 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Optimization in Hybrid Discrete-Continuous Action Spaces via Mixed Gradients
May 14, 2026We study reinforcement learning in hybrid discrete-continuous action spaces, such as settings where the discrete component selects a regime (or index) and the continuous component optimizes within it -- a structure common in robotics, control, and operations problems. Standard model-free policy gradient methods rely on score-function (SF) estimators and suffer from severe credit-assignment issues in high-dimensional settings, leading to poor gradient quality. On the other hand, differentiable simulation largely sidesteps these issues by backpropagating through a simulator, but the presence of discrete actions or non-smooth dynamics yields biased or uninformative gradients. To address this, we propose Hybrid Policy Optimization (HPO), which backpropagates through the simulator wherever smoothness permits, using a mixed gradient estimator that combines pathwise and SF gradients while maintaining unbiasedness. We also show how problems with action discontinuities can be reformulated in hybrid form, further broadening its applicability. Empirically, HPO substantially outperforms PPO on inventory control and switched linear-quadratic regulator problems, with performance gaps increasing as the continuous action dimension grows. Finally, we characterize the structure of the mixed gradient, showing that its cross term -- which captures how continuous actions influence future discrete decisions -- becomes negligible near a discrete best response, thereby enabling approximate decentralized updates of the continuous and discrete components and reducing variance near optimality. All resources are available at github.com/MatiasAlvo/hybrid-rl.
More Is Different: Toward a Theory of Emergence in AI-Native Software Ecosystems
Apr 20, 2026Software engineering faces a fundamental challenge: multi-agent AI systems fail in ways that defy explanation by traditional theories. While individual agents perform correctly, their interactions degrade entire ecosystems, revealing a gap in our understanding of software evolution. This paper argues that AI-native software ecosystems must be studied as complex adaptive systems (CAS), where emergent properties like architectural entropy, cascade failures, and comprehension debt arise not from individual components, but from their interactions. We map Holland's six CAS properties onto observable ecosystem dynamics, distinguishing these systems from microservices or open-source networks. To measure causal emergence, we define micro-level state variables, coarse-graining functions, and a tractable measurement framework. Seven falsifiable propositions link CAS theory to software evolution, challenging or extending Lehman's laws where agent-level assumptions fail. If confirmed, these findings would demand a radical shift: ecosystem-level monitoring as the primary governance mechanism for AI-native systems. If refuted, existing theories may only need incremental updates. Either way, this work forces us to ask: Can software engineering's core assumptions survive the age of autonomous agents?
Success Conditioning as Policy Improvement: The Optimization Problem Solved by Imitating Success
Jan 26, 2026A widely used technique for improving policies is success conditioning, in which one collects trajectories, identifies those that achieve a desired outcome, and updates the policy to imitate the actions taken along successful trajectories. This principle appears under many names -- rejection sampling with SFT, goal-conditioned RL, Decision Transformers -- yet what optimization problem it solves, if any, has remained unclear. We prove that success conditioning exactly solves a trust-region optimization problem, maximizing policy improvement subject to a $χ^2$ divergence constraint whose radius is determined automatically by the data. This yields an identity: relative policy improvement, the magnitude of policy change, and a quantity we call action-influence -- measuring how random variation in action choices affects success rates -- are exactly equal at every state. Success conditioning thus emerges as a conservative improvement operator. Exact success conditioning cannot degrade performance or induce dangerous distribution shift, but when it fails, it does so observably, by hardly changing the policy at all. We apply our theory to the common practice of return thresholding, showing this can amplify improvement, but at the cost of potential misalignment with the true objective.
Contextual Thompson Sampling via Generation of Missing Data
Feb 10, 2025



We introduce a framework for Thompson sampling contextual bandit algorithms, in which the algorithm's ability to quantify uncertainty and make decisions depends on the quality of a generative model that is learned offline. Instead of viewing uncertainty in the environment as arising from unobservable latent parameters, our algorithm treats uncertainty as stemming from missing, but potentially observable, future outcomes. If these future outcomes were all observed, one could simply make decisions using an "oracle" policy fit on the complete dataset. Inspired by this conceptualization, at each decision-time, our algorithm uses a generative model to probabilistically impute missing future outcomes, fits a policy using the imputed complete dataset, and uses that policy to select the next action. We formally show that this algorithm is a generative formulation of Thompson Sampling and prove a state-of-the-art regret bound for it. Notably, our regret bound i) depends on the probabilistic generative model only through the quality of its offline prediction loss, and ii) applies to any method of fitting the "oracle" policy, which easily allows one to adapt Thompson sampling to decision-making settings with fairness and/or resource constraints.
Impatient Bandits: Optimizing for the Long-Term Without Delay
Jan 14, 2025


