 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacade-X: an opinionated approach to SPARQL anything
Jun 04, 2021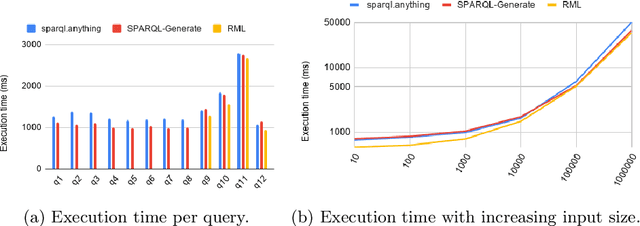

The Semantic Web research community understood since its beginning how crucial it is to equip practitioners with methods to transform non-RDF resources into RDF. Proposals focus on either engineering content transformations or accessing non-RDF resources with SPARQL. Existing solutions require users to learn specific mapping languages (e.g. RML), to know how to query and manipulate a variety of source formats (e.g. XPATH, JSON-Path), or to combine multiple languages (e.g. SPARQL Generate). In this paper, we explore an alternative solution and contribute a general-purpose meta-model for converting non-RDF resources into RDF: Facade-X. Our approach can be implemented by overriding the SERVICE operator and does not require to extend the SPARQL syntax. We compare our approach with the state of art methods RML and SPARQL Generate and show how our solution has lower learning demands and cognitive complexity, and it is cheaper to implement and maintain, while having comparable extensibility and efficiency.
Commonsense Spatial Reasoning for Visually Intelligent Agents
Apr 01, 2021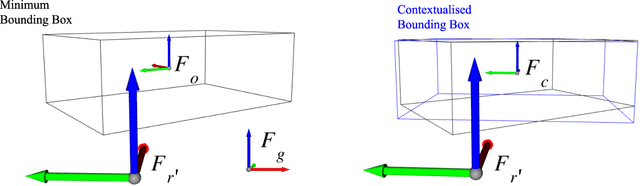
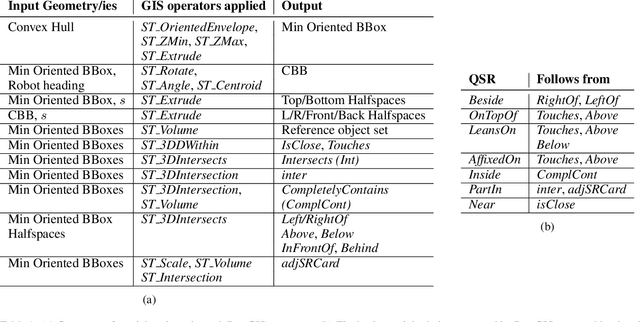
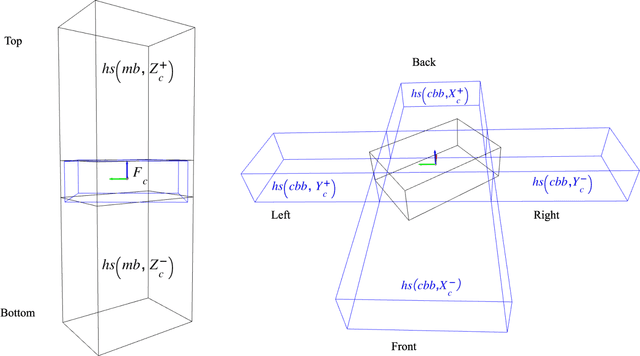
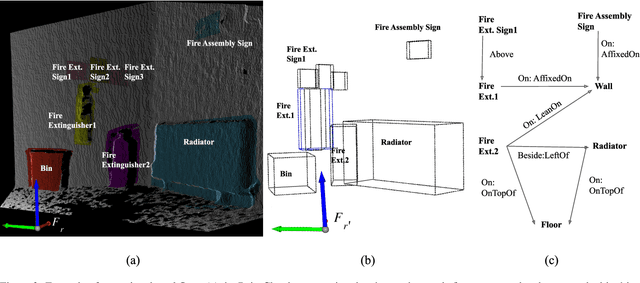
Service robots are expected to reliably make sense of complex, fast-changing environments. From a cognitive standpoint, they need the appropriate reasoning capabilities and background knowledge required to exhibit human-like Visual Intelligence. In particular, our prior work has shown that the ability to reason about spatial relations between objects in the world is a key requirement for the development of Visually Intelligent Agents. In this paper, we present a framework for commonsense spatial reasoning which is tailored to real-world robotic applications. Differently from prior approaches to qualitative spatial reasoning, the proposed framework is robust to variations in the robot's viewpoint and object orientation. The spatial relations in the proposed framework are also mapped to the types of commonsense predicates used to describe typical object configurations in English. In addition, we also show how this formally-defined framework can be implemented in a concrete spatial database.
