-robot interaction in a competitive setting like RoboCup, offering some tools to advance the development of autonomous systems capable of cooperating with humans.
EMPOWER: Embodied Multi-role Open-vocabulary Planning with Online Grounding and Execution
Aug 30, 2024Task planning for robots in real-life settings presents significant challenges. These challenges stem from three primary issues: the difficulty in identifying grounded sequences of steps to achieve a goal; the lack of a standardized mapping between high-level actions and low-level commands; and the challenge of maintaining low computational overhead given the limited resources of robotic hardware. We introduce EMPOWER, a framework designed for open-vocabulary online grounding and planning for embodied agents aimed at addressing these issues. By leveraging efficient pre-trained foundation models and a multi-role mechanism, EMPOWER demonstrates notable improvements in grounded planning and execution. Quantitative results highlight the effectiveness of our approach, achieving an average success rate of 0.73 across six different real-life scenarios using a TIAGo robot.
Multi-agent Planning using Visual Language Models
Aug 10, 2024Large Language Models (LLMs) and Visual Language Models (VLMs) are attracting increasing interest due to their improving performance and applications across various domains and tasks. However, LLMs and VLMs can produce erroneous results, especially when a deep understanding of the problem domain is required. For instance, when planning and perception are needed simultaneously, these models often struggle because of difficulties in merging multi-modal information. To address this issue, fine-tuned models are typically employed and trained on specialized data structures representing the environment. This approach has limited effectiveness, as it can overly complicate the context for processing. In this paper, we propose a multi-agent architecture for embodied task planning that operates without the need for specific data structures as input. Instead, it uses a single image of the environment, handling free-form domains by leveraging commonsense knowledge. We also introduce a novel, fully automatic evaluation procedure, PG2S, designed to better assess the quality of a plan. We validated our approach using the widely recognized ALFRED dataset, comparing PG2S to the existing KAS metric to further evaluate the quality of the generated plans.
LLCoach: Generating Robot Soccer Plans using Multi-Role Large Language Models
Jun 26, 2024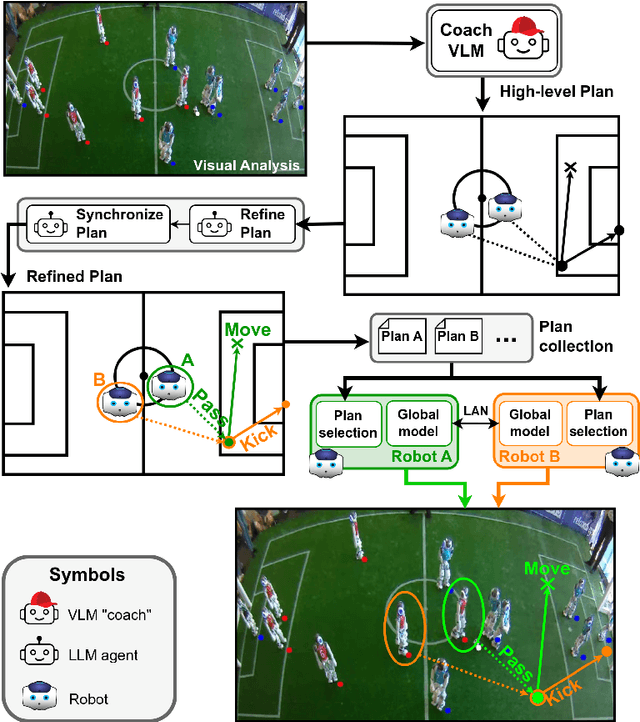

