 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Local Causal World Models with State Space Models and Attention
May 04, 2025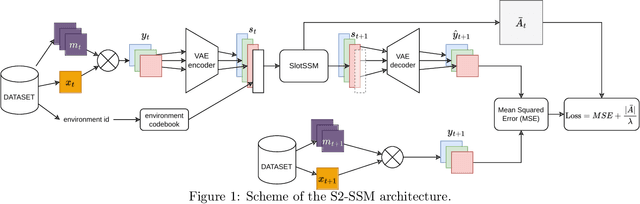



World modelling, i.e. building a representation of the rules that govern the world so as to predict its evolution, is an essential ability for any agent interacting with the physical world. Despite their impressive performance, many solutions fail to learn a causal representation of the environment they are trying to model, which would be necessary to gain a deep enough understanding of the world to perform complex tasks. With this work, we aim to broaden the research in the intersection of causality theory and neural world modelling by assessing the potential for causal discovery of the State Space Model (SSM) architecture, which has been shown to have several advantages over the widespread Transformer. We show empirically that, compared to an equivalent Transformer, a SSM can model the dynamics of a simple environment and learn a causal model at the same time with equivalent or better performance, thus paving the way for further experiments that lean into the strength of SSMs and further enhance them with causal awareness.
Transformers and Slot Encoding for Sample Efficient Physical World Modelling
May 30, 2024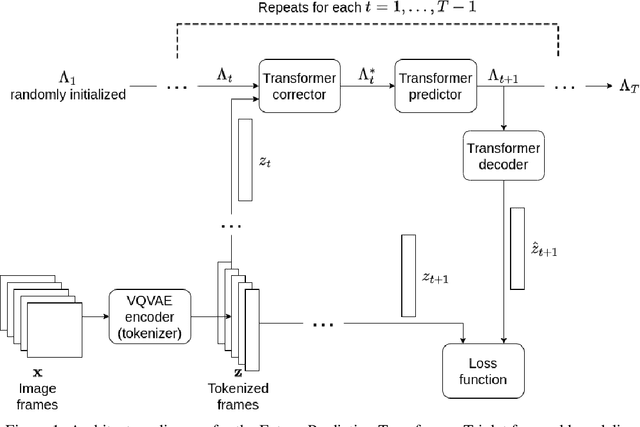
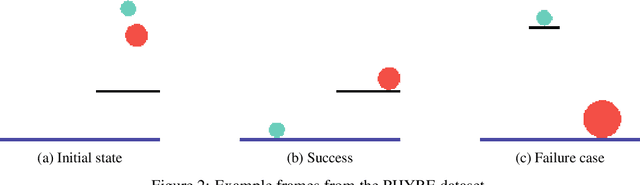


World modelling, i.e. building a representation of the rules that govern the world so as to predict its evolution, is an essential ability for any agent interacting with the physical world. Recent applications of the Transformer architecture to the problem of world modelling from video input show notable improvements in sample efficiency. However, existing approaches tend to work only at the image level thus disregarding that the environment is composed of objects interacting with each other. In this paper, we propose an architecture combining Transformers for world modelling with the slot-attention paradigm, an approach for learning representations of objects appearing in a scene. We describe the resulting neural architecture and report experimental results showing an improvement over the existing solutions in terms of sample efficiency and a reduction of the variation of the performance over the training examples. The code for our architecture and experiments is available at https://github.com/torchipeppo/transformers-and-slot-encoding-for-wm
Pattern-based Visualization of Knowledge Graphs
Jun 24, 2021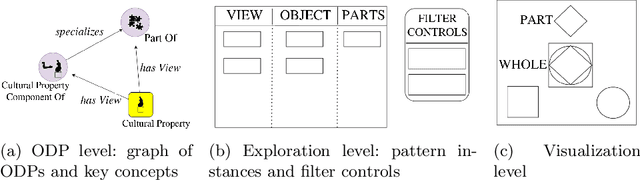
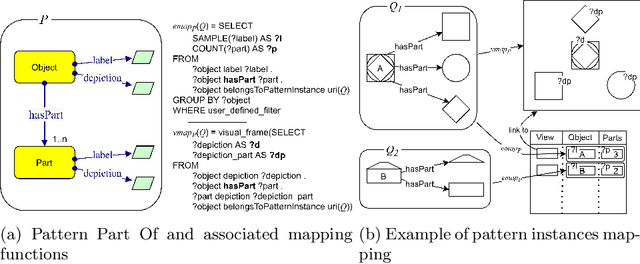

We present a novel approach to knowledge graph visualization based on ontology design patterns. This approach relies on OPLa (Ontology Pattern Language) annotations and on a catalogue of visual frames, which are associated with foundational ontology design patterns. We demonstrate that this approach significantly reduces the cognitive load required to users for visualizing and interpreting a knowledge graph and guides the user in exploring it through meaningful thematic paths provided by ontology patterns.