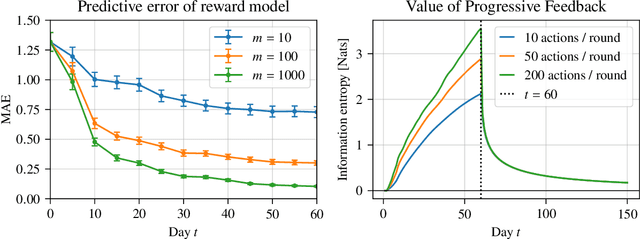
Increasingly, recommender systems are tasked with improving users' long-term satisfaction. In this context, we study a content exploration task, which we formalize as a bandit problem with delayed rewards. There is an apparent trade-off in choosing the learning signal: waiting for the full reward to become available might take several weeks, slowing the rate of learning, whereas using short-term proxy rewards reflects the actual long-term goal only imperfectly. First, we develop a predictive model of delayed rewards that incorporates all information obtained to date. Rewards as well as shorter-term surrogate outcomes are combined through a Bayesian filter to obtain a probabilistic belief. Second, we devise a bandit algorithm that quickly learns to identify content aligned with long-term success using this new predictive model. We prove a regret bound for our algorithm that depends on the \textit{Value of Progressive Feedback}, an information theoretic metric that captures the quality of short-term leading indicators that are observed prior to the long-term reward. We apply our approach to a podcast recommendation problem, where we seek to recommend shows that users engage with repeatedly over two months. We empirically validate that our approach significantly outperforms methods that optimize for short-term proxies or rely solely on delayed rewards, as demonstrated by an A/B test in a recommendation system that serves hundreds of millions of users.
Face the Facts! Evaluating RAG-based Fact-checking Pipelines in Realistic Settings
Dec 19, 2024
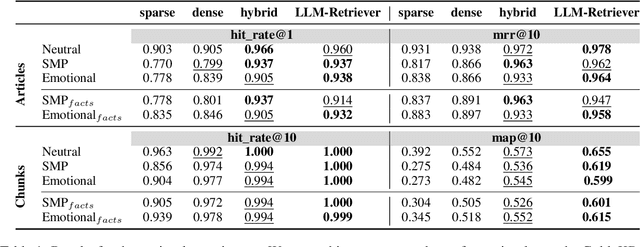
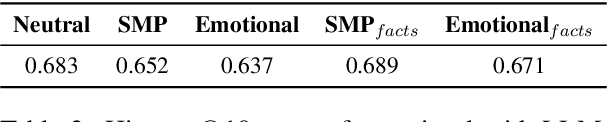

