 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBench4KE: Benchmarking Automated Competency Question Generation
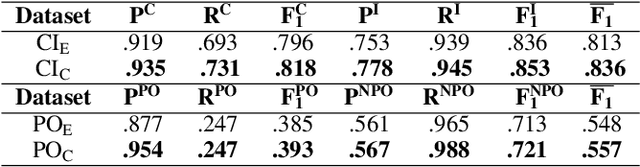
May 30, 2025The availability of Large Language Models (LLMs) presents a unique opportunity to reinvigorate research on Knowledge Engineering (KE) automation, a trend already evident in recent efforts developing LLM-based methods and tools for the automatic generation of Competency Questions (CQs). However, the evaluation of these tools lacks standardisation. This undermines the methodological rigour and hinders the replication and comparison of results. To address this gap, we introduce Bench4KE, an extensible API-based benchmarking system for KE automation. Its first release focuses on evaluating tools that generate CQs automatically. CQs are natural language questions used by ontology engineers to define the functional requirements of an ontology. Bench4KE provides a curated gold standard consisting of CQ datasets from four real-world ontology projects. It uses a suite of similarity metrics to assess the quality of the CQs generated. We present a comparative analysis of four recent CQ generation systems, which are based on LLMs, establishing a baseline for future research. Bench4KE is also designed to accommodate additional KE automation tasks, such as SPARQL query generation, ontology testing and drafting. Code and datasets are publicly available under the Apache 2.0 license.
A Reference Software Architecture for Social Robots
Jul 09, 2020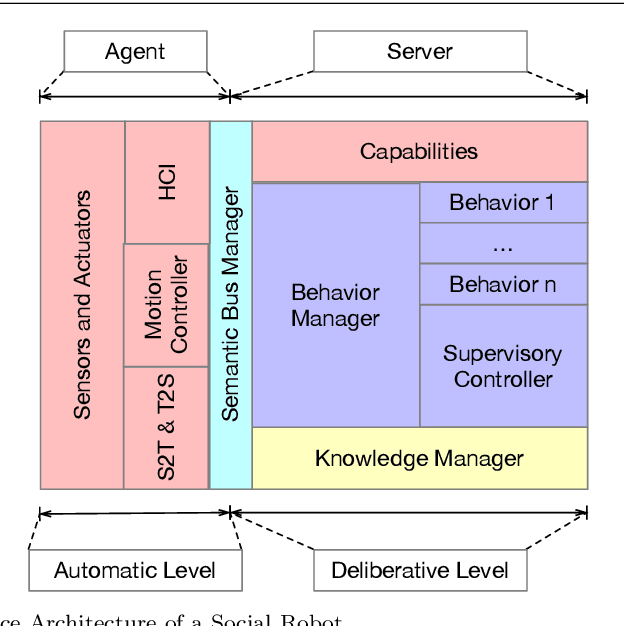
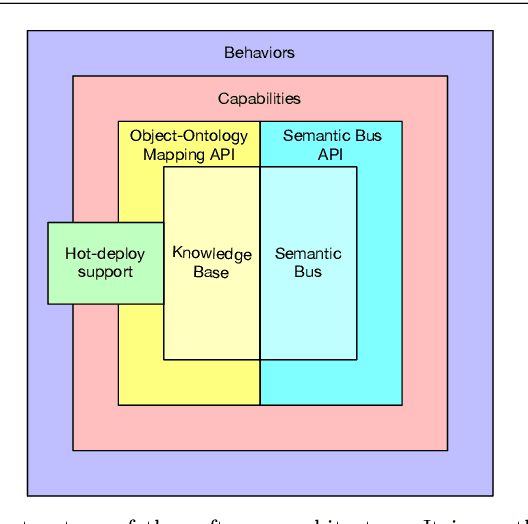
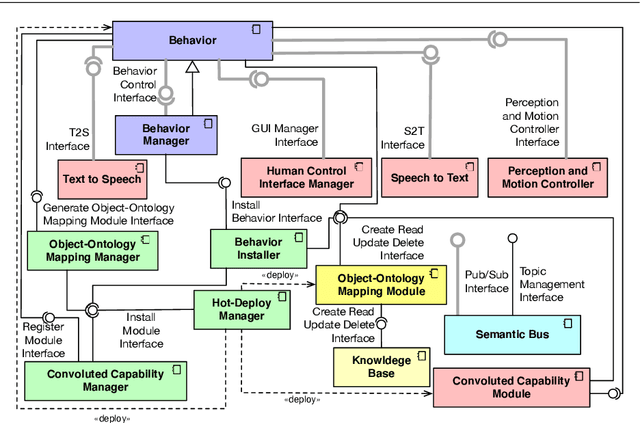
Social Robotics poses tough challenges to software designers who are required to take care of difficult architectural drivers like acceptability, trust of robots as well as to guarantee that robots establish a personalised interaction with their users. Moreover, in this context recurrent software design issues such as ensuring interoperability, improving reusability and customizability of software components also arise. Designing and implementing social robotic software architectures is a time-intensive activity requiring multi-disciplinary expertise: this makes difficult to rapidly develop, customise, and personalise robotic solutions. These challenges may be mitigated at design time by choosing certain architectural styles, implementing specific architectural patterns and using particular technologies. Leveraging on our experience in the MARIO project, in this paper we propose a series of principles that social robots may benefit from. These principles lay also the foundations for the design of a reference software architecture for Social Robots. The ultimate goal of this work is to establish a common ground based on a reference software architecture to allow to easily reuse robotic software components in order to rapidly develop, implement, and personalise Social Robots.