Extraction of common conceptual components from multiple ontologies
Jun 24, 2021
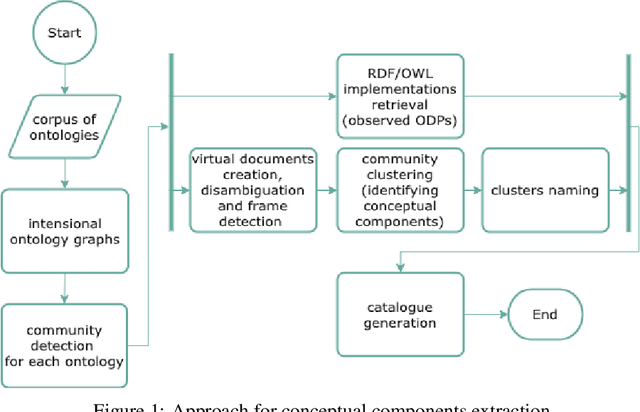
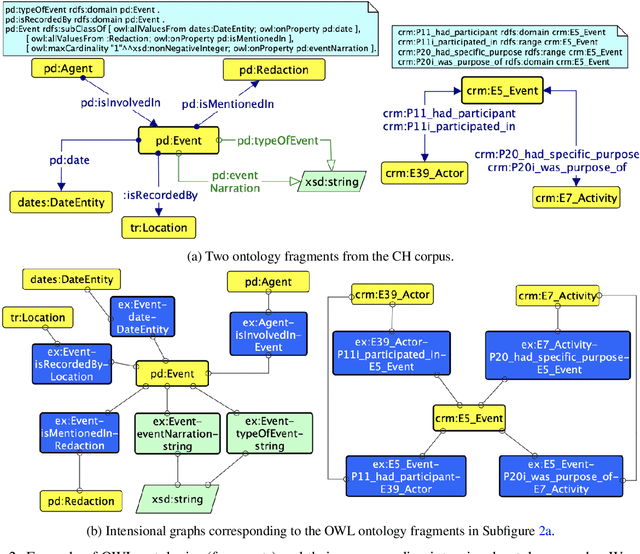

We describe a novel method for identifying and extracting conceptual components from domain ontologies, which are used to understand and compare them. The method is applied to two corpora of ontologies in the Cultural Heritage and Conference domain, respectively. The results, which show good quality, are evaluated by manual inspection and by correlation with datasets and tool performance from the ontology alignment evaluation initiative.
