 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Local Causal World Models with State Space Models and Attention
May 04, 2025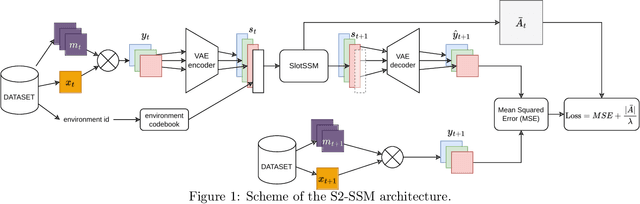



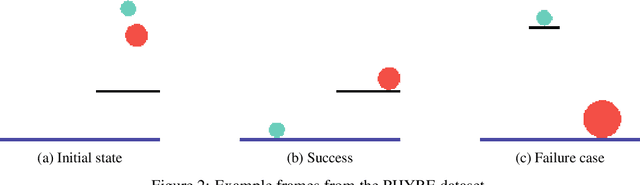
World modelling, i.e. building a representation of the rules that govern the world so as to predict its evolution, is an essential ability for any agent interacting with the physical world. Despite their impressive performance, many solutions fail to learn a causal representation of the environment they are trying to model, which would be necessary to gain a deep enough understanding of the world to perform complex tasks. With this work, we aim to broaden the research in the intersection of causality theory and neural world modelling by assessing the potential for causal discovery of the State Space Model (SSM) architecture, which has been shown to have several advantages over the widespread Transformer. We show empirically that, compared to an equivalent Transformer, a SSM can model the dynamics of a simple environment and learn a causal model at the same time with equivalent or better performance, thus paving the way for further experiments that lean into the strength of SSMs and further enhance them with causal awareness.
Real-Time Multimodal Signal Processing for HRI in RoboCup: Understanding a Human Referee
Nov 26, 2024


Advancing human-robot communication is crucial for autonomous systems operating in dynamic environments, where accurate real-time interpretation of human signals is essential. RoboCup provides a compelling scenario for testing these capabilities, requiring robots to understand referee gestures and whistle with minimal network reliance. Using the NAO robot platform, this study implements a two-stage pipeline for gesture recognition through keypoint extraction and classification, alongside continuous convolutional neural networks (CCNNs) for efficient whistle detection. The proposed approach enhances real-time human-robot interaction in a competitive setting like RoboCup, offering some tools to advance the development of autonomous systems capable of cooperating with humans.
Transformers and Slot Encoding for Sample Efficient Physical World Modelling
May 30, 2024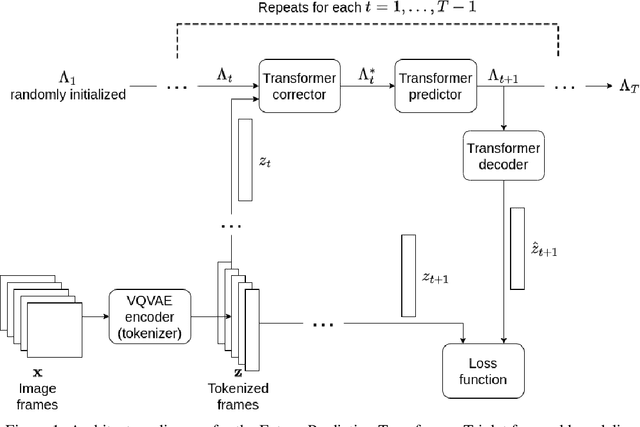


World modelling, i.e. building a representation of the rules that govern the world so as to predict its evolution, is an essential ability for any agent interacting with the physical world. Recent applications of the Transformer architecture to the problem of world modelling from video input show notable improvements in sample efficiency. However, existing approaches tend to work only at the image level thus disregarding that the environment is composed of objects interacting with each other. In this paper, we propose an architecture combining Transformers for world modelling with the slot-attention paradigm, an approach for learning representations of objects appearing in a scene. We describe the resulting neural architecture and report experimental results showing an improvement over the existing solutions in terms of sample efficiency and a reduction of the variation of the performance over the training examples. The code for our architecture and experiments is available at https://github.com/torchipeppo/transformers-and-slot-encoding-for-wm