SQuAP-Ont: an Ontology of Software Quality Relational Factors from Financial Systems
Sep 04, 2019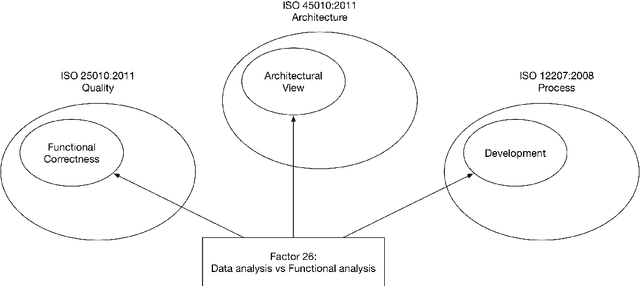

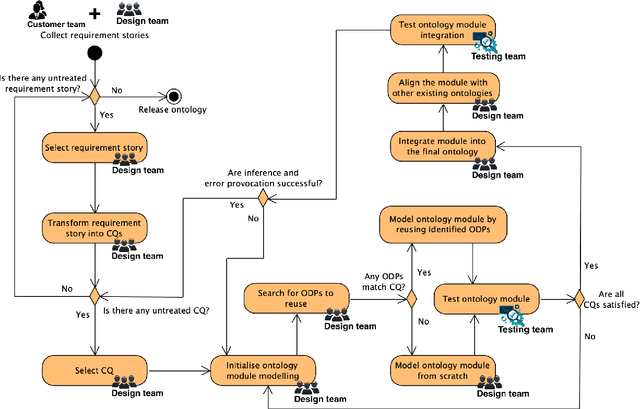
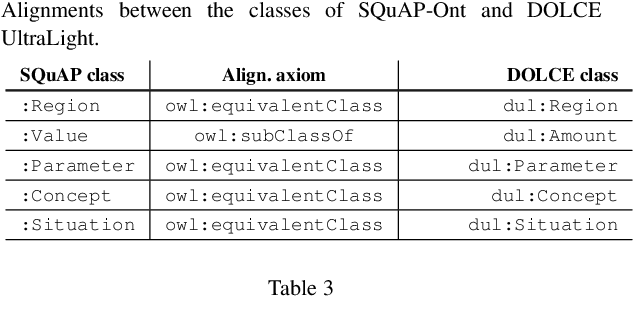
Quality, architecture, and process are considered the keystones of software engineering. ISO defines them in three separate standards. However, their interaction has been scarcely studied, so far. The SQuAP model (Software Quality, Architecture, Process) describes twenty-eight main factors that impact on software quality in banking systems, and each factor is described as a relation among some characteristics from the three ISO standards. Hence, SQuAP makes such relations emerge rigorously, although informally. In this paper, we present SQuAP-Ont, an OWL ontology designed by following a well-established methodology based on the re-use of Ontology Design Patterns (i.e. ODPs). SQuAP-Ont formalises the relations emerging from SQuAP to represent and reason via Linked Data about software engineering in a three-dimensional model consisting of quality, architecture, and process ISO characteristics.