Facade-X: an opinionated approach to SPARQL anything
Jun 04, 2021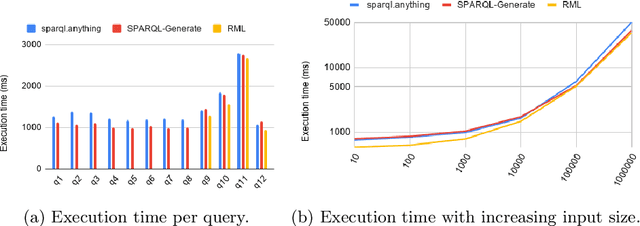

The Semantic Web research community understood since its beginning how crucial it is to equip practitioners with methods to transform non-RDF resources into RDF. Proposals focus on either engineering content transformations or accessing non-RDF resources with SPARQL. Existing solutions require users to learn specific mapping languages (e.g. RML), to know how to query and manipulate a variety of source formats (e.g. XPATH, JSON-Path), or to combine multiple languages (e.g. SPARQL Generate). In this paper, we explore an alternative solution and contribute a general-purpose meta-model for converting non-RDF resources into RDF: Facade-X. Our approach can be implemented by overriding the SERVICE operator and does not require to extend the SPARQL syntax. We compare our approach with the state of art methods RML and SPARQL Generate and show how our solution has lower learning demands and cognitive complexity, and it is cheaper to implement and maintain, while having comparable extensibility and efficiency.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020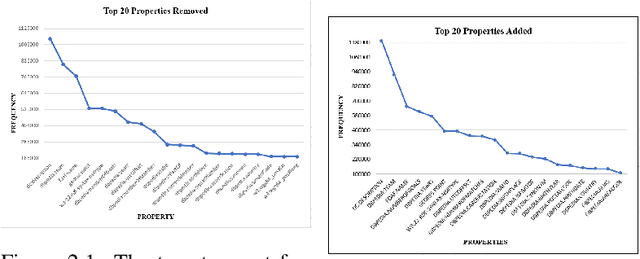
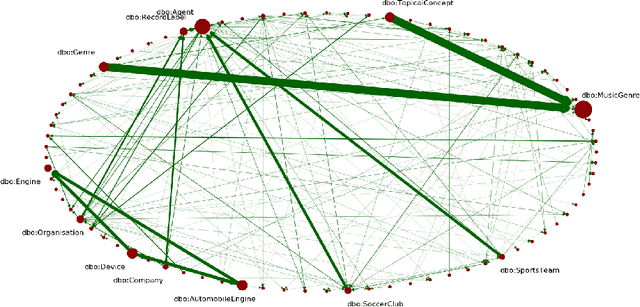

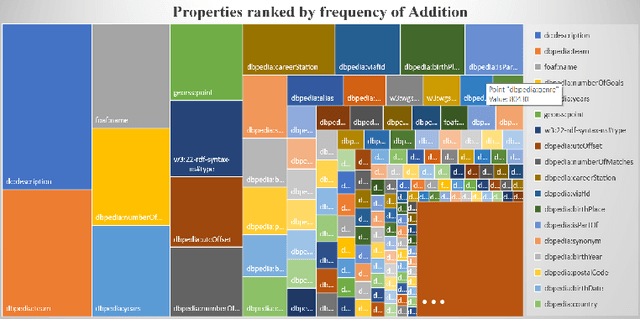
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.
A Reference Software Architecture for Social Robots
Jul 09, 2020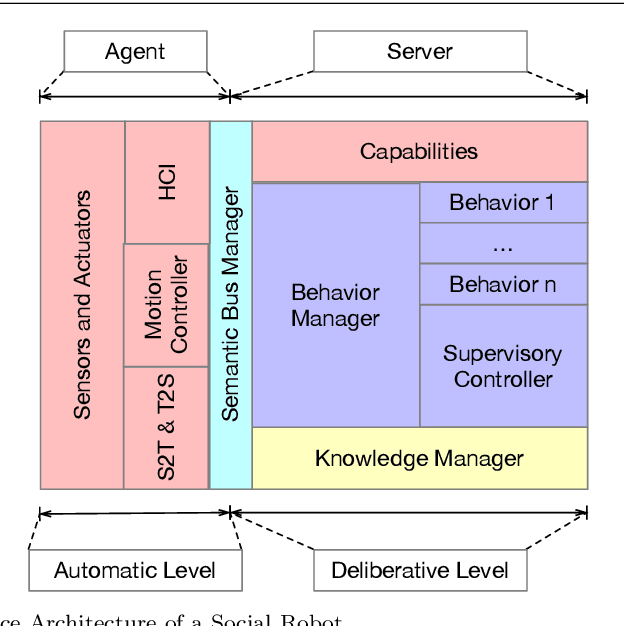
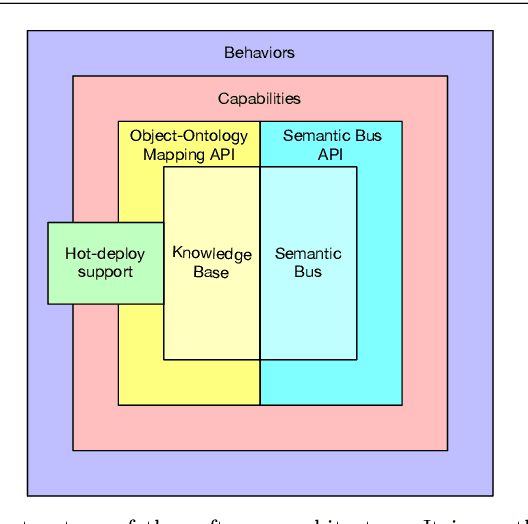
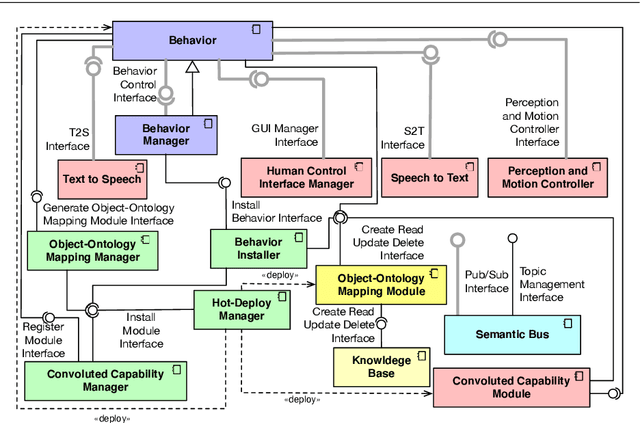