Natural Language Processing and Generation systems have recently shown the potential to complement and streamline the costly and time-consuming job of professional fact-checkers. In this work, we lift several constraints of current state-of-the-art pipelines for automated fact-checking based on the Retrieval-Augmented Generation (RAG) paradigm. Our goal is to benchmark, under more realistic scenarios, RAG-based methods for the generation of verdicts - i.e., short texts discussing the veracity of a claim - evaluating them on stylistically complex claims and heterogeneous, yet reliable, knowledge bases. Our findings show a complex landscape, where, for example, LLM-based retrievers outperform other retrieval techniques, though they still struggle with heterogeneous knowledge bases; larger models excel in verdict faithfulness, while smaller models provide better context adherence, with human evaluations favouring zero-shot and one-shot approaches for informativeness, and fine-tuned models for emotional alignment.
Posterior Sampling via Autoregressive Generation
May 29, 2024
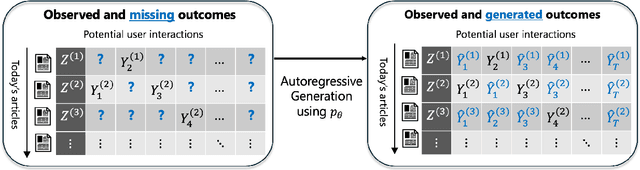
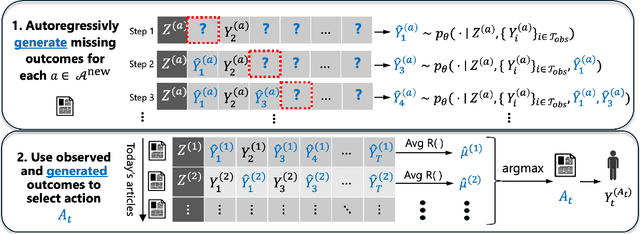
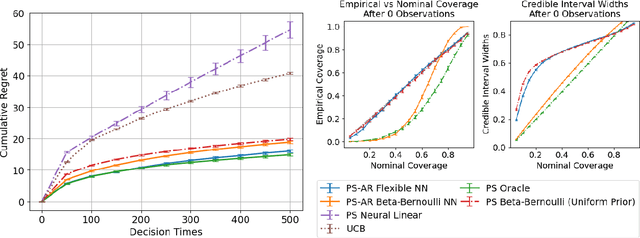
Real-world decision-making requires grappling with a perpetual lack of data as environments change; intelligent agents must comprehend uncertainty and actively gather information to resolve it. We propose a new framework for learning bandit algorithms from massive historical data, which we demonstrate in a cold-start recommendation problem. First, we use historical data to pretrain an autoregressive model to predict a sequence of repeated feedback/rewards (e.g., responses to news articles shown to different users over time). In learning to make accurate predictions, the model implicitly learns an informed prior based on rich action features (e.g., article headlines) and how to sharpen beliefs as more rewards are gathered (e.g., clicks as each article is recommended). At decision-time, we autoregressively sample (impute) an imagined sequence of rewards for each action, and choose the action with the largest average imputed reward. Far from a heuristic, our approach is an implementation of Thompson sampling (with a learned prior), a prominent active exploration algorithm. We prove our pretraining loss directly controls online decision-making performance, and we demonstrate our framework on a news recommendation task where we integrate end-to-end fine-tuning of a pretrained language model to process news article headline text to improve performance.
On the Limited Representational Power of Value Functions and its Links to Statistical (In)Efficiency
Mar 11, 2024



Identifying the trade-offs between model-based and model-free methods is a central question in reinforcement learning. Value-based methods offer substantial computational advantages and are sometimes just as statistically efficient as model-based methods. However, focusing on the core problem of policy evaluation, we show information about the transition dynamics may be impossible to represent in the space of value functions. We explore this through a series of case studies focused on structures that arises in many important problems. In several, there is no information loss and value-based methods are as statistically efficient as model based ones. In other closely-related examples, information loss is severe and value-based methods are severely outperformed. A deeper investigation points to the limitations of the representational power as the driver of the inefficiency, as opposed to failure in algorithm design.
Optimizing Adaptive Experiments: A Unified Approach to Regret Minimization and Best-Arm Identification
Feb 16, 2024Practitioners conducting adaptive experiments often encounter two competing priorities: reducing the cost of experimentation by effectively assigning treatments during the experiment itself, and gathering information swiftly to conclude the experiment and implement a treatment across the population. Currently, the literature is divided, with studies on regret minimization addressing the former priority in isolation, and research on best-arm identification focusing solely on the latter. This paper proposes a unified model that accounts for both within-experiment performance and post-experiment outcomes. We then provide a sharp theory of optimal performance in large populations that unifies canonical results in the literature. This unification also uncovers novel insights. For example, the theory reveals that familiar algorithms, like the recently proposed top-two Thompson sampling algorithm, can be adapted to optimize a broad class of objectives by simply adjusting a single scalar parameter. In addition, the theory reveals that enormous reductions in experiment duration can sometimes be achieved with minimal impact on both within-experiment and post-experiment regret.
Countering Misinformation via Emotional Response Generation
Nov 17, 2023



The proliferation of misinformation on social media platforms (SMPs) poses a significant danger to public health, social cohesion and ultimately democracy. Previous research has shown how social correction can be an effective way to curb misinformation, by engaging directly in a constructive dialogue with users who spread -- often in good faith -- misleading messages. Although professional fact-checkers are crucial to debunking viral claims, they usually do not engage in conversations on social media. Thereby, significant effort has been made to automate the use of fact-checker material in social correction; however, no previous work has tried to integrate it with the style and pragmatics that are commonly employed in social media communication. To fill this gap, we present VerMouth, the first large-scale dataset comprising roughly 12 thousand claim-response pairs (linked to debunking articles), accounting for both SMP-style and basic emotions, two factors which have a significant role in misinformation credibility and spreading. To collect this dataset we used a technique based on an author-reviewer pipeline, which efficiently combines LLMs and human annotators to obtain high-quality data. We also provide comprehensive experiments showing how models trained on our proposed dataset have significant improvements in terms of output quality and generalization capabilities.