 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Sampling via Autoregressive Generation
May 29, 2024
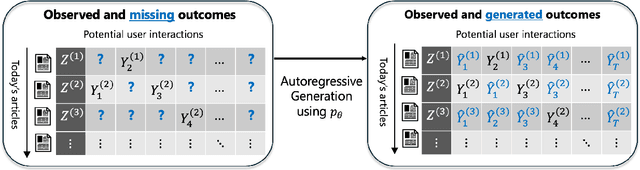
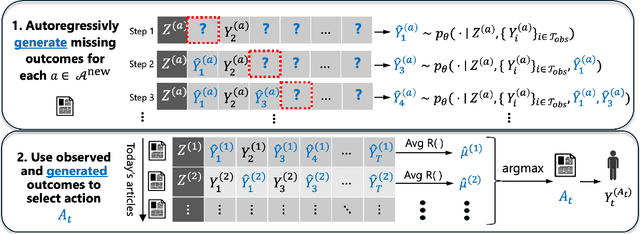
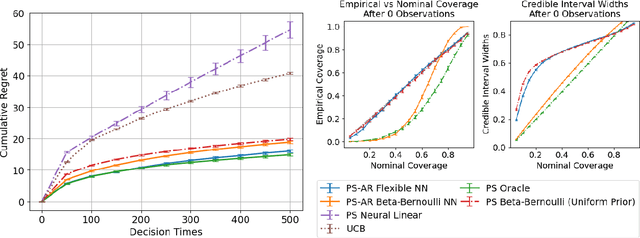
Real-world decision-making requires grappling with a perpetual lack of data as environments change; intelligent agents must comprehend uncertainty and actively gather information to resolve it. We propose a new framework for learning bandit algorithms from massive historical data, which we demonstrate in a cold-start recommendation problem. First, we use historical data to pretrain an autoregressive model to predict a sequence of repeated feedback/rewards (e.g., responses to news articles shown to different users over time). In learning to make accurate predictions, the model implicitly learns an informed prior based on rich action features (e.g., article headlines) and how to sharpen beliefs as more rewards are gathered (e.g., clicks as each article is recommended). At decision-time, we autoregressively sample (impute) an imagined sequence of rewards for each action, and choose the action with the largest average imputed reward. Far from a heuristic, our approach is an implementation of Thompson sampling (with a learned prior), a prominent active exploration algorithm. We prove our pretraining loss directly controls online decision-making performance, and we demonstrate our framework on a news recommendation task where we integrate end-to-end fine-tuning of a pretrained language model to process news article headline text to improve performance.
Statistical Inference After Adaptive Sampling in Non-Markovian Environments
Feb 14, 2022
There is a great desire to use adaptive sampling methods, such as reinforcement learning (RL) and bandit algorithms, for the real-time personalization of interventions in digital applications like mobile health and education. A major obstacle preventing more widespread use of such algorithms in practice is the lack of assurance that the resulting adaptively collected data can be used to reliably answer inferential questions, including questions about time-varying causal effects. Current methods for statistical inference on such data are insufficient because they (a) make strong assumptions regarding the environment dynamics, e.g., assume a contextual bandit or Markovian environment, or (b) require data to be collected with one adaptive sampling algorithm per user, which excludes data collected by algorithms that learn to select actions by pooling the data of multiple users. In this work, we make initial progress by introducing the adaptive sandwich estimator to quantify uncertainty; this estimator (a) is valid even when user rewards and contexts are non-stationary and highly dependent over time, and (b) accommodates settings in which an online adaptive sampling algorithm learns using the data of all users. Furthermore, our inference method is robust to misspecification of the reward models used by the adaptive sampling algorithm. This work is motivated by our work designing experiments in which RL algorithms are used to select actions, yet reliable statistical inference is essential for conducting primary analyses after the trial is over.