Social Robotics poses tough challenges to software designers who are required to take care of difficult architectural drivers like acceptability, trust of robots as well as to guarantee that robots establish a personalised interaction with their users. Moreover, in this context recurrent software design issues such as ensuring interoperability, improving reusability and customizability of software components also arise. Designing and implementing social robotic software architectures is a time-intensive activity requiring multi-disciplinary expertise: this makes difficult to rapidly develop, customise, and personalise robotic solutions. These challenges may be mitigated at design time by choosing certain architectural styles, implementing specific architectural patterns and using particular technologies. Leveraging on our experience in the MARIO project, in this paper we propose a series of principles that social robots may benefit from. These principles lay also the foundations for the design of a reference software architecture for Social Robots. The ultimate goal of this work is to establish a common ground based on a reference software architecture to allow to easily reuse robotic software components in order to rapidly develop, implement, and personalise Social Robots.
Observing LOD using Equivalent Set Graphs: it is mostly flat and sparsely linked
Jul 18, 2019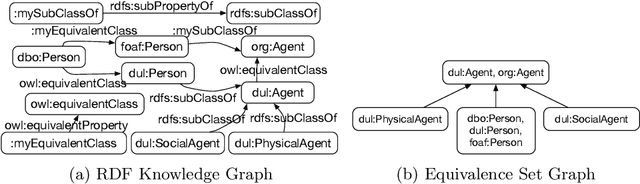
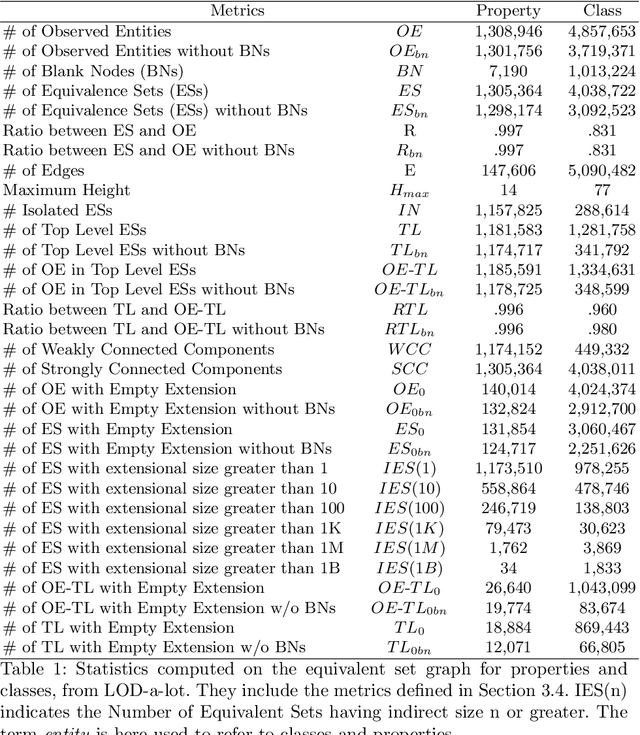
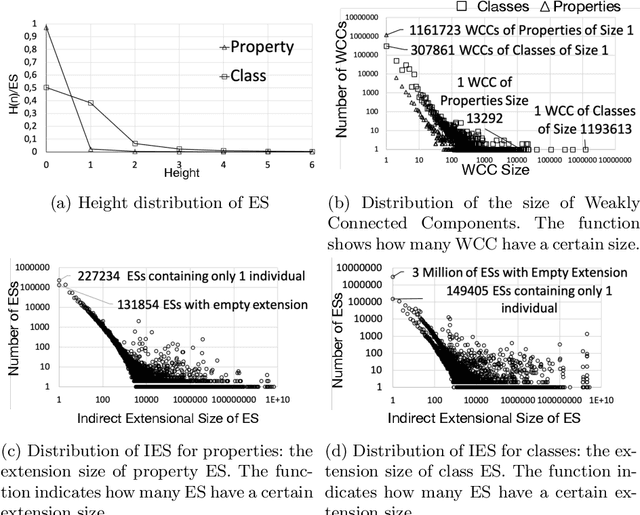
This paper presents an empirical study aiming at understanding the modeling style and the overall semantic structure of Linked Open Data. We observe how classes, properties and individuals are used in practice. We also investigate how hierarchies of concepts are structured, and how much they are linked. In addition to discussing the results, this paper contributes (i) a conceptual framework, including a set of metrics, which generalises over the observable constructs; (ii) an open source implementation that facilitates its application to other Linked Data knowledge graphs.
