 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFit to Measure: Reasoning about Sizes for Robust Object Recognition
Paper and Code
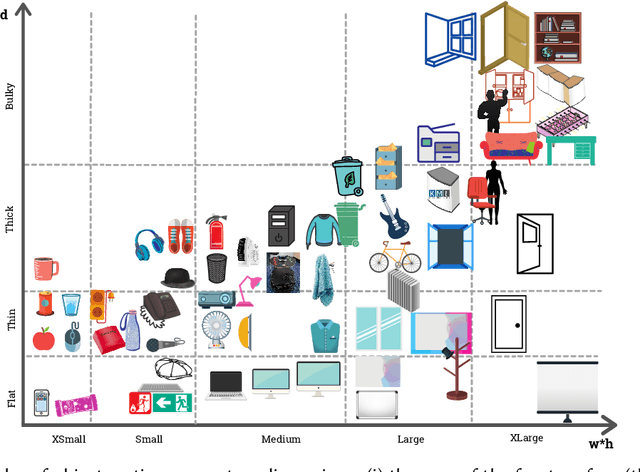

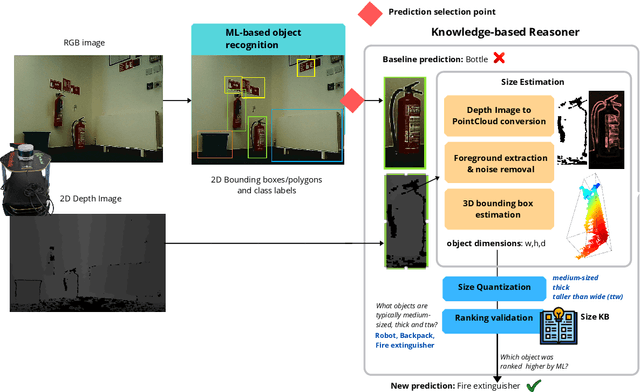
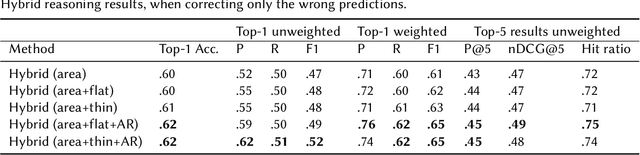
Service robots can help with many of our daily tasks, especially in those cases where it is inconvenient or unsafe for us to intervene: e.g., under extreme weather conditions or when social distance needs to be maintained. However, before we can successfully delegate complex tasks to robots, we need to enhance their ability to make sense of dynamic, real world environments. In this context, the first prerequisite to improving the Visual Intelligence of a robot is building robust and reliable object recognition systems. While object recognition solutions are traditionally based on Machine Learning methods, augmenting them with knowledge based reasoners has been shown to improve their performance. In particular, based on our prior work on identifying the epistemic requirements of Visual Intelligence, we hypothesise that knowledge of the typical size of objects could significantly improve the accuracy of an object recognition system. To verify this hypothesis, in this paper we present an approach to integrating knowledge about object sizes in a ML based architecture. Our experiments in a real world robotic scenario show that this combined approach ensures a significant performance increase over state of the art Machine Learning methods.