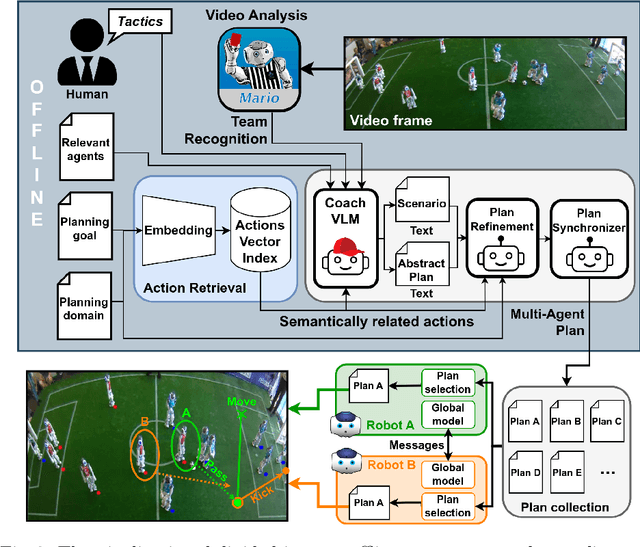

The deployment of robots into human scenarios necessitates advanced planning strategies, particularly when we ask robots to operate in dynamic, unstructured environments. RoboCup offers the chance to deploy robots in one of those scenarios, a human-shaped game represented by a soccer match. In such scenarios, robots must operate using predefined behaviors that can fail in unpredictable conditions. This paper introduces a novel application of Large Language Models (LLMs) to address the challenge of generating actionable plans in such settings, specifically within the context of the RoboCup Standard Platform League (SPL) competitions where robots are required to autonomously execute soccer strategies that emerge from the interactions of individual agents. In particular, we propose a multi-role approach leveraging the capabilities of LLMs to generate and refine plans for a robotic soccer team. The potential of the proposed method is demonstrated through an experimental evaluation,carried out simulating multiple matches where robots with AI-generated plans play against robots running human-built code.
LLM Based Multi-Agent Generation of Semi-structured Documents from Semantic Templates in the Public Administration Domain
Feb 21, 2024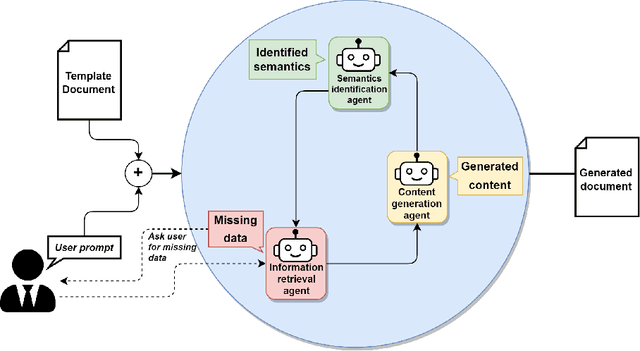

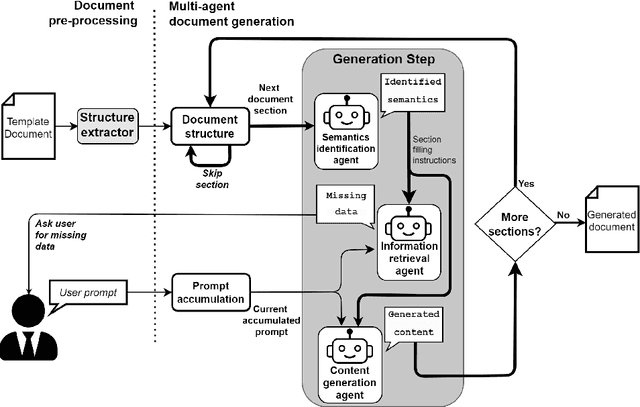

In the last years' digitalization process, the creation and management of documents in various domains, particularly in Public Administration (PA), have become increasingly complex and diverse. This complexity arises from the need to handle a wide range of document types, often characterized by semi-structured forms. Semi-structured documents present a fixed set of data without a fixed format. As a consequence, a template-based solution cannot be used, as understanding a document requires the extraction of the data structure. The recent introduction of Large Language Models (LLMs) has enabled the creation of customized text output satisfying user requests. In this work, we propose a novel approach that combines the LLMs with prompt engineering and multi-agent systems for generating new documents compliant with a desired structure. The main contribution of this work concerns replacing the commonly used manual prompting with a task description generated by semantic retrieval from an LLM. The potential of this approach is demonstrated through a series of experiments and case studies, showcasing its effectiveness in real-world PA scenarios.
MARIO: Modular and Extensible Architecture for Computing Visual Statistics in RoboCup SPL
Sep 20, 2022
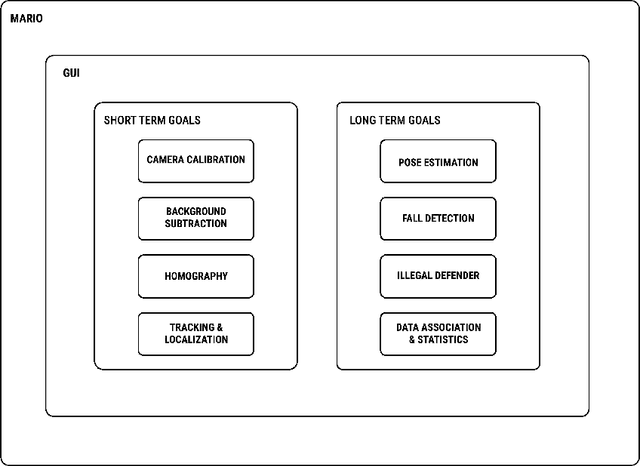


This technical report describes a modular and extensible architecture for computing visual statistics in RoboCup SPL (MARIO), presented during the SPL Open Research Challenge at RoboCup 2022, held in Bangkok (Thailand). MARIO is an open-source, ready-to-use software application whose final goal is to contribute to the growth of the RoboCup SPL community. MARIO comes with a GUI that integrates multiple machine learning and computer vision based functions, including automatic camera calibration, background subtraction, homography computation, player + ball tracking and localization, NAO robot pose estimation and fall detection. MARIO has been ranked no. 1 in the Open Research Challenge.