 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBTGenBot-2: Efficient Behavior Tree Generation with Small Language Models
Feb 02, 2026Recent advances in robot learning increasingly rely on LLM-based task planning, leveraging their ability to bridge natural language with executable actions. While prior works showcased great performances, the widespread adoption of these models in robotics has been challenging as 1) existing methods are often closed-source or computationally intensive, neglecting the actual deployment on real-world physical systems, and 2) there is no universally accepted, plug-and-play representation for robotic task generation. Addressing these challenges, we propose BTGenBot-2, a 1B-parameter open-source small language model that directly converts natural language task descriptions and a list of robot action primitives into executable behavior trees in XML. Unlike prior approaches, BTGenBot-2 enables zero-shot BT generation, error recovery at inference and runtime, while remaining lightweight enough for resource-constrained robots. We further introduce the first standardized benchmark for LLM-based BT generation, covering 52 navigation and manipulation tasks in NVIDIA Isaac Sim. Extensive evaluations demonstrate that BTGenBot-2 consistently outperforms GPT-5, Claude Opus 4.1, and larger open-source models across both functional and non-functional metrics, achieving average success rates of 90.38% in zero-shot and 98.07% in one-shot, while delivering up to 16x faster inference compared to the previous BTGenBot.
Improving Robustness of Vision-Language-Action Models by Restoring Corrupted Visual Inputs
Feb 01, 2026Vision-Language-Action (VLA) models have emerged as a dominant paradigm for generalist robotic manipulation, unifying perception and control within a single end-to-end architecture. However, despite their success in controlled environments, reliable real-world deployment is severely hindered by their fragility to visual disturbances. While existing literature extensively addresses physical occlusions caused by scene geometry, a critical mode remains largely unexplored: image corruptions. These sensor-level artifacts, ranging from electronic noise and dead pixels to lens contaminants, directly compromise the integrity of the visual signal prior to interpretation. In this work, we quantify this vulnerability, demonstrating that state-of-the-art VLAs such as $π_{0.5}$ and SmolVLA, suffer catastrophic performance degradation, dropping from 90\% success rates to as low as 2\%, under common signal artifacts. To mitigate this, we introduce the Corruption Restoration Transformer (CRT), a plug-and-play and model-agnostic vision transformer designed to immunize VLA models against sensor disturbances. Leveraging an adversarial training objective, CRT restores clean observations from corrupted inputs without requiring computationally expensive fine-tuning of the underlying model. Extensive experiments across the LIBERO and Meta-World benchmarks demonstrate that CRT effectively recovers lost performance, enabling VLAs to maintain near-baseline success rates, even under severe visual corruption.
BTGenBot: Behavior Tree Generation for Robotic Tasks with Lightweight LLMs
Mar 19, 2024



This paper presents a novel approach to generating behavior trees for robots using lightweight large language models (LLMs) with a maximum of 7 billion parameters. The study demonstrates that it is possible to achieve satisfying results with compact LLMs when fine-tuned on a specific dataset. The key contributions of this research include the creation of a fine-tuning dataset based on existing behavior trees using GPT-3.5 and a comprehensive comparison of multiple LLMs (namely llama2, llama-chat, and code-llama) across nine distinct tasks. To be thorough, we evaluated the generated behavior trees using static syntactical analysis, a validation system, a simulated environment, and a real robot. Furthermore, this work opens the possibility of deploying such solutions directly on the robot, enhancing its practical applicability. Findings from this study demonstrate the potential of LLMs with a limited number of parameters in generating effective and efficient robot behaviors.