Fit to Measure: Reasoning about Sizes for Robust Object Recognition
Oct 27, 2020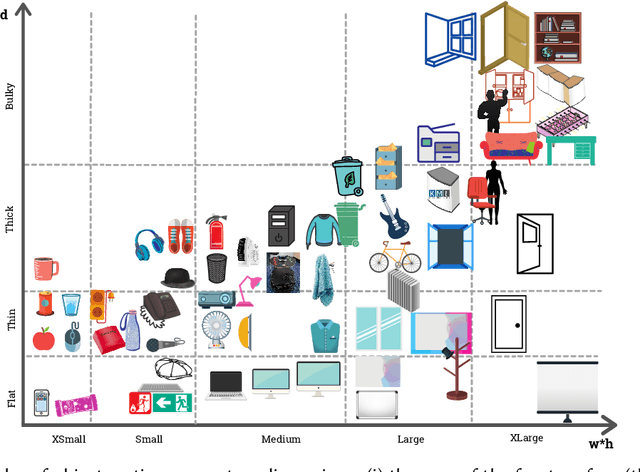

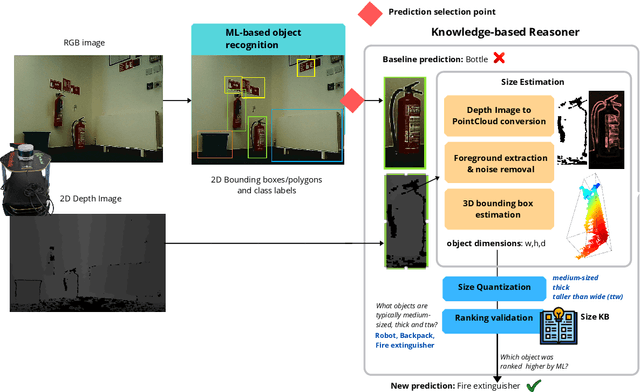
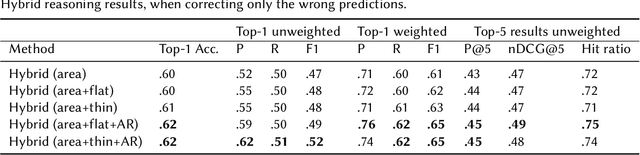
Service robots can help with many of our daily tasks, especially in those cases where it is inconvenient or unsafe for us to intervene: e.g., under extreme weather conditions or when social distance needs to be maintained. However, before we can successfully delegate complex tasks to robots, we need to enhance their ability to make sense of dynamic, real world environments. In this context, the first prerequisite to improving the Visual Intelligence of a robot is building robust and reliable object recognition systems. While object recognition solutions are traditionally based on Machine Learning methods, augmenting them with knowledge based reasoners has been shown to improve their performance. In particular, based on our prior work on identifying the epistemic requirements of Visual Intelligence, we hypothesise that knowledge of the typical size of objects could significantly improve the accuracy of an object recognition system. To verify this hypothesis, in this paper we present an approach to integrating knowledge about object sizes in a ML based architecture. Our experiments in a real world robotic scenario show that this combined approach ensures a significant performance increase over state of the art Machine Learning methods.
Towards a Framework for Visual Intelligence in Service Robotics: Epistemic Requirements and Gap Analysis
Mar 13, 2020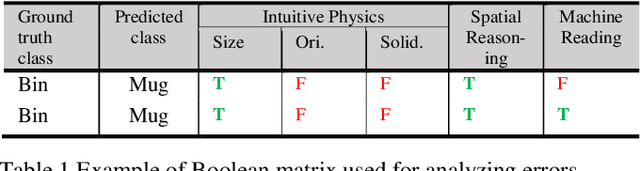
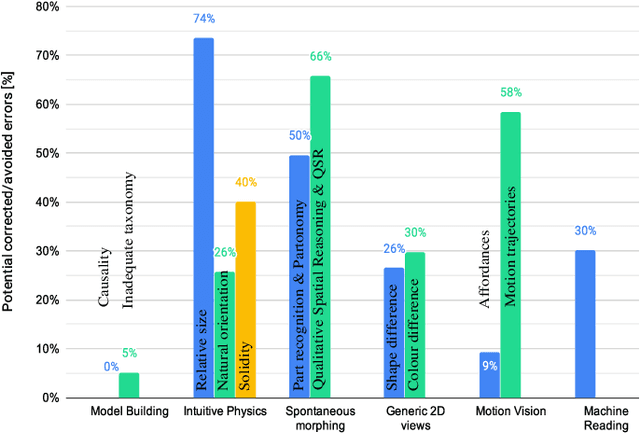
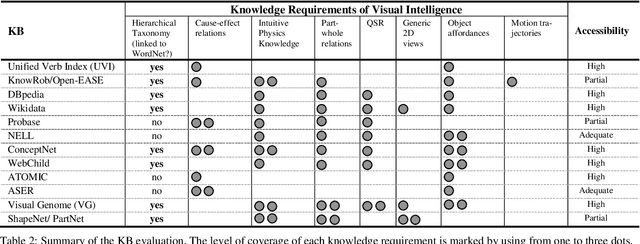
A key capability required by service robots operating in real-world, dynamic environments is that of Visual Intelligence, i.e., the ability to use their vision system, reasoning components and background knowledge to make sense of their environment. In this paper, we analyze the epistemic requirements for Visual Intelligence, both in a top-down fashion, using existing frameworks for human-like Visual Intelligence in the literature, and from the bottom up, based on the errors emerging from object recognition trials in a real-world robotic scenario. Finally, we use these requirements to evaluate current knowledge bases for Service Robotics and to identify gaps in the support they provide for Visual Intelligence. These gaps provide the basis of a research agenda for developing more effective knowledge representations for Visual Intelligence.