 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Sampling via Autoregressive Generation
Paper and Code

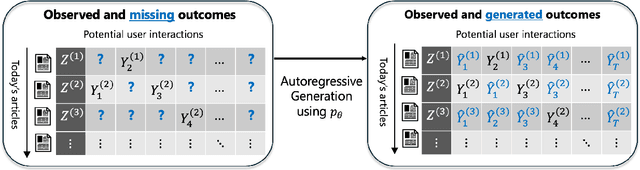
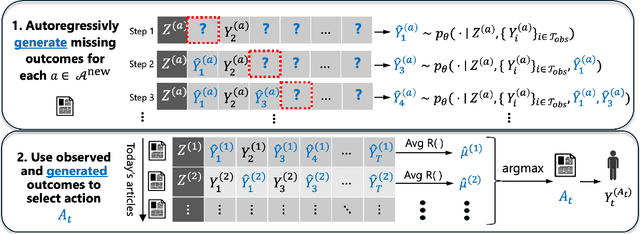
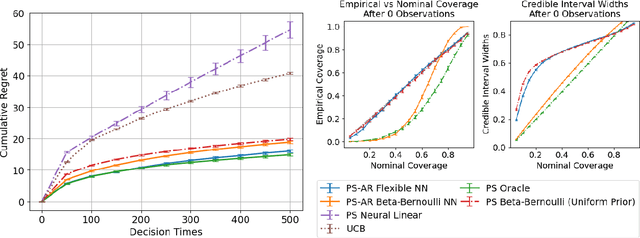
Real-world decision-making requires grappling with a perpetual lack of data as environments change; intelligent agents must comprehend uncertainty and actively gather information to resolve it. We propose a new framework for learning bandit algorithms from massive historical data, which we demonstrate in a cold-start recommendation problem. First, we use historical data to pretrain an autoregressive model to predict a sequence of repeated feedback/rewards (e.g., responses to news articles shown to different users over time). In learning to make accurate predictions, the model implicitly learns an informed prior based on rich action features (e.g., article headlines) and how to sharpen beliefs as more rewards are gathered (e.g., clicks as each article is recommended). At decision-time, we autoregressively sample (impute) an imagined sequence of rewards for each action, and choose the action with the largest average imputed reward. Far from a heuristic, our approach is an implementation of Thompson sampling (with a learned prior), a prominent active exploration algorithm. We prove our pretraining loss directly controls online decision-making performance, and we demonstrate our framework on a news recommendation task where we integrate end-to-end fine-tuning of a pretrained language model to process news article headline text to improve performance.