 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an Operational Responsible AI Framework for Learning Analytics in Higher Education
Oct 08, 2024Universities are increasingly adopting data-driven strategies to enhance student success, with AI applications like Learning Analytics (LA) and Predictive Learning Analytics (PLA) playing a key role in identifying at-risk students, personalising learning, supporting teachers, and guiding educational decision-making. However, concerns are rising about potential harms these systems may pose, such as algorithmic biases leading to unequal support for minority students. While many have explored the need for Responsible AI in LA, existing works often lack practical guidance for how institutions can operationalise these principles. In this paper, we propose a novel Responsible AI framework tailored specifically to LA in Higher Education (HE). We started by mapping 11 established Responsible AI frameworks, including those by leading tech companies, to the context of LA in HE. This led to the identification of seven key principles such as transparency, fairness, and accountability. We then conducted a systematic review of the literature to understand how these principles have been applied in practice. Drawing from these findings, we present a novel framework that offers practical guidance to HE institutions and is designed to evolve with community input, ensuring its relevance as LA systems continue to develop.
Facade-X: an opinionated approach to SPARQL anything
Jun 04, 2021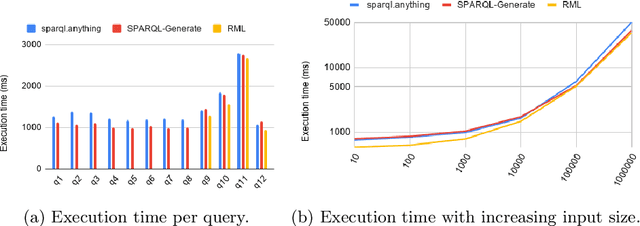

The Semantic Web research community understood since its beginning how crucial it is to equip practitioners with methods to transform non-RDF resources into RDF. Proposals focus on either engineering content transformations or accessing non-RDF resources with SPARQL. Existing solutions require users to learn specific mapping languages (e.g. RML), to know how to query and manipulate a variety of source formats (e.g. XPATH, JSON-Path), or to combine multiple languages (e.g. SPARQL Generate). In this paper, we explore an alternative solution and contribute a general-purpose meta-model for converting non-RDF resources into RDF: Facade-X. Our approach can be implemented by overriding the SERVICE operator and does not require to extend the SPARQL syntax. We compare our approach with the state of art methods RML and SPARQL Generate and show how our solution has lower learning demands and cognitive complexity, and it is cheaper to implement and maintain, while having comparable extensibility and efficiency.