Observing LOD using Equivalent Set Graphs: it is mostly flat and sparsely linked
Jul 18, 2019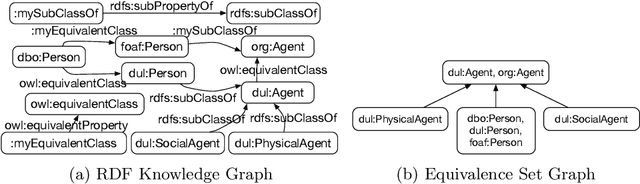
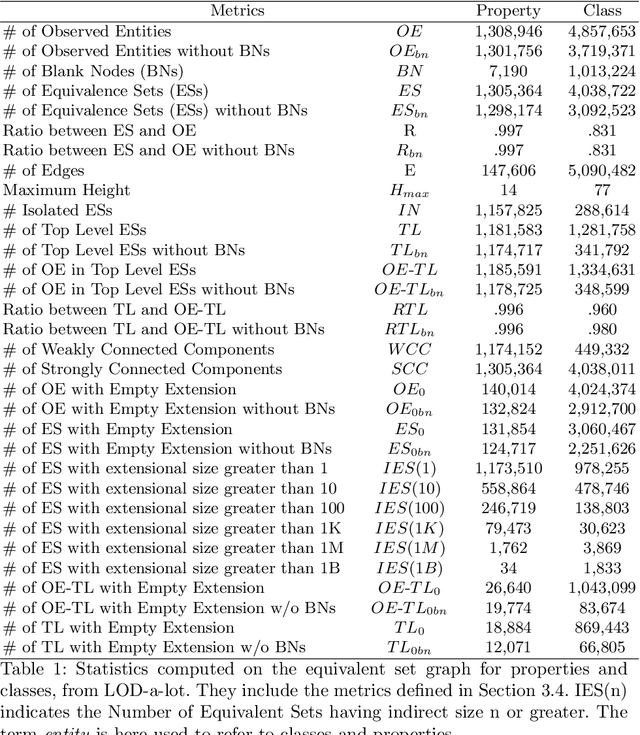
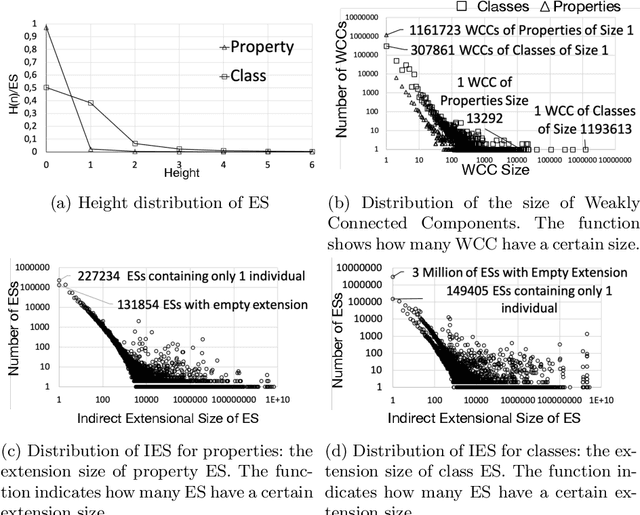
This paper presents an empirical study aiming at understanding the modeling style and the overall semantic structure of Linked Open Data. We observe how classes, properties and individuals are used in practice. We also investigate how hierarchies of concepts are structured, and how much they are linked. In addition to discussing the results, this paper contributes (i) a conceptual framework, including a set of metrics, which generalises over the observable constructs; (ii) an open source implementation that facilitates its application to other Linked Data knowledge graphs.
Empirical Analysis of Foundational Distinctions in Linked Open Data
May 23, 2018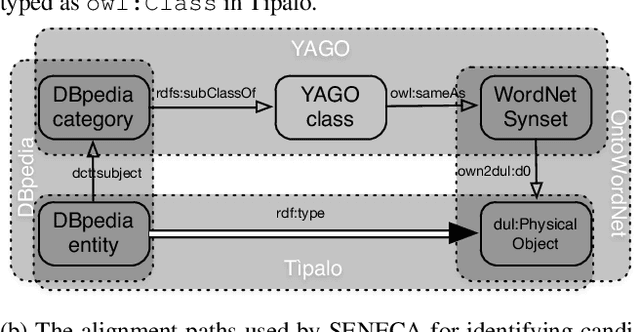
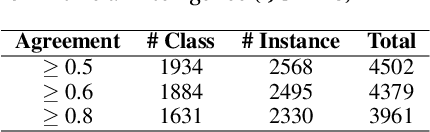

The Web and its Semantic extension (i.e. Linked Open Data) contain open global-scale knowledge and make it available to potentially intelligent machines that want to benefit from it. Nevertheless, most of Linked Open Data lack ontological distinctions and have sparse axiomatisation. For example, distinctions such as whether an entity is inherently a class or an individual, or whether it is a physical object or not, are hardly expressed in the data, although they have been largely studied and formalised by foundational ontologies (e.g. DOLCE, SUMO). These distinctions belong to common sense too, which is relevant for many artificial intelligence tasks such as natural language understanding, scene recognition, and the like. There is a gap between foundational ontologies, that often formalise or are inspired by pre-existing philosophical theories and are developed with a top-down approach, and Linked Open Data that mostly derive from existing databases or crowd-based effort (e.g. DBpedia, Wikidata). We investigate whether machines can learn foundational distinctions over Linked Open Data entities, and if they match common sense. We want to answer questions such as "does the DBpedia entity for dog refer to a class or to an instance?". We report on a set of experiments based on machine learning and crowdsourcing that show promising results.