Empirical Analysis of Foundational Distinctions in Linked Open Data
May 23, 2018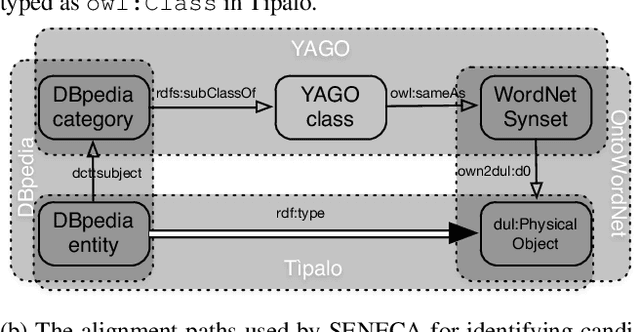
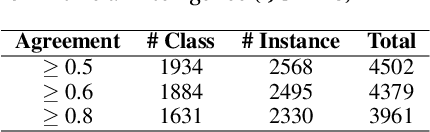

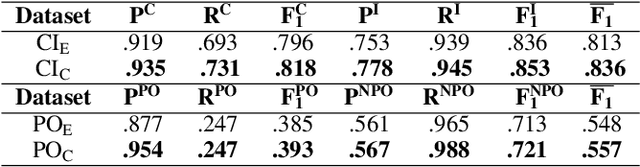
The Web and its Semantic extension (i.e. Linked Open Data) contain open global-scale knowledge and make it available to potentially intelligent machines that want to benefit from it. Nevertheless, most of Linked Open Data lack ontological distinctions and have sparse axiomatisation. For example, distinctions such as whether an entity is inherently a class or an individual, or whether it is a physical object or not, are hardly expressed in the data, although they have been largely studied and formalised by foundational ontologies (e.g. DOLCE, SUMO). These distinctions belong to common sense too, which is relevant for many artificial intelligence tasks such as natural language understanding, scene recognition, and the like. There is a gap between foundational ontologies, that often formalise or are inspired by pre-existing philosophical theories and are developed with a top-down approach, and Linked Open Data that mostly derive from existing databases or crowd-based effort (e.g. DBpedia, Wikidata). We investigate whether machines can learn foundational distinctions over Linked Open Data entities, and if they match common sense. We want to answer questions such as "does the DBpedia entity for dog refer to a class or to an instance?". We report on a set of experiments based on machine learning and crowdsourcing that show promising results.