Commonsense Spatial Reasoning for Visually Intelligent Agents
Apr 01, 2021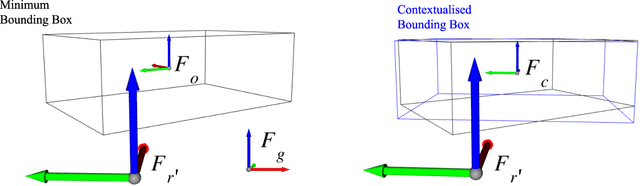
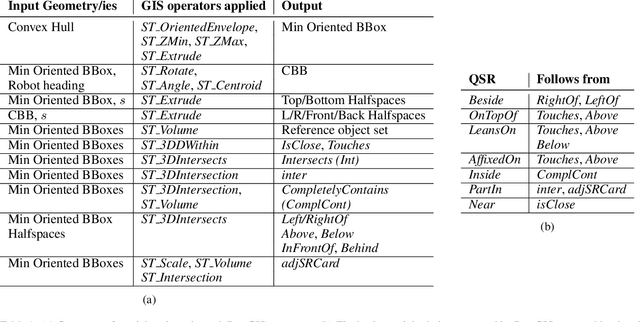
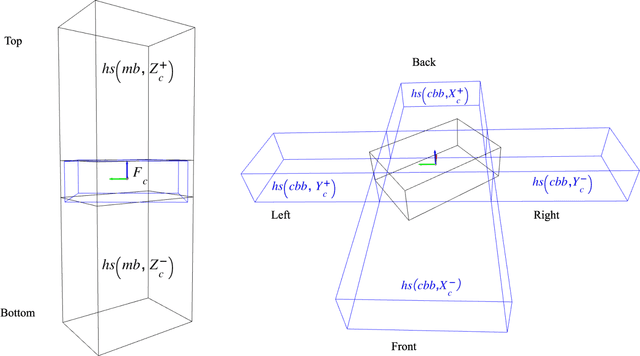
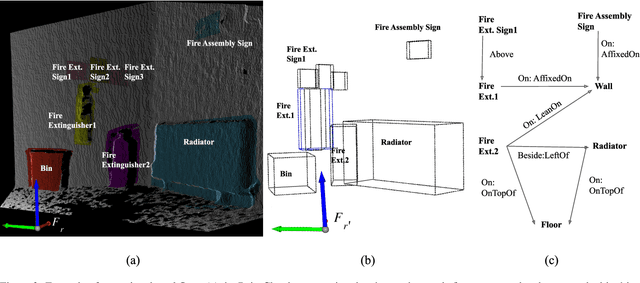
Service robots are expected to reliably make sense of complex, fast-changing environments. From a cognitive standpoint, they need the appropriate reasoning capabilities and background knowledge required to exhibit human-like Visual Intelligence. In particular, our prior work has shown that the ability to reason about spatial relations between objects in the world is a key requirement for the development of Visually Intelligent Agents. In this paper, we present a framework for commonsense spatial reasoning which is tailored to real-world robotic applications. Differently from prior approaches to qualitative spatial reasoning, the proposed framework is robust to variations in the robot's viewpoint and object orientation. The spatial relations in the proposed framework are also mapped to the types of commonsense predicates used to describe typical object configurations in English. In addition, we also show how this formally-defined framework can be implemented in a concrete spatial database.
Fit to Measure: Reasoning about Sizes for Robust Object Recognition
Oct 27, 2020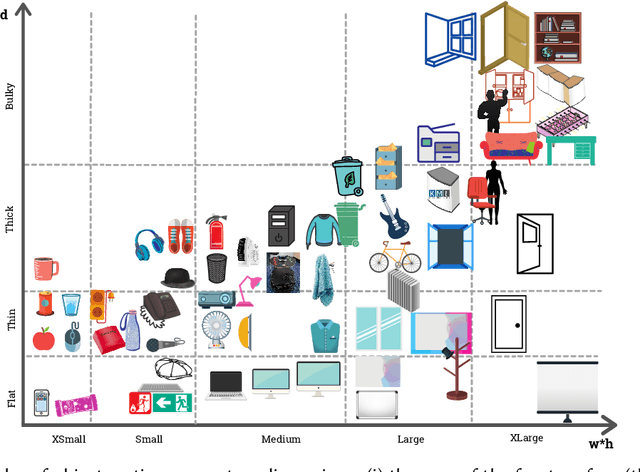

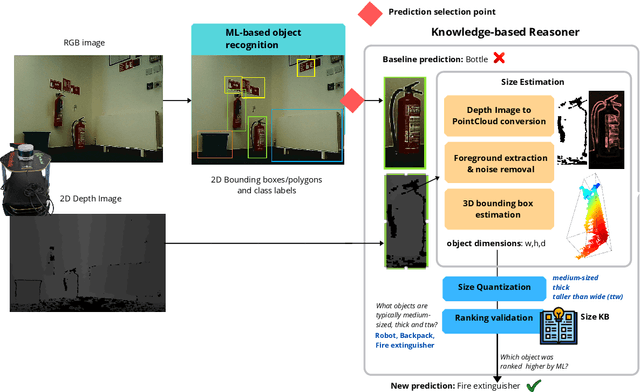
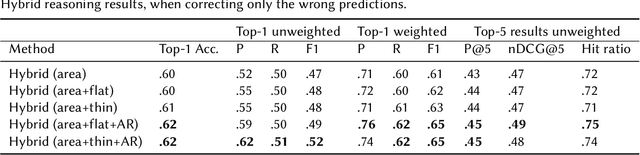
Service robots can help with many of our daily tasks, especially in those cases where it is inconvenient or unsafe for us to intervene: e.g., under extreme weather conditions or when social distance needs to be maintained. However, before we can successfully delegate complex tasks to robots, we need to enhance their ability to make sense of dynamic, real world environments. In this context, the first prerequisite to improving the Visual Intelligence of a robot is building robust and reliable object recognition systems. While object recognition solutions are traditionally based on Machine Learning methods, augmenting them with knowledge based reasoners has been shown to improve their performance. In particular, based on our prior work on identifying the epistemic requirements of Visual Intelligence, we hypothesise that knowledge of the typical size of objects could significantly improve the accuracy of an object recognition system. To verify this hypothesis, in this paper we present an approach to integrating knowledge about object sizes in a ML based architecture. Our experiments in a real world robotic scenario show that this combined approach ensures a significant performance increase over state of the art Machine Learning methods.